


Hoe op entropie gebaseerde scores u kunnen vertellen wanneer uw model dingen verzint - en waar - verpakt in artefactual, ons Python-pakket.
Opmerking: Dit artikel is een vervolg op het artikel van onze vrienden bij Ardian, waarin gedetailleerd wordt beschreven hoe cruciaal verantwoordelijke AI is voor financiële instellingen. Bekijk het zeker!
Het hallucinatieprobleem
Grote Taalmodellen zijn verbazingwekkend vaardig. Ze vatten samen, vertalen, redeneren en coderen (beter dan ik). Maar in tegenstelling tot mij, zijn ze ook berucht geworden voor het verzinnen van feiten met een angstaanjagend zelfvertrouwen.
In de literatuur over Natural Language Processing (NLP) wordt onder een hallucinatie elke door een model gegenereerde inhoud verstaan die feitelijk onjuist, onzinnig of niet trouw aan een verstrekte bron is, terwijl hij volkomen plausibel lijkt. De gevolgen variëren van goedaardig (een verkeerd trivia-antwoord) tot ernstig (een vervalst juridisch citaat, een onjuiste medicijndosering). Naarmate organisaties LLM's in productiesystemen integreren, verschuift de vraag van “Kan dit model nuttige tekst genereren?” naar “Kunnen we vertrouwen op wat het net zei?”
Neem een concreet voorbeeld. U werkt bij een financiële instelling en u vraagt uw plaatselijke LLM:
“Wat was de netto omzet van Emerson Electric in 2023?”
Het model antwoordt: “Emerson Electric rapporteerde een netto-omzet van ongeveer $15,2 miljard voor het boekjaar 2023.” Klinkt redelijk. Maar is het juist? U hebt het jaarverslag niet open. U hebt geen grondwaarheid om mee te vergelijken. U hebt alleen de uitvoer van het model - en twijfel.
Dit is de omgeving waarin we werken. Geen orakel. Geen referentieantwoord op het moment van inferentie. Alleen een LLM antwoord en de metadata die het genereert. Het doel: kwantificeren hoe waarschijnlijk het is dat deze uitvoer gehallucineerd wordt, op basis van een enkele generatieronde.
Hallucinaties opsporen: het is moeilijker dan het klinkt
De brute-force benadering
Een natuurlijk idee is om het model dezelfde vraag meerdere keren te stellen en te controleren of de antwoorden overeenkomen. Als vijf van de zes runs zeggen “$15,2 miljard” en één zegt “$18,7 miljard”, dan geeft de consensus u enig vertrouwen. Dit is het principe achter methodes zoals SelfCheckGPT, die de consistentie over meerdere bemonsterde uitkomsten meet - een “Monte Carlo-achtige” benadering van hallucinatiedetectie.
Het werkt. Maar het heeft twee belangrijke nadelen:
- Kosten. Elke extra generatie vermenigvuldigt uw inferentiebudget. Voor SelfCheckGPT met 10 samples betaalt u ruwweg 10x meer rekenwerk, plus de kosten van een semantisch similariteitsmodel. Op schaal is dit onbetaalbaar.
- Granulariteit. Multi-shot methoden werken op sequentieniveau. Ze vertellen u “dit antwoord lijkt onbetrouwbaar”, maar niet welk deel van het antwoord problematisch is. Een antwoord kan 90% nauwkeurig zijn met een enkele hallucinerende figuur in het midden. U wilt graag weten waar.
Deze beperkingen motiveerden ons om op zoek te gaan naar een ander signaal - een signaal dat goedkoop en eenmalig is, en dat werkt op tokenniveau (de afzonderlijke stukjes woorden die de LLM intern manipuleert).
Het signaal is er al
Wanneer een LLM tekst genereert, voert hij niet alleen tokens uit. Bij elke stap berekent het een waarschijnlijkheidsverdeling over zijn volledige woordenschat: “Gegeven de prompt en alles wat ik tot nu toe heb gegenereerd, hoe waarschijnlijk is elke mogelijke volgende token?” De winnende loper wordt bemonsterd. De rest wordt weggegooid. Maar deze waarschijnlijkheden (en meer specifiek, hoe ze verdeeld zijn) bevatten informatie over de interne betrouwbaarheid van het model.
Als het model heel zeker is, concentreert het grootste deel van de waarschijnlijkheidsmassa zich op één token. Als het model aarzelt, verspreidt de waarschijnlijkheid zich over veel kandidaten. Deze spreiding is precies wat entropie meet.
Entropie: een snelle omweg
Entropie is een informatie-theoretische grootheid die de onzekerheid van een kansverdeling meet. De intuïtie is eenvoudig. Stelt u zich drie dozen voor. Eén doos bevat een koekje. U moet raden welke.

- Scenario A: U weet dat het koekje in vakje 2 zit. Uw onzekerheid is nul. Entropie = 0.
- Scenario B: U hebt geen idee. Elk vakje heeft 1/3 kans. Uw onzekerheid is maximaal. Entropie = log₂(3) ≈ 1,58 bits.
Vervang nu de vakjes door tokens en het koekje door het “juiste” volgende woord. Bij elke generatiestap staat een LLM voor precies dezelfde keuze - behalve dat het in plaats van 3 vakjes een keuze maakt uit een woordenschat van meer dan 100.000 tokens. Als het model vol vertrouwen is, domineert één token en is de entropie laag. Als het model aarzelt, gaat de entropie omhoog.
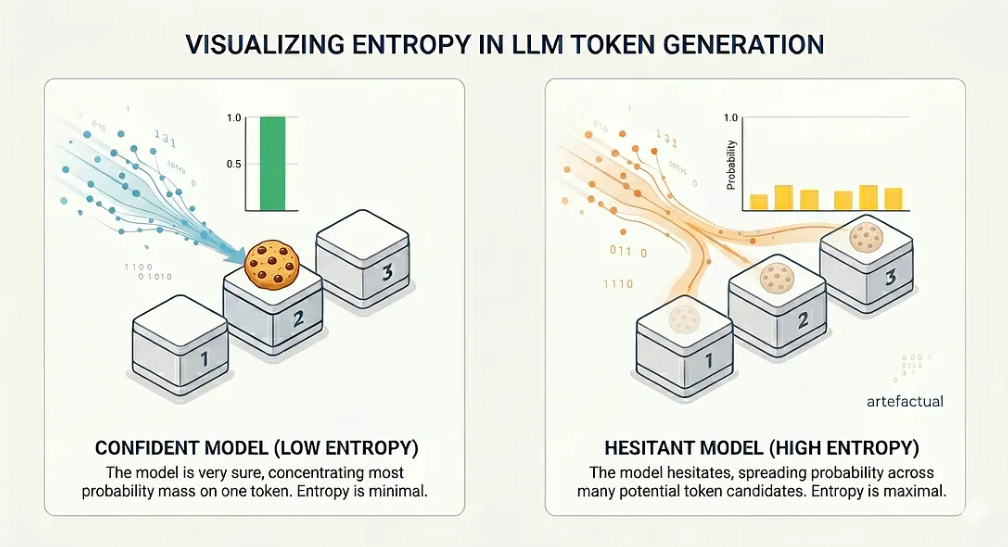
De kansverdelingsspreiding in twee verschillende gevallen.
Het belangrijkste inzicht is dat een hoge entropie op een bepaalde tokenpositie correleert met een hogere waarschijnlijkheid van fouten op die positie. Het model vertelt u, via zijn waarschijnlijkheidsverdeling, dat het niet zeker weet wat er hierna komt. We hoeven alleen maar te luisteren.
Van entropie tot hallucinatiescores
EPR: Entropie Productiesnelheid
Onze eerste metriek, EPR (Entropy Production Rate), is direct. Voor elk token in de gegenereerde reeks berekenen we de entropie van de top-K van de voorspelde tokenwaarschijnlijkheden van het model. Vervolgens nemen we het gemiddelde over de reeks. Dit levert een enkel getal op dat de gemiddelde aarzeling van het model over het volledige antwoord weergeeft.
Dit is een metriek zonder supervisie: er zijn geen labels nodig. In onze experimenten (gepubliceerd op ECIR 2026) behaalt EPR alleen ROC-AUC scores tussen 74 en 81 op TriviaQA over vier verschillende LLM's. Niet slecht voor een metriek die in wezen niets kost behalve een enkele generatiepass.
Maar we kunnen beter.
WEPR: Gewogen entropieproductiesnelheid
De ruwe entropie behandelt alle tokenranges gelijk. De entropiebijdrage van het token van de 1e rang (de meest waarschijnlijke) en het token van de 10e rang worden hetzelfde gewogen. In de praktijk bevat de manier waarop onzekerheid over de rangen wordt verdeeld onderscheidende informatie.
WEPR (Weighted EPR) leert een set gewichten om deze bijdragen opnieuw in evenwicht te brengen. Het gebruikt twee signalen:
- De gemiddelde gewogen entropie over de hele reeks - die de algemene aarzeling vastlegt.
- De maximaal entropiebijdrage per rang - onzekerheidspieken vastleggen. Een enkel moment van grote aarzeling kan het kenmerk zijn van een hallucinatie, zelfs als de rest van de reeks vol vertrouwen werd gegenereerd.
Deze kenmerken worden ingevoerd in een logistische regressie, getraind op een gelabelde dataset. De output van de sigmoïde is een gekalibreerde waarschijnlijkheid:
“Dit antwoord heeft een waarschijnlijkheid van 86% dat het een hallucinatie bevat.”
Naast classificatie produceert WEPR ook scores op tokenniveau. Elk token in de gegenereerde sequentie krijgt zijn eigen hallucinatiewaarschijnlijkheid, zodat u precies kunt bepalen welke delen van een reactie een nauwkeurig onderzoek verdienen. Dit wordt in realtime berekend, token voor token, terwijl het model genereert - u hoeft niet te wachten op de volledige uitvoer.

Hoe zit het met etiketten?
Een methode onder toezicht vereist annotaties. Het handmatig labelen van duizenden QA-paren is traag. Dus gebruiken we een LLM-als-rechter benadering: een afzonderlijk model vergelijkt elk gegenereerd antwoord met de bekende grondwaarheid en labelt het als juist of onjuist.
Is dit betrouwbaar? We hebben het gevalideerd met menselijke annotators. Een groep van 15 onderzoekers labelde meer dan 1300 antwoordparen met de hand. De overeenkomst tussen de geautomatiseerde beoordelaar en menselijke beoordelaars bereikte 95,7%, met een Cohen's Kappa van 0,90. De geautomatiseerde labels zijn een betrouwbare vervanging voor menselijke beoordelingen en zijn robuust genoeg om een hallucinatiedetector op te trainen.
Maak kennis met artefactual: nu is het uw beurt om te spelen.
We hebben dit alles verpakt in een open-source Python-bibliotheek: artefactueel.
De bibliotheek wordt geleverd met vooraf berekende kalibratiegewichten voor verschillende modelfamilies (Mistral-Small, Falcon-3, Phi-4, Ministral-8B), zodat u onmiddellijk kunt beginnen met het scoren van uitvoer zonder een trainingspijplijn uit te voeren. Het parseert uitvoer van vLLM, de OpenAI Chat Completions API en de OpenAI Responses API out of the box.
Hier is het eenvoudigst mogelijke gebruik:

De scores op tokenniveau zijn bijzonder nuttig voor visualisatie. Elk token in het antwoord krijgt zijn eigen hallucinatiewaarschijnlijkheid, die u kunt weergeven als een kleurverloop, groen voor zeker of rood voor onzeker. In één oogopslag ziet u precies welke delen van een antwoord aandacht verdienen.
In een RAG-pijplijn
Waar dit praktisch wordt, is in Retrieval-Augmented Generation. Stelt u zich een pijplijn voor die documenten ophaalt uit een kennisbank en deze als context naar een LLM stuurt. Als het ophalen mislukt (verkeerde documenten, ontbrekende pagina's, onvolledige context, enz.) zal het model proberen de gaten op te vullen vanuit zijn parametrische geheugen, en dat is waar hallucinaties in het spel komen.
Met artefactual kunt u een poort toevoegen:

Ons wetenschappelijke artikel In een notendop - Wat we hebben gevonden
We hebben EPR en WEPR getest op vier LLM's (Mistral-Small-24B, Falcon-3-10B, Phi-4, Ministral-8B) op drie taken: hallucinatiedetectie op TriviaQA, generalisatie naar WebQuestions en detectie van ontbrekende context in een financiële RAG-omgeving.
Enkele hoogtepunten:
- WEPR presteert consequent beter dan bestaande methoden. Het verslaat zowel SelfCheckGPT (een multi-shot methode die 10x meer rekenwerk vereist) als HalluDetect (een single-shot concurrent) voor bijna alle model-dataset combinaties.
- U hebt niet veel log-probabiliteiten nodig. Prestaties plateaus rond K = 8-10 toegankelijke log-probabiliteiten per token. Zelfs met beperkte API-toegang is het signaal er.
- Het generaliseert. WEPR getraind op TriviaQA kan goed worden toegepast op WebQuestions en zelfs op een gespecialiseerd financieel corpus, waarbij gevallen worden gedetecteerd waarin een RAG-systeem antwoorden genereerde zonder voldoende context.
- Het is snel. Scoren duurt ruwweg 80 microseconden per reeks. Vergelijk dat met >10 seconden voor SelfCheckGPT.
In onze experimenten met een financiële RAG-taak (het analyseren van 10-K jaarlijkse reports uit de ArGiMi-Ardian dataset), bereikte WEPR tot 93,6 ROC-AUC bij het detecteren van reacties die zonder de juiste context waren gegenereerd. Dit is een sterk signaal voor het activeren van een tweede retrieval pass.
Opmerking over log-probabiliteitstoegang:
Alles wat hierboven beschreven is, berust op één ding: toegang tot log waarschijnlijkheden op token-niveau van het model. Hiermee kunnen we entropie berekenen en, bij uitbreiding, hallucinatiescores.
Vandaag de dag is deze toegang niet gegarandeerd. Anthropic geeft geen log-probabiliteiten vrij via zijn API. OpenAI biedt ze voor niet-redenerende modellen - u kunt top_logprobs opvragen met GPT-5.4 of GPT-5.4-mini, maar alleen als u de redeneerinspanning instelt op geen . Aan de andere kant geeft Google toegang tot alle logprobs met zijn generate_content API.
Open-gewicht modellen die via vLLM of vergelijkbare inferentie-engines worden bediend, geven volledige toegang.
Dit is belangrijk. Logkansen zijn een lichtgewicht, informatierijk signaal. Het kost niets extra om ze te produceren (het model berekent ze toch al tijdens het genereren) en ze maken een hele klasse van onzekerheidsmethodes mogelijk - inclusief de onze. Het beperken van de toegang daartoe duwt gebruikers in de richting van blind vertrouwen in modeluitvoer of dure multi-shot detectiemethoden.
Als u in de productie met LLM's werkt en de betrouwbaarheid van de uitvoer belangrijk vindt, dan zou de beschikbaarheid van log waarschijnlijkheden deel moeten uitmaken van uw modelselectiecriteria. En als u een modelaanbieder bent: het blootleggen van log waarschijnlijkheden is een van de goedkoopste manieren om uw modellen betrouwbaarder te maken.
