


Autor

14 de diciembre de 2020
Con la introducción de los permisos opt-in para las aplicaciones, iOS 14 hará más difícil para las marcas dirigirse a los consumidores a nivel individual y medir los resultados de las actividades de marketing. Bobby Gray, Jefe de Análisis y Marketing de Data en Artefact, considera el impacto y explica cómo pueden responder las marcas utilizando first-party data.
Introducción
Este proyecto forma parte de la contribución de Artefact en Tech for Good. El proyecto se ha llevado a cabo en colaboración con el Instituto Carnot CALYM, un consorcio dedicado a la investigación en asociación sobre el linfoma, y Microsoft.
En otoño de 2019, el Institut Carnot CALYM lanzó un programa de estructuración destinado a establecer una hoja de ruta para optimizar la valorización y la explotación del data a partir de la investigación clínica, traslacional y preclínica llevada a cabo por los miembros del consorcio desde hace más de 20 años. Este proyecto, propuesto por el Pr Camille Laurent (LYSA, IUCT, CHU Toulouse, Francia) y la Pr Christiane Copie (LYSARC, Pierre-Bénite, Francia), ambos miembros del Institut Carnot CALYM, forma parte de este programa de estructuración.
El objetivo principal de este proyecto de investigación es desarrollar un algoritmo de aprendizaje profundo para ayudar a los patólogos a diagnosticar el linfoma folicular. Un objetivo secundario es identificar criterios informativos que puedan ayudar a los expertos médicos a comprender las diferencias morfológicas entre el linfoma folicular y la hiperplasia folicular, a los que nos referiremos a continuación como FL y FH.
¿Qué es el linfoma folicular? ¿Cuáles son los retos en su diagnóstico?
El FL es un subtipo de Linfoma, el cáncer de la sangre más frecuente en el mundo. Existen más de 80 tipos de linfoma y esta diversidad dificulta su diagnóstico, incluso para los expertos. Además, el FL es muy similar al FH, que no es canceroso, lo que añade dificultades a su diagnóstico.
En este artículo describiremos nuestro enfoque en la construcción de un clasificador para FL y FH utilizando únicamente imágenes de portaobjetos enteros etiquetadas. Las imágenes de portaobjetos completos son archivos digitales de alta resolución de portaobjetos de microscopio escaneados. En nuestro caso contienen extractos de ganglios linfáticos.
¿Cómo podría ayudar el aprendizaje profundo en su detección?
Utilizando imágenes de diapositivas completas de FL y FH, entrenamos un clasificador binario mediante un enfoque basado en parches. La arquitectura de nuestro modelo es una simple Resnet-18 entrenada en unas pocas épocas (~10).
Tras predecir la clase de una observación con el clasificador, extraemos la última capa de activación para construir un mapa de calor sobre la imagen de entrada para resaltar las partes que han incitado al modelo a definir una clase determinada.
¿Por qué utilizamos una clasificación basada en parches?
La clasificación basada en parches es una técnica de clasificación en la que la clase de una observación dada se construye a partir de la agregación de las predicciones de sus componentes (parches). En nuestro caso se utiliza porque las imágenes son demasiado grandes para utilizarlas directamente en el modelo.
De hecho, las imágenes de diapositivas completas son muy grandes (~10⁵ píxeles cuadrados). Su tamaño hace que el entrenamiento de un modelo de aprendizaje profundo sea casi imposible con las herramientas habituales. Para resolver este problema, las dividimos en parches del mismo tamaño siguiendo dos criterios importantes:
En la clasificación basada en parches, el resultado del modelo puede interpretarse como el de una clasificación clásica, salvo que la primera capa de cálculo es a nivel de todo el tobogán. Por ejemplo, al predecir la clase de una diapositiva de FL, una puntuación de 98% significaría que se ha predicho que 98 % de los parches que la componen son FL.
En el nivel dataset, esta diapositiva se predecirá con una puntuación de 0,98 para la clase FL.
PD: Hicimos la hipótesis de dividir las imágenes en parches basándonos en las conclusiones de los expertos médicos que afirman que en una diapositiva completa de FL, se espera que los folículos estén presentes en todas partes.
Conjunto de entrenamiento
Nuestro conjunto de entrenamiento se compone de 58k parches seleccionados al azar (cuadrado de 1024 píxeles) de FL y FH extraídas de un conjunto de 30 imágenes de diapositivas enteras de cada una de las 2 clases.
Conjunto de validación
Se tomaron muestras de 20% de los parches para validar el rendimiento del modelo en el momento del entrenamiento.
Conjunto de pruebas
Nuestro conjunto de pruebas se compone de 15 imágenes de diapositivas enteras, cada una dividida en parches. Este conjunto de referencia se ha utilizado para comparar los resultados de distintos enfoques de entrenamiento que precisaremos a continuación.
Modelado
Nuestro conjunto de pruebas se compone de 15 imágenes de diapositivas enteras, cada una dividida en parches. Este conjunto de referencia se ha utilizado para comparar los resultados de distintos enfoques de entrenamiento que precisaremos a continuación.
Antes de entrenar el clasificador de aprendizaje profundo Preparación y procesamiento de imágenes
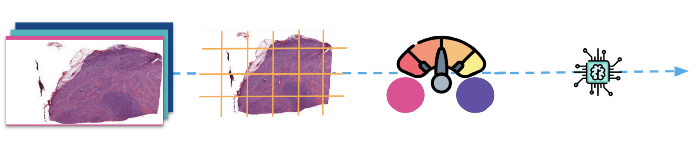
(Arriba: Las imágenes se dividen primero en parches y luego se normalizan antes de introducirlas en el modelo para su entrenamiento).
Después de la formación: Inferencia e interpretación
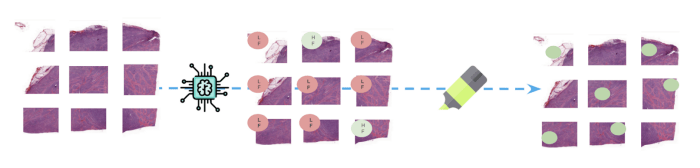
(Arriba: En el momento de la inferencia, las nuevas diapositivas enteras se dividen en parches antes de que el modelo prediga una clase para
cada una de ellas. Las partes de las imágenes responsables de la predicción de la clase FL están resaltadas para ayudar al seguimiento
los resultados).
En las secciones siguientes, daremos los detalles sobre estos diferentes pasos de la canalización.
Data preparación y procesamiento
1 - Alicatado
Como ya se ha dicho, las imágenes de diapositivas enteras son muy grandes y no se pueden alimentar directamente a un modelo de clasificación a menos que se utilice un hardware supergaláctico. Utilizamos la biblioteca openslide para leer las diapositivas y su deepzoom para dividir las imágenes en azulejos relativamente pequeños de un tamaño de 1024 píxeles cuadrados. Tras dividirlas en mosaicos, las pasamos por un limpiador básico que descartó todos los mosaicos que no estaban en el centro del tejido (bordes, agujeros, etc.).

2 - Normalización de las manchas
El segundo paso de nuestro procesamiento data, que es también el más importante, es la normalización del color de la tinción. La tinción es el proceso de resaltar los rasgos importantes de los portaobjetos y realzar el contraste entre ellos. El sistema de tinción utilizado es el común H&E (Hematoxilina y eosina).
Sin embargo, como las imágenes proceden de muchos laboratorios diferentes, hemos observado variaciones en la coloración de las láminas. Provienen principalmente de las diferencias en el proceso de teñido de un laboratorio a otro. Estas diferencias pueden afectar mucho al rendimiento del modelo.
Utilizamos técnicas clásicas para normalizar la coloración del conjunto data antes de entrenar el modelo.
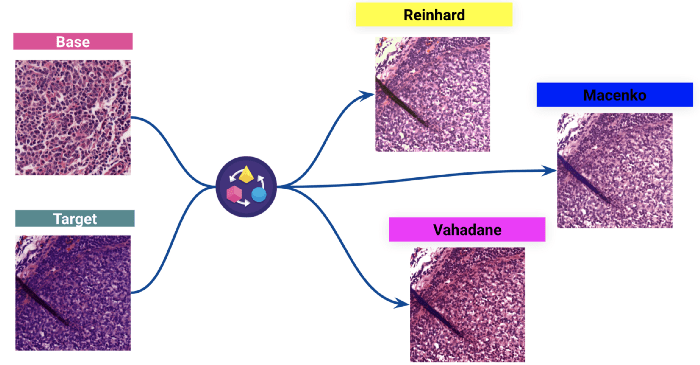
(Arriba: Resultados de tres normalizaciones de tinción diferentes: una coloración de la imagen objetivo se normaliza con respecto a una distribución del color de la imagen base).
Elegimos el Reinhard técnica para ver el impacto en el modelo.
Entrenamiento de un clasificador Resnet-18
Tras procesar las imágenes de diapositivas enteras, el entrenamiento transcurrió sin problemas (abandono, decaimiento del peso, etc.). Nada del otro mundo, salvo por la adición de la mezcla en el aumento data. Utilizamos un Resnet18 entrenados desde cero ya que los modelos preentrenados no mejoraban significativamente nuestros resultados. También preferimos el Resnet-18 ya que el Resnet-34 y el Resnet-56 no mejoraban nuestros resultados. Después de ~10 epochs, nuestro modelo estaba listo para la prueba.
Utilizamos el muy práctico Fastai biblioteca para construir nuestros modelos con pocos esfuerzos.
Pruebas
Merece la pena mencionar los resultados de 3 experimentos:
A continuación se muestran los resultados en el conjunto de pruebas de estos 3 experimentos:
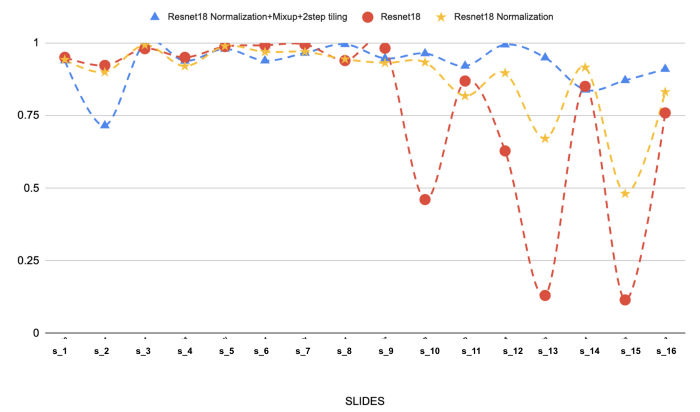
(Arriba: Los resultados de 3 modelos diferentes en las 16 preparaciones seleccionadas de linfoma folicular. Podemos ver el efecto de la normalización de la tinción y la mezcla en el rendimiento).
La normalización de las manchas es, con diferencia, el paso más importante de nuestro enfoque de modelización. Estábamos experimentando problemas de generalización (línea roja), pero sin duda ayuda a resolver el problema. Si añadimos la mezcla y un embaldosado en dos pasos, la cosa mejora aún más.
MixUp es una técnica de aumento data que consiste en crear nuevas observaciones interpolando linealmente muchas muestras.
Interpretar los resultados de un clasificador de visión por ordenador
Para comunicar fácilmente los resultados a los expertos médicos, proporcionamos imágenes con mapas de calor para resaltar dónde se centraba el modelo al predecir una etiqueta determinada. Lo hicimos extrayendo la última capa de activación de la red convolucional y extrapolándola linealmente sobre la imagen en la que estábamos prediciendo.
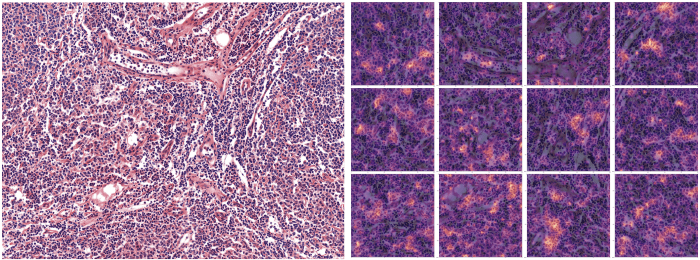
(Arriba: Las partes de la imagen que más han contribuido a la predicción de la clase Linfoma folicular están resaltadas en la imagen del lado derecho - 12 manchas)).
La interpretación de los resultados del modelo con mapas térmicos ha sido muy útil para ajustar el enfoque de modelización, ya que ofrece a los expertos formas de analizar lo que el modelo está haciendo realmente. A través de nuestros intercambios con los expertos, nosotros (los científicos del data) pudimos ajustar la forma de manejar mejor el conjunto del data y hacer que el modelo fuera más robusto (es decir, capaz de adaptarse a diferentes tipos de entradas). Y también para asegurarnos de que sirviera a su propósito. De hecho, fue así como nos dimos cuenta de la necesidad de normalizar la tinción de las imágenes.
Conclusión y principales enseñanzas
El objetivo de este estudio era explorar el proceso de creación de un buen clasificador de base de aprendizaje profundo para diferenciar el linfoma folicular y la hiperplasia folicular. Nuestros aprendizajes clave se enumeran a continuación:
