


Autor

14 de dezembro de 2020
Com a introdução de permissões de opt-in para aplicativos, o iOS 14 tornará mais difícil para as marcas atingir os consumidores em um nível individual e medir os resultados das atividades de marketing. Bobby Gray, diretor de análise e marketing Data da Artefact, analisa o impacto e explica como as marcas podem reagir usando o first-party data.
Introdução
Esse projeto faz parte da contribuição da Artefact na Tech for Good. O projeto foi realizado em colaboração com o Institut Carnot CALYM, um consórcio dedicado à pesquisa em parceria sobre linfoma, e a Microsoft.
No outono de 2019, o Institut Carnot CALYM lançou um programa de estruturação com o objetivo de estabelecer um roteiro para otimizar a valorização e a exploração do data a partir da pesquisa clínica, translacional e pré-clínica realizada pelos membros do consórcio por mais de 20 anos. Esse projeto, proposto pelo Pr Camille Laurent (LYSA, IUCT, CHU Toulouse, França) e Pr Christiane Copie (LYSARC, Pierre-Bénite, França), ambos membros do Institut Carnot CALYM, faz parte desse programa de estruturação.
O objetivo principal deste projeto de pesquisa é desenvolver um algoritmo de aprendizagem profunda para auxiliar os patologistas no diagnóstico do linfoma folicular. Um objetivo secundário é identificar critérios informativos que possam ajudar os médicos especialistas a entender as diferenças morfológicas entre o linfoma folicular e a hiperplasia folicular, que serão referidos a seguir como FL e FH.
O que é o linfoma folicular? Quais são os desafios em seu diagnóstico?
A FL é um subtipo de linfoma, o câncer de sangue mais frequente no mundo. Existem mais de 80 tipos de linfoma e essa diversidade dificulta seu diagnóstico, mesmo para os especialistas. Além disso, a FL é muito semelhante à FH, que não é cancerígena, o que aumenta os desafios ao seu diagnóstico.
Neste artigo, descreveremos nossa abordagem na criação de um classificador para FL e FH usando apenas imagens de lâminas inteiras rotuladas. As imagens de lâminas inteiras são arquivos digitais de alta resolução de lâminas de microscópio digitalizadas. Em nosso caso, elas contêm extratos de linfonodos.
Como a aprendizagem profunda poderia ajudar na sua detecção?
Usando imagens de slides inteiros de FL e FH, treinamos um classificador binário por meio de uma abordagem baseada em patches. Nossa arquitetura de modelo é um Resnet-18 simples treinado em poucas épocas (~10).
Depois de prever a classe de uma observação com o classificador, extraímos a última camada de ativação para criar um mapa de calor na parte superior da imagem de entrada para destacar as partes que levaram o modelo a definir uma determinada classe.
Por que usamos uma classificação baseada em patches?
A classificação baseada em patches é uma técnica de classificação em que a classe de uma determinada observação é construída com base na agregação das previsões de seus componentes (patches). Em nosso caso, ela é usada porque as imagens são muito grandes para serem usadas diretamente no modelo.
Na verdade, as imagens de slides inteiros são muito grandes (~10⁵ pixels quadrados). Seu tamanho torna o treinamento de um modelo de aprendizagem profunda quase impossível com ferramentas comuns. Para resolver esse problema, nós as dividimos em patches do mesmo tamanho seguindo dois critérios importantes:
Na classificação baseada em patches, a saída do modelo pode ser interpretada como a de uma classificação clássica, exceto pelo fato de que a primeira camada de cálculo está no nível do slide inteiro. Por exemplo, ao prever a classe de um slide de FL, uma pontuação de 98% significaria que 98 % dos patches que o compõem foram previstos como FL.
No nível dataset, esse slide será previsto com uma pontuação de 0,98 para a classe FL.
PS: Fizemos a hipótese de dividir as imagens em manchas com base nas conclusões de especialistas médicos que afirmam que, em uma lâmina inteira de FL, espera-se que os folículos estejam presentes em todos os lugares.
Conjunto de treinamento
Nosso conjunto de treinamento é composto de 58 mil patches selecionados aleatoriamente (quadrado de 1024 pixels) de FL e FH extraídos de um conjunto de 30 imagens de slides inteiros em cada uma das duas classes.
Conjunto de validação
20% dos patches foram amostrados para validar o desempenho do modelo no momento do treinamento.
Conjunto de teste
Nosso conjunto de testes é composto de 15 imagens de slides inteiros, cada uma dividida em patches. Esse conjunto de referência foi usado para comparar os resultados de diferentes abordagens de treinamento que precisaremos a seguir.
Modelagem
Nosso conjunto de testes é composto de 15 imagens de slides inteiros, cada uma dividida em patches. Esse conjunto de referência foi usado para comparar os resultados de diferentes abordagens de treinamento que precisaremos a seguir.
Antes de treinar o classificador de aprendizagem profunda: Preparação e processamento de imagens
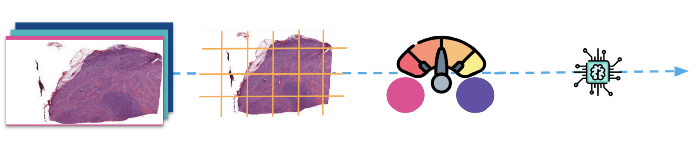
(Acima: As imagens são primeiramente divididas em manchas e, em seguida, normalizadas antes de serem fornecidas ao modelo para treinamento).
Após o treinamento: Inferência e interpretação
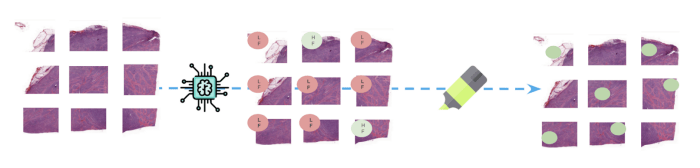
(Acima: No momento da inferência, os novos slides inteiros são divididos em patches antes que o modelo preveja uma classe para
cada uma delas. As partes das imagens responsáveis pela previsão da classe FL são destacadas para ajudar no monitoramento
os resultados).
Nas seções abaixo, daremos detalhes sobre essas diferentes etapas do pipeline.
Data preparação e processamento
1 - Ladrilho
Como dito anteriormente, as imagens de slides inteiros são muito grandes e não podem ser inseridas diretamente em um modelo de classificação, a menos que o senhor esteja usando um hardware supergaláctico. Usamos a biblioteca guia aberto para ler os slides e seus deepzoom para dividir as imagens em blocos relativamente pequenos de 1024 pixels quadrados. Depois de dividi-las em blocos, passamos por um limpador básico que descartou todos os blocos que não estavam no centro do tecido (bordas, buracos etc.).

2 - Normalização de manchas
A segunda etapa do nosso processamento do data, que também é a mais importante, é a normalização da cor da mancha. A coloração é o processo de destacar recursos importantes em lâminas e aprimorar o contraste entre eles. O sistema de coloração usado é o comum H&E (Hematoxilina e Eosina).
Entretanto, como as imagens são provenientes de muitos laboratórios diferentes, observamos variações na coloração das lâminas. Elas se devem principalmente às diferenças no processo de tingimento de um laboratório para outro. Essas diferenças podem afetar muito o desempenho do modelo.
Usamos técnicas clássicas para normalizar a coloração do dataset antes de treinar o modelo.
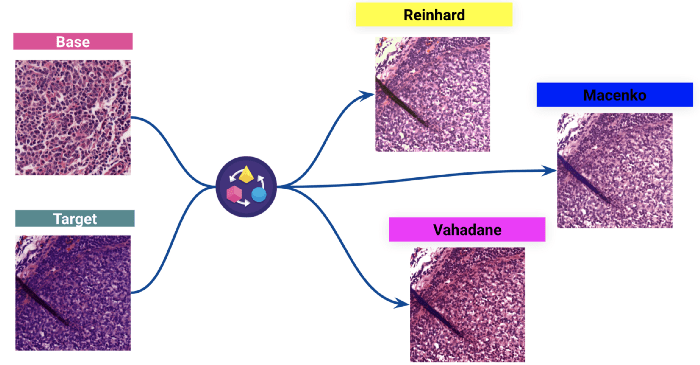
(Acima: Resultados de três diferentes normalizações de manchas: a coloração de uma imagem-alvo é normalizada para uma distribuição de cores da imagem de base).
Escolhemos o Reinhard para ver o impacto no modelo.
Treinamento de um classificador Resnet-18
Depois de processar as imagens de slides inteiros, o treinamento ocorreu sem problemas (desistência, decaimento de peso etc.). Nada extravagante, exceto pelo acréscimo de confusão no aumento do data. Usamos um Resnet18 treinados do zero, pois os modelos pré-treinados não estavam melhorando significativamente nossos resultados. Também preferimos o Resnet-18, pois o Resnet-34 e o Resnet-56 não estavam melhorando nosso desempenho. Depois de aproximadamente 10 épocas, nosso modelo estava pronto para ser testado.
Usamos o muito prático Fastai para criar nossos modelos com pouco esforço.
Testes
Vale a pena mencionar os resultados de 3 experimentos:
Os resultados no conjunto de teste para essas três experiências são mostrados abaixo:
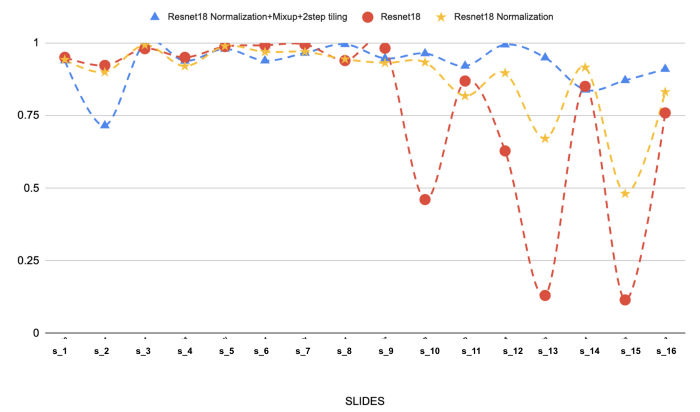
(Acima: Os resultados de 3 modelos diferentes nas 16 lâminas selecionadas de linfoma folicular. Podemos ver o efeito da normalização e da mistura de manchas no desempenho).
A normalização de manchas é, de longe, a etapa mais importante em nossa abordagem de modelagem. Estávamos enfrentando problemas de generalização (linha vermelha), mas ela definitivamente ajudou a resolver o problema. Acrescentar a mistura e um mosaico de duas etapas torna tudo ainda melhor.
MixUp é uma técnica de aumento de data que consiste em criar novas observações interpolando linearmente muitas amostras.
Interpretação dos resultados de um classificador de visão computacional
Para comunicar facilmente os resultados aos médicos especialistas, fornecemos imagens com mapas de calor para destacar onde estava o foco do modelo ao prever um determinado rótulo. Fizemos isso extraindo a última camada de ativação da rede convolucional e extrapolando-a linearmente na imagem para a qual estávamos fazendo a previsão.
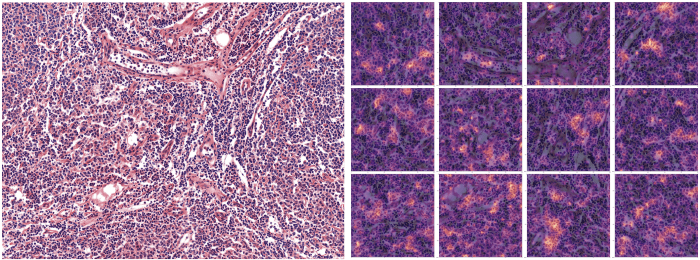
(Acima: As partes da imagem que mais contribuíram para a previsão da classe Follicular Lymphoma estão destacadas na imagem do lado direito - 12 patches)).
A interpretação do resultado do modelo com mapas de calor foi muito útil para ajustar a abordagem de modelagem, pois oferece aos especialistas maneiras de analisar o que o modelo está realmente fazendo. Por meio de nossos intercâmbios com especialistas, nós (cientistas do data) conseguimos ajustar a forma de lidar melhor com o conjunto data e tornar o modelo mais robusto (ou seja, capaz de se adaptar a diferentes tipos de dados). E também para garantir que ele atenda a seu propósito. Na verdade, foi assim que percebemos a necessidade de normalizar a coloração das imagens.
Conclusão e principais aprendizados
O objetivo deste estudo foi explorar o processo de criação de um bom classificador de base de aprendizagem profunda para diferenciar o linfoma folicular e a hiperplasia folicular. Nossos principais aprendizados estão listados abaixo:
