


Auteur

14 décembre 2020
Avec l'introduction des permissions opt-in pour les applications, iOS 14 rendra plus difficile pour les marques de cibler les consommateurs à un niveau individuel et de mesurer les résultats des activités de marketing. Bobby Gray, responsable de l'analyse et du marketing Data chez Artefact, examine l'impact et explique comment les marques peuvent réagir en utilisant first-party data.
Introduction
Ce projet fait partie de la contribution de Artefact à Tech for Good. Le projet a été mené en collaboration avec l'Institut Carnot CALYM, un consortium dédié à la recherche partenariale sur le lymphome, et Microsoft.
L'Institut Carnot CALYM a lancé à l'automne 2019 un programme structurant visant à mettre en place une feuille de route pour optimiser la valorisation et l'exploitation du data issu de la recherche clinique, translationnelle et préclinique menée par les membres du consortium depuis plus de 20 ans. Ce projet, proposé par le Pr Camille Laurent (LYSA, IUCT, CHU Toulouse, France) et le Pr Christiane Copie (LYSARC, Pierre-Bénite, France), tous deux membres de l'Institut Carnot CALYM, s'inscrit dans ce programme structurant.
L'objectif principal de ce projet de recherche est de développer un algorithme d'apprentissage profond pour aider les pathologistes à diagnostiquer le lymphome folliculaire. Un objectif secondaire est d'identifier des critères informatifs qui pourraient aider les experts médicaux à comprendre les différences morphologiques entre le lymphome folliculaire et l'hyperplasie folliculaire, qui seront désignés ci-dessous par FL et FH.
Qu'est-ce que le lymphome folliculaire ? Quels sont les défis posés par son diagnostic ?
Le FL est un sous-type de lymphome, le cancer du sang le plus fréquent dans le monde. Il existe plus de 80 types de lymphome et cette diversité rend son diagnostic difficile, même pour les experts. En outre, le FL est très similaire à la FH, qui n'est pas cancéreuse, ce qui complique encore son diagnostic.
Dans cet article, nous décrivons notre approche de la construction d'un classificateur pour le FL et le FH en utilisant uniquement des images de lames entières étiquetées. Les images de lames entières sont des fichiers numériques haute résolution de lames de microscope scannées. Dans notre cas, elles contiennent des extraits de ganglions lymphatiques.
Comment l'apprentissage profond pourrait-il contribuer à sa détection ?
En utilisant des images de FL et de FH en diapositives entières, nous avons entraîné un classificateur binaire par le biais d'une approche basée sur les patchs. L'architecture de notre modèle est un simple Resnet-18 entraîné sur quelques époques (~10).
Après avoir prédit la classe d'une observation avec le classificateur, nous extrayons la dernière couche d'activation pour construire une carte thermique sur l'image d'entrée afin de mettre en évidence les parties qui ont incité le modèle à définir une classe donnée.
Pourquoi avons-nous utilisé une classification basée sur les patchs ?
La classification basée sur les patchs est une technique de classification dans laquelle la classe d'une observation donnée est construite sur la base de l'agrégation des prédictions de ses composants (patchs). Dans notre cas, cette technique est utilisée parce que les images sont beaucoup trop grandes pour être utilisées directement sur le modèle.
En fait, les images de diapositives entières sont très grandes (~10⁵ pixels carrés). Leur taille rend l'entraînement d'un modèle d'apprentissage profond presque impossible avec les outils courants. Pour résoudre ce problème, nous les avons divisées en patchs de même taille en suivant deux critères importants :
Dans la classification basée sur les patchs, les résultats du modèle peuvent être interprétés comme ceux d'une classification classique, sauf que la première couche de calcul se situe au niveau de la diapositive entière. Par exemple, pour prédire la classe d'une diapositive de FL, un score de 98% signifie que 98 % des patchs qui la composent ont été prédits comme étant FL.
Au niveau dataset, cette diapositive sera prédite avec un score de 0,98 pour la classe FL.
PS : Nous avons émis l'hypothèse de diviser les images en patchs en nous basant sur les conclusions d'experts médicaux indiquant que dans une lame entière de FL, les follicules sont censés être présents partout.
Ensemble de formation
Notre ensemble d'entraînement est composé de 58k patchs sélectionnés de manière aléatoire (carré de 1024 pixels) de FL et FH extraites d'un ensemble de 30 images de diapositives entières dans chacune des deux classes.
Ensemble de validation
20% des patchs ont été échantillonnés pour valider les performances du modèle au moment de la formation.
Ensemble de tests
Notre ensemble de test est composé de 15 images de diapositives entières, chacune divisée en patchs. Cet ensemble de référence a été utilisé pour comparer les résultats de différentes approches de formation que nous préciserons ci-dessous.
Modélisation
Notre ensemble de test est composé de 15 images de diapositives entières, chacune divisée en patchs. Cet ensemble de référence a été utilisé pour comparer les résultats de différentes approches de formation que nous préciserons ci-dessous.
Avant d'entraîner le classificateur d'apprentissage profond : Préparation et traitement des images
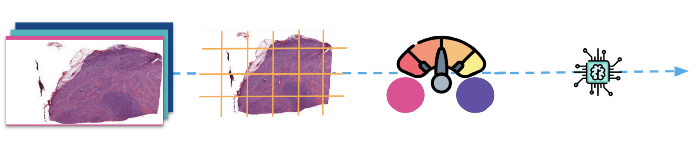
(Ci-dessus : Les images sont d'abord divisées en parcelles, puis normalisées avant d'être transmises au modèle pour l'apprentissage).
Après la formation : Inférence et interprétation
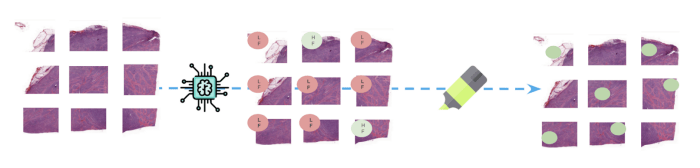
(Ci-dessus : Au moment de l'inférence, les nouvelles diapositives entières sont divisées en parcelles avant que le modèle ne prédise une classe pour les diapositives entières.
chacun d'entre eux. Les parties des images responsables de la prédiction de la classe FL sont mises en évidence pour faciliter le suivi.
les résultats).
Dans les sections ci-dessous, nous donnerons des détails sur ces différentes étapes de la filière.
Data préparation et transformation
1 - Carrelage
Comme indiqué précédemment, les images de diapositives entières sont très volumineuses et ne peuvent pas être directement transmises à un modèle de classification, à moins que vous n'utilisiez un matériel super galactique. Nous avons utilisé la bibliothèque Ouvrir le toboggan pour lire les diapositives et ses deepzoom pour diviser les images en tuiles relativement petites de 1024 pixels de côté. Après les avoir divisées en tuiles, nous les avons passées dans un nettoyeur de base qui a éliminé toutes les tuiles qui n'étaient pas au centre du tissu (bordures, trous, etc.).

2 - Normalisation des taches
La deuxième étape de notre traitement data, qui est aussi l'étape la plus importante, est la normalisation de la couleur de la coloration. La coloration est le processus qui consiste à mettre en évidence les éléments importants sur les diapositives et à renforcer le contraste entre eux. Le système de coloration utilisé est le système commun H&E (Hématoxyline et éosine).
Cependant, comme les images proviennent de nombreux laboratoires différents, nous avons observé des variations dans la coloration des diapositives. Ces variations sont principalement dues à des différences dans le processus de teinture d'un laboratoire à l'autre. Ces différences peuvent affecter considérablement les performances du modèle.
Nous avons utilisé des techniques classiques pour normaliser la coloration de l'ensemble data avant d'entraîner le modèle.
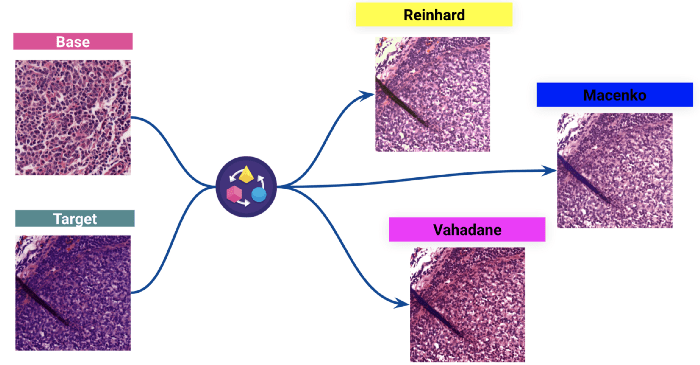
(Ci-dessus : Résultats de trois normalisations de taches différentes : la coloration d'une image cible est normalisée par rapport à la distribution des couleurs d'une image de base).
Nous avons choisi le Reinhard pour voir l'impact sur le modèle.
Formation d'un classificateur Resnet-18
Après avoir traité les images des diapositives entières, l'entraînement s'est déroulé sans problème (dropout, weight decay, etc.). Rien d'extraordinaire, si ce n'est l'ajout d'une confusion dans l'augmentation data. Nous avons utilisé un Resnet18 formés à partir de zéro, car les modèles préformés n'amélioraient pas nos résultats de manière significative. Nous avons également préféré le Resnet-18 car les Resnet-34 et Resnet-56 n'amélioraient pas nos performances. Après ~10 époques, notre modèle était prêt à être testé.
Nous avons utilisé le très pratique Fastai pour construire nos modèles avec peu d'efforts.
Essais
Les résultats de trois expériences méritent d'être mentionnés :
Les résultats sur l'ensemble de tests pour ces 3 expérimentations sont présentés ci-dessous :
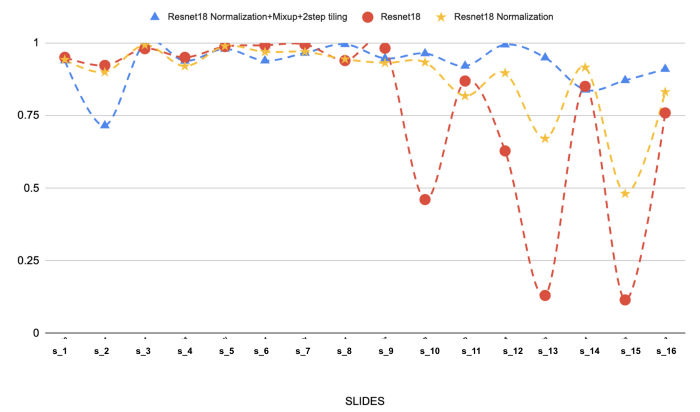
(Ci-dessus : Les résultats de 3 modèles différents sur les 16 lames sélectionnées de lymphome folliculaire. On peut voir l'effet de la normalisation et de la confusion des taches sur les performances).
La normalisation des taches est de loin l'étape la plus importante de notre approche de modélisation. Nous rencontrions des problèmes de généralisation (ligne rouge), mais la normalisation nous a définitivement aidés à résoudre le problème. L'ajout d'un mélange et d'un carrelage en deux étapes améliore encore la situation.
MixUp est une technique d'augmentation data qui consiste à créer de nouvelles observations en interpolant linéairement de nombreux échantillons.
Interpréter les résultats d'un classificateur de vision par ordinateur
Afin de communiquer facilement les résultats aux experts médicaux, nous avons fourni des images avec des cartes thermiques pour mettre en évidence l'orientation du modèle lors de la prédiction d'une étiquette donnée. Pour ce faire, nous avons extrait la dernière couche d'activation du réseau convolutionnel et l'avons extrapolée linéairement sur l'image sur laquelle nous prédisions.
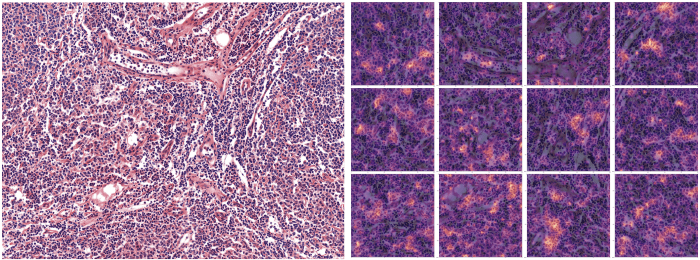
(Ci-dessus : Les parties de l'image qui ont le plus contribué à la prédiction de la classe Lymphome folliculaire sont mises en évidence sur l'image de droite - 12 patchs)).
L'interprétation des résultats du modèle à l'aide de cartes thermiques s'est avérée très utile pour ajuster l'approche de modélisation, car elle permet aux experts d'analyser ce que fait réellement le modèle. Grâce à nos échanges avec les experts, nous (les scientifiques de data) avons pu ajuster notre façon de mieux gérer l'ensemble data et rendre le modèle plus robuste (c'est-à-dire capable de s'adapter à différents types d'entrées). Et aussi de s'assurer qu'il remplit bien sa fonction. C'est ainsi que nous avons réalisé la nécessité de normaliser la coloration des images.
Conclusion et enseignements clés
L'objectif de cette étude était d'explorer le processus de création d'un bon classificateur de base d'apprentissage profond pour différencier le lymphome folliculaire et l'hyperplasie folliculaire. Nos principaux enseignements sont énumérés ci-dessous :
