


How entropy-based scoring can tell you when your model is making things up — and where — wrapped up in artefactual, our Python package.
Note: This article is a follow-up to the article from our friends at Ardian, detailing how crucial accountable AI is for financial institutions. Make sure to check it out!
The hallucination problem
Large Language Models are astonishingly capable. They summarize, translate, reason, and code (better than me). But unlike me, they have also become notorious for inventing facts with unnerving confidence.
In the Natural Language Processing (NLP) literature, a hallucination is any model-generated content that is factually incorrect, nonsensical, or unfaithful to a provided source, while appearing perfectly plausible. The consequences range from benign (a wrong trivia answer) to severe (a fabricated legal citation, an incorrect drug dosage). As organizations integrate LLMs into production systems, the question shifts from “can this model generate useful text?” to “can we trust what it just said?”
Consider a concrete example. You work at a financial institution, and you ask your local LLM:
“What was Emerson Electric’s net revenue in 2023?”
The model replies: “Emerson Electric reported a net revenue of approximately $15.2 billion for fiscal year 2023.” Sounds reasonable. But is it right? You don’t have the annual report open. You don’t have a ground truth to compare against. You just have the model’s output — and doubt.
This is the setting we work in. No oracle. No reference answer at inference time. Just an LLM response and the metadata it produces while generating it. The goal: quantify how likely this output is to be hallucinated, from a single generation pass.
Detecting hallucinations: it’s harder than it sounds
The brute-force approach
One natural idea is to ask the model the same question several times and check whether the answers agree. If five out of six runs say “$15.2 billion” and one says “$18.7 billion”, the consensus gives you some confidence. This is the principle behind methods like SelfCheckGPT, which measure consistency across multiple sampled outputs — a “Monte Carlo-style” approach to hallucination detection.
It works. But it comes with two significant drawbacks:
- Cost. Each additional generation multiplies your inference budget. For SelfCheckGPT with 10 samples, you pay roughly 10x the compute, plus the cost of a semantic similarity model on top. At scale, this is prohibitive.
- Granularity. Multi-shot methods operate at the sequence level. They tell you “this answer seems unreliable”, but not which part of the answer is problematic. A response might be 90% accurate with a single hallucinated figure buried in the middle. You’d like to know where.
These limitations motivated us to look for a different signal — one that is cheap, single-shot, and works at the token level (the individual pieces of words the LLM manipulates internally).
The signal is already there
When an LLM generates text, it doesn’t just output tokens. At each step, it computes a probability distribution over its entire vocabulary: “given the prompt and everything I’ve generated so far, how likely is each possible next token?” The winning token gets sampled. The rest are discarded. But those probabilities (and more specifically, how spread out they are) carry information about the model’s internal confidence.
If the model is very sure, most of the probability mass concentrates on a single token. If the model hesitates, the probability spreads across many candidates. This spread is exactly what entropy measures.
Entropy: a quick detour
Entropy is an information-theoretic quantity that measures the uncertainty of a probability distribution. The intuition is straightforward. Imagine three boxes. One contains a cookie. You have to guess which one.

- Scenario A: You know the cookie is in box 2. Your uncertainty is zero. Entropy = 0.
- Scenario B: You have no idea. Each box has a 1/3 chance. Your uncertainty is maximal. Entropy = log₂(3) ≈ 1.58 bits.
Now replace boxes with tokens and the cookie with the “correct” next word. At every generation step, an LLM faces this exact choice — except instead of 3 boxes, it picks from a vocabulary of more than 100,000 tokens. When the model is confident, one token dominates and the entropy is low. When it hesitates, entropy goes up.
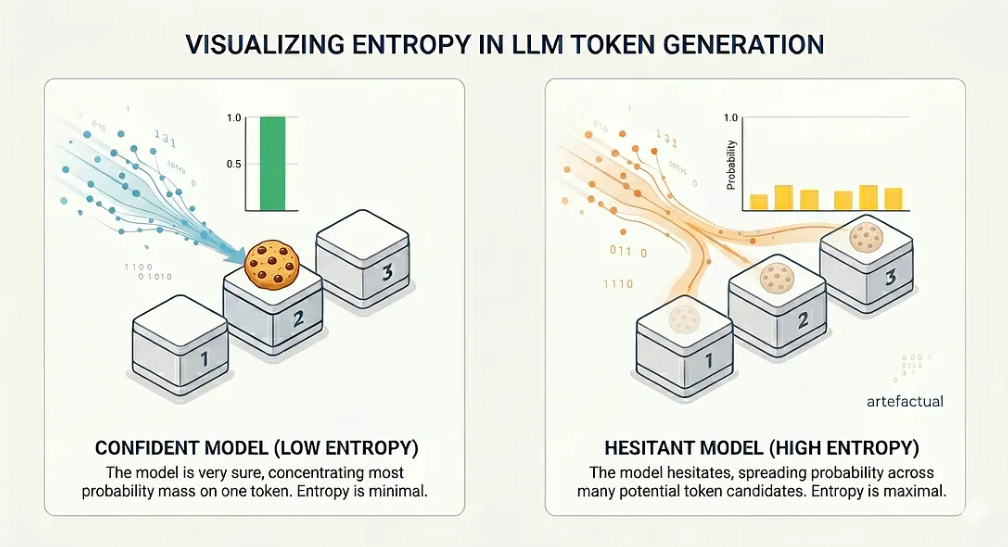
The probability distribution spread in two different cases.
The key insight is that high entropy at a given token position correlates with a higher likelihood of error at that position. The model is telling you, through its probability distribution, that it isn’t sure what comes next. We just need to listen.
From entropy to hallucination scores
EPR: Entropy Production Rate
Our first metric, EPR (Entropy Production Rate), is direct. For each token in the generated sequence, we compute the entropy of the model’s top-K predicted token probabilities. Then we average across the sequence. This gives a single number reflecting the model’s average hesitation over the full response.
This is an unsupervised metric: no labels required. In our experiments (published at ECIR 2026), EPR alone achieves ROC-AUC scores between 74 and 81 on TriviaQA across four different LLMs. Not bad for a metric that costs essentially nothing beyond a single generation pass.
But we can do better.
WEPR: Weighted Entropy Production Rate
Raw entropy treats all token ranks equally. The entropy contribution of the 1st-ranked token (the most probable one) and the 10th-ranked token are weighted the same. In practice, the way uncertainty distributes across ranks carries discriminative information.
WEPR (Weighted EPR) learns a set of weights to re-balance these contributions. It uses two signals:
- The mean weighted entropy across the sequence — capturing overall hesitation.
- The maximum entropy contribution per rank — capturing uncertainty spikes. A single moment of high hesitation can be the hallmark of a hallucination, even if the rest of the sequence was generated confidently.
These features are fed into a logistic regression, trained on a labeled dataset. The output of the sigmoid is a calibrated probability:
“This response has a 86% probability of containing a hallucination.”
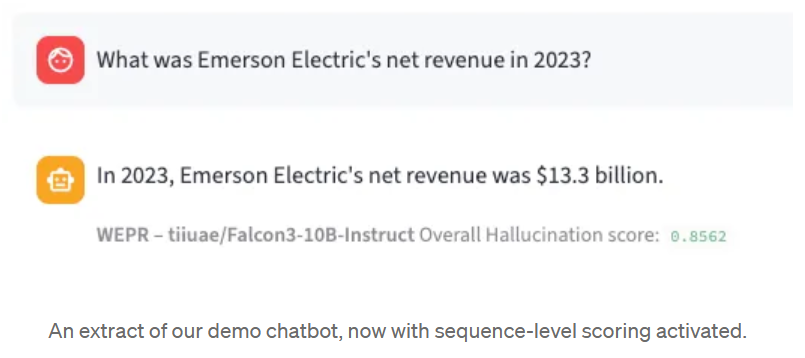
Beyond classification, WEPR also produces token-level scores. Each token in the generated sequence gets its own hallucination probability, allowing you to pinpoint exactly which parts of a response deserve scrutiny. This is computed in real time, token by token, as the model generates — no need to wait for the full output.

What about labels?
A supervised method requires annotations. Labeling thousands of QA pairs by hand is slow. So we use an LLM-as-a-judge approach: a separate model compares each generated answer to the known ground truth and labels it as correct or incorrect.
Is this reliable? We validated it against human annotators. A group of 15 researchers hand-labeled over 1,300 answer pairs. Agreement between the automated judge and human evaluators reached 95.7%, with a Cohen’s Kappa of 0.90. The automated labels are a reliable proxy for human judgment and are robust enough to train a hallucination detector on.
Introducing artefactual: now it’s your turn to play.
We packaged all of this into an open-source Python library: artefactual.
The library ships with pre-computed calibration weights for several model families (Mistral-Small, Falcon-3, Phi-4, Ministral-8B), so you can start scoring outputs immediately without running any training pipeline. It parses outputs from vLLM, the OpenAI Chat Completions API, and the OpenAI Responses API out of the box.
Here is the simplest possible usage:

The token-level scores are particularly useful for visualization. Each token in the response gets its own hallucination probability, which you can render as a color gradient, green for confident or red for uncertain. At a glance, you see exactly which parts of a response deserve scrutiny.
In a RAG pipeline
Where this gets practical is in Retrieval-Augmented Generation. Imagine a pipeline that retrieves documents from a knowledge base and feeds them as context to an LLM. If the retrieval fails (wrong documents, missing pages, incomplete context, etc.) the model will attempt to fill the gaps from its parametric memory, and that is where hallucinations creep in.
With artefactual, you can add a gate:

Our scientific Article In a nutshell — What We found
We tested EPR and WEPR across four LLMs (Mistral-Small-24B, Falcon-3–10B, Phi-4, Ministral-8B) on three tasks: hallucination detection on TriviaQA, generalization to WebQuestions, and missing-context detection in a financial RAG setting.
A few highlights:
- WEPR consistently outperforms existing methods. It beats both SelfCheckGPT (a multi-shot method requiring 10x the compute) and HalluDetect (a single-shot competitor) across nearly all model-dataset combinations.
- You don’t need many log-probabilities. Performance plateaus around K = 8–10 accessible log-probabilities per token. Even with limited API access, the signal is there.
- It generalizes. WEPR trained on TriviaQA transfers well to WebQuestions and even to a specialized financial corpus, detecting cases where a RAG system generated answers without sufficient context.
- It’s fast. Scoring takes roughly 80 microseconds per sequence. Compare that to >10 seconds for SelfCheckGPT.
In our experiments on a financial RAG task (analyzing 10-K annual reports from the ArGiMi-Ardian dataset), WEPR reached up to 93.6 ROC-AUC in detecting responses generated without the right context. This is a strong signal for triggering a second retrieval pass.
Note on log-probability access:
Everything described above relies on one thing: access to token-level log-probabilities from the model. This is what lets us compute entropy and, by extension, hallucination scores.
Today, this access is not guaranteed. Anthropic does not expose log-probabilities through its API. OpenAI provides them for non-reasoning models — you can request top_logprobs with GPT-5.4 or GPT-5.4-mini, but only if you set the reasoning effort to none . On the other hand, Google allows access to all logprobs with its generate_content API.
Open-weight models served through vLLM or similar inference engines give full access.
This matters. Log-probabilities are a lightweight, information-rich signal. They cost nothing extra to produce (the model computes them anyway during generation) and they enable a whole class of uncertainty quantification methods — ours included. Restricting access to them pushes users toward either blind trust in model outputs or expensive multi-shot detection methods.
If you work with LLMs in production and care about output reliability, the availability of log-probabilities should be part of your model selection criteria. And if you are a model provider: exposing log-probabilities is one of the cheapest ways to make your models more trustworthy.
