


我们的 Python 软件包--artefactual--如何通过基于熵的评分来告诉你,你的模型何时以及在何处在胡编乱造。.
注:本文是以下文章的后续 来自 Ardian 朋友的文章, 详细介绍了负责任的人工智能对金融机构的重要性。请务必查看!
幻觉问题
大型语言模型的能力令人惊叹。它们总结、翻译、推理和编码(比我强)。但与我不同的是,它们也因以令人不安的自信编造事实而声名狼藉。.
在自然语言处理(NLP)文献中,幻觉是指任何由模型生成的内容,这些内容与事实不符、毫无道理或不忠于所提供的来源,但看起来却十分可信。其后果从轻微(一个错误的琐事答案)到严重(一个捏造的法律引文、一个错误的药物剂量)不等。随着企业将 LLM 集成到生产系统中,问题从 “这个模型能生成有用的文本吗?” 至 “我们能相信它刚才说的话吗?”
请看一个具体的例子。您在一家金融机构工作,您向当地的法律硕士询问:"您在哪里工作?
“艾默生电气 2023 年的净收入是多少?”
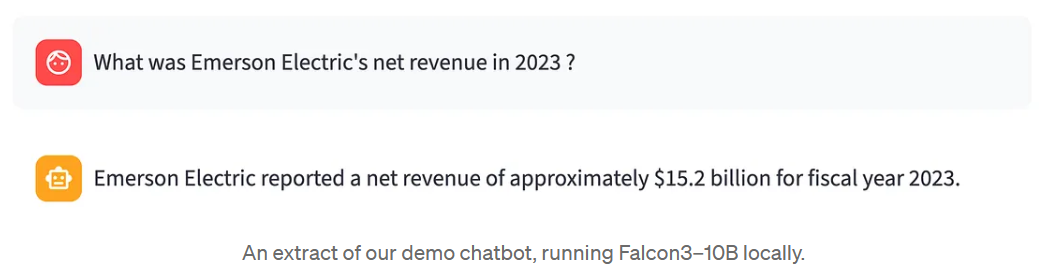
模特回答说 “艾默生电气公布的 2023 财年净营收约为 $152 亿美元”。” 听起来很有道理。但这样做对吗?你没有打开年度报告。你没有基本事实可以比较。你只有模型的输出--和怀疑。.
这就是我们的工作环境。没有神谕。推理时没有参考答案。只有一个 LLM 响应和它在生成响应时产生的元 data。我们的目标是:通过单次生成,量化输出结果产生幻觉的可能性。.
检测幻觉:比听起来更难
蛮力方法
一个很自然的想法是多次向模型提出同样的问题,并检查答案是否一致。如果六次运行中有五次说 “$152 亿”,一次说 “$187 亿”,那么这种共识就会给你带来一些信心。这就是像 SelfCheckGPT 这样的方法背后的原理,它可以测量多个采样输出的一致性--一种 “蒙特卡罗式 ”的幻觉检测方法。.
它很有效。但它有两个明显的缺点:
- 费用. 每增加一代样本,推理预算就会增加一倍。对于有 10 个样本的 SelfCheckGPT,你需要支付大约 10 倍的计算费用,再加上语义相似性模型的费用。在大规模情况下,这样的成本令人望而却步。.
- 粒度。. 多拍法是在序列层面上操作的。它们会告诉你 “这个答案似乎不可靠”,但不会告诉你答案的哪个部分有问题。一个答案可能是 90% 准确,但中间埋藏了一个幻觉数字。你想知道在哪里。.
这些局限性促使我们寻找一种不同的信号--一种廉价、单次发射、可在标记级别(即 LLM 内部处理的单个词块)工作的信号。.
信号已经存在
当 LLM 生成文本时,它并不只是输出标记。每一步,它都会计算整个词汇表的概率分布: “根据提示和我目前生成的所有信息” "下一个标记的可能性有多大?" 获胜的令牌会被采样。其余的则被丢弃。但这些概率(更具体地说,它们的分散程度)包含了模型内部置信度的信息。.
如果模型非常确定,则大部分概率都集中在一个标记上。如果模型犹豫不决,概率就会分散到许多候选符号上。这种分散正是熵的衡量标准。.
熵:快速绕行
熵是一个信息论量,用来衡量概率分布的不确定性。其直观性非常简单。想象三个盒子。其中一个装有一块饼干。你必须猜出是哪一个。.

- 方案 A: 你知道饼干在 2 号盒子里。你的不确定性为零。熵 = 0。.
- 方案 B: 你根本不知道。每个盒子都有 1/3 的机会。你的不确定性是最大的。熵 = log₂(3) ≈ 1.58 位。.
现在,用代词替换方框,用 “正确 ”的下一个词替换 cookie。在每一步生成过程中,LLM 都会面临这样的选择--只不过它要从超过 10 万个词库中挑选的不是 3 个方框。当模型信心十足时,一个标记占主导地位,熵值较低。当它犹豫不决时,熵就会上升。.
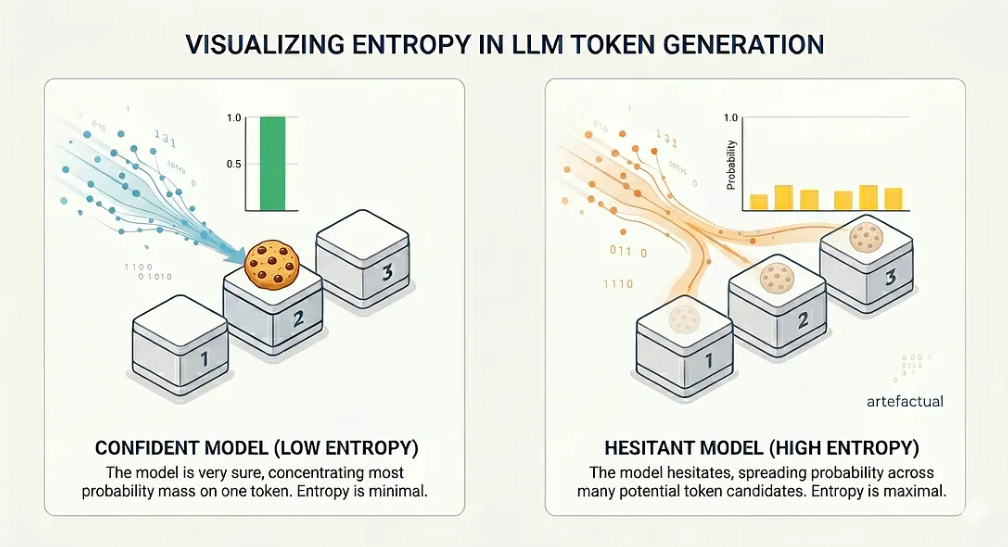
两种不同情况下的概率分布分布。.
其中的关键之处在于,特定标记位置的高熵与该位置出错的可能性相关。模型通过其概率分布告诉你,它不确定接下来会发生什么。我们只需要倾听。.
从熵到幻觉分数
EPR:熵产生率
我们的第一个指标 EPR(熵生成率)是直接指标。对于生成序列中的每个标记,我们计算模型预测的前 K 个标记概率的熵。然后取整个序列的平均值。这样就得到了一个单一的数字,反映了模型在整个响应过程中的平均犹豫程度。.
这是一个无监督指标:不需要标签。在我们的实验(发表于 ECIR 2026)中,仅 EPR 一项就在 TriviaQA 的四种不同 LLM 中获得了 74 到 81 分的 ROC-AUC 分数。对于一个除了单次生成之外几乎不需要任何成本的指标来说,这还算不错。.
但我们可以做得更好。.
WEPR:加权熵产生率
原始熵对所有标记的排名一视同仁。排名第一的标记(最有可能的标记)和排名第十的标记的熵贡献加权相同。实际上,不确定性在不同等级之间的分布方式蕴含着不同的信息。.
WEPR(加权 EPR)通过学习一组权重来重新平衡这些贡献。它使用两个信号:
- "(《世界人权宣言》) 吝啬 整个序列的加权熵--捕捉整体犹豫。.
- "(《世界人权宣言》) 最大 每个等级的熵贡献--捕捉不确定性峰值。即使序列的其余部分都是有把握地生成的,单个高度犹豫的时刻也可能是幻觉的标志。.
这些特征被送入逻辑回归,并在标注的 dataset 上进行训练。sigmoid 的输出为校准概率:
“此回复有 86% 的概率包含幻觉”
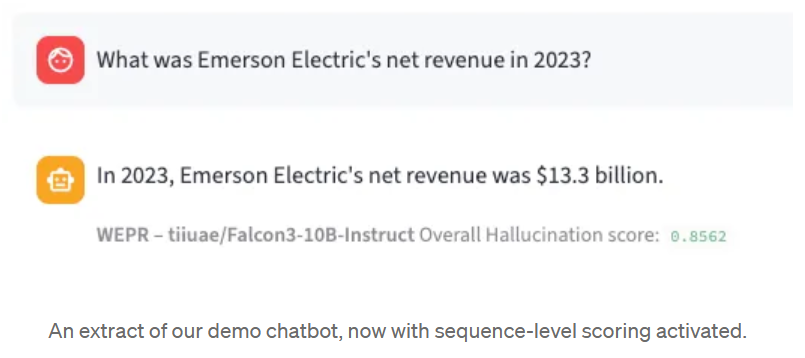
除了分类之外,WEPR 还能生成标记级评分。生成序列中的每个标记都有自己的幻觉概率,让您可以精确地确定响应中哪些部分值得仔细检查。这是在模型生成时逐个标记实时计算的,无需等待完整输出。.

标签怎么办?
有监督的方法需要注释。手工标注成千上万个质量保证对的速度很慢。因此,我们使用 法学硕士担任法官 方法:由一个单独的模型将生成的每个答案与已知的地面实况进行比较,并将其标注为正确或错误。.
这可靠吗?我们通过人类标注者对其进行了验证。由 15 位研究人员组成的小组对 1,300 多对答案进行了人工标注。自动判断与人类评估者之间的一致性达到 95.7%,科恩卡帕(Cohen's Kappa)为 0.90。自动标签是人类判断的可靠替代物,其稳健性足以用来训练幻觉检测器。.
介绍人工制品:现在轮到你们玩了。.
我们将所有这些打包成一个开源 Python 库: 人工.
该库为多个模型系列(Mistral-Small、Falcon-3、Phi-4、Ministral-8B)提供了预先计算的校准权重,因此您无需运行任何训练管道即可立即开始对输出进行评分。它可以解析来自 vLLM、OpenAI Chat Completions API 和 OpenAI Responses API 的输出。.
下面是最简单的用法:

令牌级分数对可视化特别有用。回复中的每个标记都有自己的幻觉概率,您可以将其呈现为颜色梯度,绿色代表有把握,红色代表不确定。这样一目了然,您就能清楚地看到回复中哪些部分值得仔细研究。.
在 RAG 管道中
在检索增强生成(Retrieval-Augmented Generation)中,这一点变得非常实用。试想一个从知识库中检索文档并将其作为上下文输入 LLM 的管道。如果检索失败(错误的文档、缺失的页面、不完整的上下文等),该模型将尝试从其参数化记忆中填补空白,这就是幻觉悄然出现的地方。.
通过人工智能,您可以添加一个门:

我们的科学文章简述--我们的发现
我们在四种 LLM(Mistral-Small-24B、Falcon-3-10B、Phi-4、Ministral-8B)上测试了 EPR 和 WEPR 的三个任务:TriviaQA 上的幻觉检测、WebQuestions 的泛化以及金融 RAG 设置中的缺失上下文检测。.
几个亮点
- WEPR 始终优于现有方法。. 在几乎所有的模型-dataset 组合中,它都击败了 SelfCheckGPT(一种需要 10 倍计算量的多镜头方法)和 HalluDetect(一种单镜头竞争对手)。.
- 你不需要太多对数概率。. 每个令牌的性能在 K = 8-10 个可访问对数概率时趋于稳定。即使 API 访问受限,信号仍然存在。.
- 它具有概括性。. 在 TriviaQA 上训练的 WEPR 可以很好地应用于 WebQuestions,甚至应用于专门的金融语料库,检测出 RAG 系统生成的答案缺乏足够上下文的情况。.
- 速度很快。. 每个序列的评分大约需要 80 微秒。相比之下,SelfCheckGPT 则需要 10 秒以上。.
在我们对金融 RAG 任务(分析 ArGiMi-Ardian dataset 中的 10-K 年度 reports)的实验中,WEPR 在检测无正确上下文情况下生成的响应时,ROC-AUC 高达 93.6。这是触发第二次检索的强烈信号。.
关于对数概率存取的说明:
上述一切都有赖于一件事:从模型中获取标记级日志概率。这样我们才能计算熵,进而计算幻觉分数。.
如今,这种访问权限无法保证。Anthropic 没有通过其 API 公开日志概率。OpenAI 为非推理模型提供了它们--您可以使用 GPT-5.4 或 GPT-5.4-mini 请求 top_logprobs,但前提是您必须将推理工作设置为 "无"。另一方面,Google 允许通过其 generate_content API 访问所有 logprobs。.
通过 vLLM 或类似推理引擎提供的开放权重模型可实现完全访问。.
这很重要。对数概率是一种轻量级、信息丰富的信号。生成对数概率不需要额外成本(反正模型在生成过程中也会计算对数概率),而且对数概率还支持一整套不确定性量化方法--包括我们的方法。限制对数概率的使用会将用户推向对模型输出的盲目信任或昂贵的多拍检测方法。.
如果您在生产中使用 LLM 并关心输出的可靠性,那么对数概率的可用性应该是您选择模型标准的一部分。如果您是模型提供商:公开对数概率是提高模型可信度的最廉价方法之一。.

