


Autor

14. Dezember 2020
Mit der Einführung von Opt-in-Berechtigungen für Apps wird es für Marken mit iOS 14 schwieriger, Verbraucher auf einer individuellen Ebene anzusprechen und die Ergebnisse von Marketingaktivitäten zu messen. Bobby Gray, Head of Analytics and Data Marketing bei Artefact, betrachtet die Auswirkungen und erklärt, wie Marken mit first-party data reagieren können.
Einführung
Dieses Projekt ist Teil des Beitrags von Artefact zu Tech for Good. Das Projekt wurde in Zusammenarbeit mit dem Institut Carnot CALYM, einem Konsortium, das sich der partnerschaftlichen Forschung über Lymphome widmet, und Microsoft durchgeführt.
Im Herbst 2019 hat das Institut Carnot CALYM ein Strukturierungsprogramm gestartet, das darauf abzielt, einen Fahrplan zur Optimierung der Verwertung und Nutzung von data aus der klinischen, translationalen und präklinischen Forschung zu erstellen, die von den Mitgliedern des Konsortiums seit mehr als 20 Jahren durchgeführt wird. Dieses Projekt, das von Pr Camille Laurent (LYSA, IUCT, CHU Toulouse, Frankreich) und Pr Christiane Copie (LYSARC, Pierre-Bénite, Frankreich), beide Mitglieder des Institut Carnot CALYM, vorgeschlagen wurde, ist Teil dieses Strukturierungsprogramms.
Das primäre Ziel dieses Forschungsprojekts ist die Entwicklung eines Deep-Learning-Algorithmus, der Pathologen bei der Diagnose von follikulären Lymphomen unterstützt. Ein sekundäres Ziel ist es, aussagekräftige Kriterien zu identifizieren, die medizinischen Experten helfen könnten, die morphologischen Unterschiede zwischen dem Follikulären Lymphom und der Follikulären Hyperplasie zu verstehen, die im Folgenden als FL und FH bezeichnet werden.
Was ist ein follikuläres Lymphom? Was sind die Herausforderungen bei der Diagnose?
FL ist eine Unterart des Lymphoms, des häufigsten Blutkrebses der Welt. Es gibt mehr als 80 Arten von Lymphomen und diese Vielfalt macht die Diagnose selbst für Experten schwierig. Außerdem ist FL der FH, die nicht krebsartig ist, sehr ähnlich, was die Diagnose zusätzlich erschwert.
In diesem Artikel beschreiben wir unseren Ansatz zur Erstellung eines Klassifikators für FL und FH, der nur markierte Ganz-Objektträger-Bilder verwendet. Whole-Slide-Bilder sind hochauflösende digitale Dateien von gescannten Mikroskop-Objektträgern. In unserem Fall enthalten sie Extrakte von Lymphknoten.
Wie könnte Deep Learning bei der Erkennung helfen?
Anhand von Ganzseitenbildern von FL und FH haben wir einen binären Klassifikator mit einem patch-basierten Ansatz trainiert. Unsere Modellarchitektur ist ein einfaches Resnet-18, das mit wenigen Epochen (~10) trainiert wurde.
Nachdem wir die Klasse einer Beobachtung mit dem Klassifikator vorhergesagt haben, extrahieren wir die letzte Aktivierungsschicht, um eine Heatmap über dem Eingabebild zu erstellen und die Teile hervorzuheben, die das Modell dazu veranlasst haben, eine bestimmte Klasse zu definieren.
Warum haben wir eine patchbasierte Klassifizierung verwendet?
Die Patch-basierte Klassifizierung ist eine Klassifizierungstechnik, bei der die Klasse einer gegebenen Beobachtung auf der Grundlage der Aggregation der Vorhersagen ihrer Komponenten (Patches) erstellt wird. In unserem Fall wird sie verwendet, weil die Bilder viel zu groß sind, um sie direkt für das Modell zu verwenden.
In der Tat sind Ganzdia-Bilder sehr groß (~10⁵ Pixel im Quadrat). Ihre Größe macht das Trainieren eines Deep Learning-Modells mit herkömmlichen Tools fast unmöglich. Um dieses Problem zu lösen, haben wir sie nach zwei wichtigen Kriterien in gleich große Bereiche unterteilt:
Bei der patchbasierten Klassifizierung kann das Ergebnis des Modells wie das einer klassischen Klassifizierung interpretiert werden, mit dem Unterschied, dass die erste Berechnungsebene auf der Ebene des gesamten Dias liegt. Bei der Vorhersage der Klasse eines Dias von FL würde eine Punktzahl von 98% beispielsweise bedeuten, dass 98 % der Flecken, aus denen es besteht, als FL vorhergesagt worden sind.
Auf der Ebene dataset wird diese Folie mit einem Wert von 0,98 für die Klasse FL vorhergesagt.
PS: Wir haben die Hypothese aufgestellt, dass die Bilder in Flecken unterteilt sind, weil medizinische Experten zu dem Schluss gekommen sind, dass in einem ganzen Dia von FL die Follikel überall vorhanden sein sollten.
Trainingsset
Unser Trainingssatz besteht aus 58k zufällig ausgewählten Patches (1024 Pixel im Quadrat) von FL und FH, die aus einem Satz von 30 Ganzseitenbildern in jeder der 2 Klassen extrahiert wurden.
Validierungsset
20% der Patches wurden für die Validierung der Modellleistung zum Zeitpunkt des Trainings abgetastet.
Testsatz
Unser Testsatz besteht aus 15 Bildern, die jeweils in Bereiche unterteilt sind. Dieser Referenzsatz wurde verwendet, um die Ergebnisse der verschiedenen Trainingsansätze zu vergleichen, die wir im Folgenden genauer beschreiben.
Modellierung
Unser Testsatz besteht aus 15 Bildern, die jeweils in Bereiche unterteilt sind. Dieser Referenzsatz wurde verwendet, um die Ergebnisse der verschiedenen Trainingsansätze zu vergleichen, die wir im Folgenden genauer beschreiben.
Vor dem Training des Deep Learning-Klassifikators: Bildvorbereitung und -verarbeitung
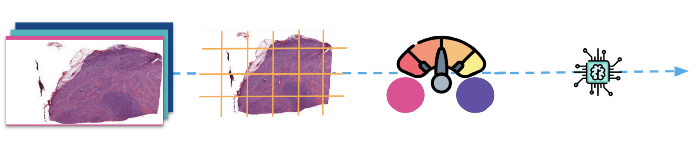
(Oben: Die Bilder werden zunächst in Flecken unterteilt und dann normalisiert, bevor sie dem Modell zum Training zugeführt werden).
Nach dem Training: Inferenz und Interpretation
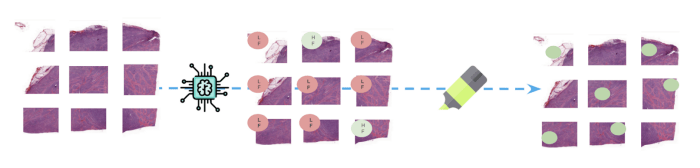
(Oben: Zum Zeitpunkt der Inferenz werden neue Ganzseiten in Patches unterteilt, bevor das Modell eine Klasse für
jedes einzelne von ihnen. Teile der Bilder, die für die Vorhersage der FL-Klasse verantwortlich sind, werden hervorgehoben, um die Überwachung zu erleichtern
die Ergebnisse.)
In den folgenden Abschnitten werden wir diese verschiedenen Schritte der Pipeline im Detail erläutern.
Data Vorbereitung und Verarbeitung
1 - Kacheln
Wie bereits erwähnt, sind Ganzseitenbilder sehr groß und können nicht direkt in ein Klassifizierungsmodell eingespeist werden, es sei denn, Sie verwenden eine supergalaktische Hardware. Wir haben die Bibliothek openslide zum Lesen der Folien und seiner deepzoom Unterstützung, um die Bilder in relativ kleine Kacheln der Größe 1024 Pixel im Quadrat zu unterteilen. Nachdem wir die Bilder in Kacheln zerlegt hatten, ließen wir sie durch einen einfachen Cleaner laufen, der alle Kacheln ausschloss, die sich nicht in der Mitte des Gewebes befanden (Ränder, Löcher usw.).

2 - Flecken-Normalisierung
Der zweite Schritt unserer data-Verarbeitung, der auch der wichtigste Schritt ist, ist die Farbnormalisierung der Färbung. Beim Färben werden wichtige Merkmale auf den Objektträgern hervorgehoben und der Kontrast zwischen ihnen verstärkt. Das verwendete Färbesystem ist das gängige H&E (Hämatoxylin und Eosin).
Da die Bilder jedoch aus vielen verschiedenen Labors stammen, haben wir Abweichungen in der Färbung der Objektträger beobachtet. Sie rühren hauptsächlich von Unterschieden im Färbeprozess von einem Labor zum anderen her. Diese Unterschiede können die Leistung des Modells stark beeinträchtigen.
Wir haben klassische Techniken verwendet, um die Färbung des data-Sets vor dem Training des Modells zu normalisieren.
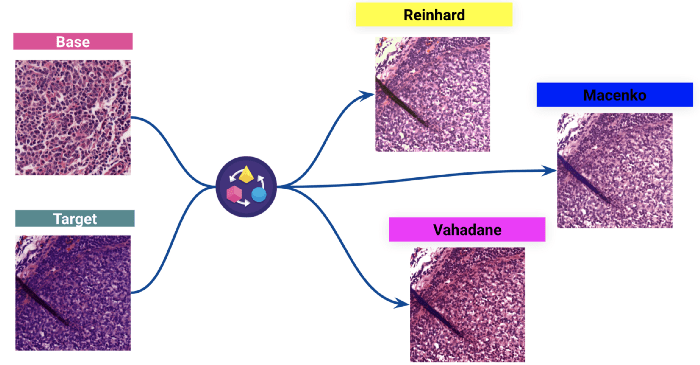
(Oben: Ergebnisse von drei verschiedenen Fleckennormalisierungen: eine Zielbildfärbung wird auf eine Basisbildfarbverteilung normalisiert).
Wir haben die Reinhard Technik, um die Auswirkungen auf das Modell zu sehen.
Training eines Resnet-18 Klassifikators
Nach der Verarbeitung der Ganzdia-Bilder verlief das Training reibungslos (Dropout, Gewichtsabnahme usw.). Nichts Ausgefallenes, außer dass wir die data-Erweiterung durcheinander gebracht haben. Wir haben eine Resnet18 von Grund auf neu trainiert, da die vortrainierten Modelle unsere Ergebnisse nicht signifikant verbessert haben. Wir bevorzugten auch das Resnet-18, da das Resnet-34 und das Resnet-56 unsere Leistungen nicht verbesserten. Nach ~10 Epochen war unser Modell bereit zum Testen.
Wir haben das sehr praktische Fastai Bibliothek, um unsere Modelle mit wenig Aufwand zu erstellen.
Testen Sie
Die Ergebnisse von 3 Experimenten sind es wert, erwähnt zu werden:
Die Ergebnisse dieser 3 Experimente auf dem Testset sind unten aufgeführt:
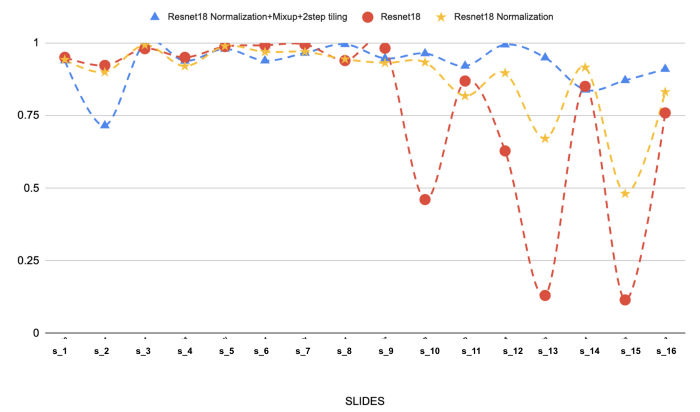
(Oben: Die Ergebnisse von 3 verschiedenen Modellen bei den 16 ausgewählten Objektträgern des follikulären Lymphoms. Wir sehen, wie sich die Normalisierung der Färbung und die Verwechslung auf die Leistung auswirken).
Die Fleckennormalisierung ist bei weitem der wichtigste Schritt in unserem Modellierungsansatz. Wir hatten Probleme mit der Generalisierung (rote Linie), aber sie hat uns definitiv geholfen, das Problem zu lösen. Durch das Hinzufügen von Verwechslungen und einer 2-stufigen Kachelung wird es noch besser.
MixUp ist eine data-Augmentationstechnik, die darin besteht, neue Beobachtungen durch lineare Interpolation vieler Stichproben zu erzeugen.
Interpretation der Ergebnisse eines Computer Vision Klassifikators
Um den medizinischen Experten die Ergebnisse leicht vermitteln zu können, haben wir Bilder mit Heatmaps versehen, um zu verdeutlichen, worauf sich das Modell bei der Vorhersage einer bestimmten Bezeichnung konzentriert hat. Dazu extrahierten wir die letzte Aktivierungsschicht des Faltungsnetzwerks und extrapolierten sie linear auf das Bild, auf das wir die Vorhersage gemacht haben.
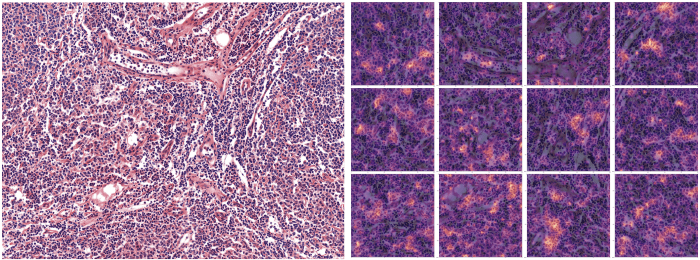
(Oben: Teile des Bildes, die am meisten zur Vorhersage der Klasse Follikuläres Lymphom beigetragen haben, sind auf der rechten Seite des Bildes hervorgehoben - 12 Flecken)).
Die Interpretation der Ausgabe des Modells mit Heatmaps war sehr nützlich für die Anpassung des Modellierungsansatzes, da sie den Experten die Möglichkeit gibt zu analysieren, was das Modell tatsächlich tut. Durch den Austausch mit den Experten konnten wir (die data-Wissenschaftler) den Umgang mit dem data-Set verbessern und das Modell robuster machen (d.h. es an verschiedene Arten von Inputs anpassen). Und auch um sicherzustellen, dass es seinen Zweck erfüllt. Auf diese Weise erkannten wir die Notwendigkeit, die Färbung der Bilder zu normalisieren.
Schlussfolgerung und wichtige Lehren
Ziel dieser Studie war es, den Prozess der Erstellung eines guten Klassifikators auf der Basis von Deep Learning zur Unterscheidung von follikulärem Lymphom und follikulärer Hyperplasie zu untersuchen. Unsere wichtigsten Erkenntnisse sind unten aufgeführt:
