


Wie die entropiebasierte Auswertung Ihnen sagen kann, wann Ihr Modell etwas erfindet - und wo - in artefactual, unserem Python-Paket, verpackt.
Hinweis: Dieser Artikel ist eine Fortsetzung zu der Artikel von unseren Freunden bei Ardian, in dem wir ausführlich darlegen, wie wichtig verantwortungsvolle KI für Finanzinstitute ist. Schauen Sie sich das unbedingt an!
Das Problem der Halluzinationen
Große Sprachmodelle sind erstaunlich leistungsfähig. Sie fassen zusammen, übersetzen, schlussfolgern und programmieren (besser als ich). Aber im Gegensatz zu mir sind sie auch dafür berüchtigt geworden, mit beunruhigendem Selbstvertrauen Fakten zu erfinden.
In der Literatur zur Verarbeitung natürlicher Sprache (NLP) ist eine Halluzination ein modellgenerierter Inhalt, der faktisch falsch, unsinnig oder nicht quellentreu ist, aber vollkommen plausibel erscheint. Die Folgen reichen von harmlos (eine falsche Trivialantwort) bis hin zu schwerwiegend (ein gefälschtes Rechtszitat, eine falsche Medikamentendosierung). Wenn Unternehmen LLMs in ihre Produktionssysteme integrieren, verschiebt sich die Frage von “Kann dieses Modell nützlichen Text erzeugen?” zu “Können wir dem vertrauen, was es gerade gesagt hat?”
Betrachten Sie ein konkretes Beispiel. Sie arbeiten bei einem Finanzinstitut und fragen Ihren örtlichen LLM:
“Wie hoch war der Nettoumsatz von Emerson Electric im Jahr 2023?”
Das Modell antwortet: “Emerson Electric meldete für das Geschäftsjahr 2023 einen Nettoumsatz von etwa $15,2 Milliarden.” Klingt vernünftig. Aber ist es auch richtig? Sie haben den Jahresbericht nicht geöffnet. Sie haben keine Basiswahrheit, mit der Sie vergleichen können. Sie haben nur die Ergebnisse des Modells - und Zweifel.
Das ist die Umgebung, in der wir arbeiten. Kein Orakel. Keine Referenzantwort zum Zeitpunkt der Inferenz. Nur eine LLM-Antwort und die metadata, die sie bei der Generierung erzeugt. Das Ziel: Quantifizierung der Wahrscheinlichkeit, dass diese Ausgabe bei einem einzigen Generierungsdurchlauf halluziniert wird.
Halluzinationen erkennen: Es ist schwieriger als es klingt
Der Brute-Force-Ansatz
Eine natürliche Idee ist es, dem Modell dieselbe Frage mehrmals zu stellen und zu prüfen, ob die Antworten übereinstimmen. Wenn fünf von sechs Durchläufen “$15,2 Milliarden” ergeben und einer “$18,7 Milliarden”, gibt Ihnen der Konsens eine gewisse Sicherheit. Dies ist das Prinzip hinter Methoden wie SelfCheckGPT, die die Konsistenz über mehrere Stichproben hinweg messen - ein “Monte-Carlo-ähnlicher” Ansatz zur Erkennung von Halluzinationen.
Es funktioniert. Aber es hat zwei entscheidende Nachteile:
- Kosten. Jede zusätzliche Generation vervielfacht Ihr Inferenzbudget. Für SelfCheckGPT mit 10 Stichproben zahlen Sie etwa das 10-fache an Rechenaufwand, plus die Kosten für ein semantisches Ähnlichkeitsmodell. Im großen Maßstab ist dies unerschwinglich.
- Granularität. Multi-Shot-Methoden arbeiten auf der Ebene der Sequenz. Sie sagen Ihnen “diese Antwort scheint unzuverlässig”, aber nicht, welcher Teil der Antwort problematisch ist. Eine Antwort könnte z.B. 90% genau sein und in der Mitte eine einzelne halluzinierte Figur enthalten. Sie würden gerne wissen, wo.
Diese Einschränkungen haben uns dazu veranlasst, nach einem anderen Signal zu suchen - einem, das billig und einmalig ist und auf der Token-Ebene funktioniert (die einzelnen Teile von Wörtern, die der LLM intern verarbeitet).
Das Signal ist bereits da
Wenn ein LLM Text erzeugt, gibt er nicht nur Token aus. Bei jedem Schritt berechnet er eine Wahrscheinlichkeitsverteilung über sein gesamtes Vokabular: “Wie wahrscheinlich ist angesichts der Aufforderung und allem, was ich bisher generiert habe, jeder mögliche nächste Token?” Der gewinnende Token wird in die Stichprobe aufgenommen. Der Rest wird verworfen. Aber diese Wahrscheinlichkeiten (und genauer gesagt, wie breit sie gestreut sind) enthalten Informationen über das interne Vertrauen des Modells.
Wenn das Modell sehr sicher ist, konzentriert sich der größte Teil der Wahrscheinlichkeitsmenge auf einen einzigen Token. Wenn das Modell zögert, verteilt sich die Wahrscheinlichkeit auf viele Kandidaten. Diese Streuung ist genau das, was die Entropie misst.
Entropie: ein kurzer Abstecher
Entropie ist eine informationstheoretische Größe, die die Unsicherheit einer Wahrscheinlichkeitsverteilung misst. Die Intuition ist ganz einfach. Stellen Sie sich drei Kisten vor. Eine enthält einen Keks. Sie müssen raten, welcher es ist.

- Szenario A: Sie wissen, dass der Keks in Box 2 ist. Ihre Unsicherheit ist gleich Null. Entropie = 0.
- Szenario B: Sie haben keine Ahnung. Jede Box hat eine Chance von 1/3. Ihre Unsicherheit ist maximal. Entropie = log₂(3) ≈ 1,58 Bits.
Ersetzen Sie nun die Kästchen durch Token und den Keks durch das “richtige” nächste Wort. Bei jedem Generierungsschritt steht ein LLM genau vor dieser Wahl - nur dass es anstelle von 3 Kästchen aus einem Vokabular von mehr als 100.000 Token auswählt. Wenn das Modell zuversichtlich ist, dominiert ein Token und die Entropie ist niedrig. Wenn es zögert, steigt die Entropie.
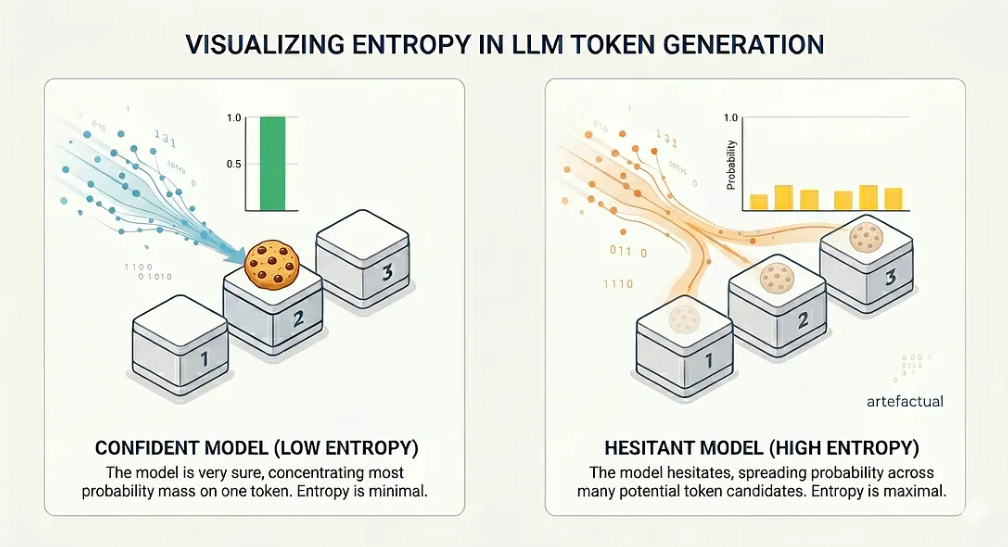
Die Wahrscheinlichkeitsverteilung verteilt sich in zwei verschiedenen Fällen.
Die wichtigste Erkenntnis ist, dass eine hohe Entropie an einer bestimmten Tokenposition mit einer höheren Fehlerwahrscheinlichkeit an dieser Position korreliert. Das Modell teilt Ihnen durch seine Wahrscheinlichkeitsverteilung mit, dass es nicht sicher ist, was als nächstes kommt. Wir müssen nur zuhören.
Von Entropie zu Halluzinationen - Noten
EPR: Entropie-Produktionsrate
Unsere erste Metrik, EPR (Entropy Production Rate), ist direkt. Für jedes Token in der generierten Sequenz berechnen wir die Entropie der Top-K vorhergesagten Token-Wahrscheinlichkeiten des Modells. Dann bilden wir den Durchschnitt über die gesamte Sequenz. Daraus ergibt sich eine einzige Zahl, die das durchschnittliche Zögern des Modells über die gesamte Antwort widerspiegelt.
Dies ist eine unüberwachte Metrik: keine Kennzeichnungen erforderlich. In unseren Experimenten (veröffentlicht auf der ECIR 2026) erreicht EPR allein bei TriviaQA über vier verschiedene LLMs hinweg ROC-AUC-Werte zwischen 74 und 81. Nicht schlecht für eine Metrik, die abgesehen von einem einzigen Generierungsdurchlauf im Grunde nichts kostet.
Aber wir können es besser machen.
WEPR: Gewichtete Entropieproduktionsrate
Bei der Roh-Entropie werden alle Token-Ränge gleich behandelt. Der Entropiebeitrag des Tokens auf Rang 1 (dem wahrscheinlichsten) und des Tokens auf Rang 10 werden gleich gewichtet. In der Praxis birgt die Art und Weise, wie sich die Unsicherheit auf die Ränge verteilt, diskriminierende Informationen.
WEPR (Weighted EPR) lernt eine Reihe von Gewichten, um diese Beiträge wieder auszugleichen. Es verwendet zwei Signale:
- Die Durchschnitt gewichtete Entropie über die gesamte Sequenz - Erfassung des allgemeinen Zögerns.
- Die maximal Entropiebeitrag pro Rang - Erfassen von Unsicherheitsspitzen. Ein einziger Moment des starken Zögerns kann das Kennzeichen einer Halluzination sein, selbst wenn der Rest der Sequenz sicher erzeugt wurde.
Diese Merkmale werden in eine logistische Regression eingespeist, die auf einem gelabelten dataset trainiert wurde. Die Ausgabe des Sigmoids ist eine kalibrierte Wahrscheinlichkeit:
“Diese Antwort enthält mit einer Wahrscheinlichkeit von 86% eine Halluzination.”
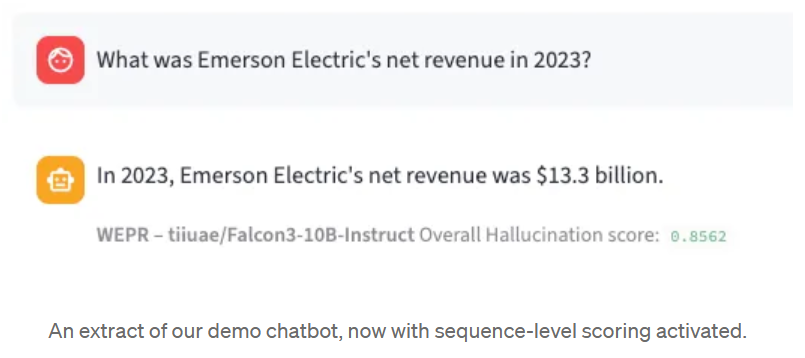
Neben der Klassifizierung erstellt WEPR auch Bewertungen auf Token-Ebene. Jedes Token in der generierten Sequenz erhält seine eigene Halluzinationswahrscheinlichkeit, so dass Sie genau bestimmen können, welche Teile einer Antwort eine genauere Betrachtung verdienen. Die Berechnung erfolgt in Echtzeit, Token für Token, während das Modell generiert - Sie müssen nicht auf die vollständige Ausgabe warten.

Was ist mit Etiketten?
Eine überwachte Methode erfordert Annotationen. Tausende von QA-Paaren von Hand zu beschriften ist langsam. Daher verwenden wir ein LLM-als-Richter Ansatz: ein separates Modell vergleicht jede generierte Antwort mit der bekannten Grundwahrheit und kennzeichnet sie als richtig oder falsch.
Ist das zuverlässig? Wir haben sie anhand von menschlichen Kommentatoren validiert. Eine Gruppe von 15 Forschern hat über 1.300 Antwortpaare von Hand beschriftet. Die Übereinstimmung zwischen dem automatischen Richter und den menschlichen Bewertern erreichte 95,7%, mit einem Cohen's Kappa von 0,90. Die automatischen Kennzeichnungen sind ein zuverlässiger Ersatz für die menschliche Beurteilung und robust genug, um einen Halluzinationsdetektor darauf zu trainieren.
Wir stellen Ihnen artefactual vor: Jetzt sind Sie an der Reihe.
Wir haben all dies in eine Open-Source-Python-Bibliothek gepackt: artefaktisch.
Die Bibliothek wird mit vorberechneten Kalibrierungsgewichten für mehrere Modellfamilien (Mistral-Small, Falcon-3, Phi-4, Ministral-8B) ausgeliefert, so dass Sie sofort mit der Auswertung der Ausgaben beginnen können, ohne eine Trainingspipeline zu starten. Es parst die Ausgaben von vLLM, der OpenAI Chat Completions API und der OpenAI Responses API sofort.
Hier ist die einfachste mögliche Verwendung:

Die Wertungen auf Token-Ebene sind besonders nützlich für die Visualisierung. Jedes Token in der Antwort erhält seine eigene Halluzinationswahrscheinlichkeit, die Sie als Farbverlauf darstellen können, grün für zuversichtlich oder rot für unsicher. So sehen Sie auf einen Blick, welche Teile einer Antwort eine nähere Betrachtung verdienen.
In einer RAG-Pipeline
Praktisch wird dies bei der Retrieval-Augmented Generation. Stellen Sie sich eine Pipeline vor, die Dokumente aus einer Wissensdatenbank abruft und sie als Kontext in ein LLM einspeist. Wenn der Abruf fehlschlägt (falsche Dokumente, fehlende Seiten, unvollständiger Kontext usw.), versucht das Modell, die Lücken aus seinem parametrischen Speicher zu füllen.
Mit artefactual können Sie ein Tor hinzufügen:

Unser wissenschaftlicher Artikel In einer Nussschale - Was wir fanden
Wir haben EPR und WEPR mit vier LLMs (Mistral-Small-24B, Falcon-3-10B, Phi-4, Ministral-8B) bei drei Aufgaben getestet: Erkennung von Halluzinationen bei TriviaQA, Verallgemeinerung auf WebQuestions und Erkennung von fehlendem Kontext in einer Finanz-RAG-Umgebung.
Ein paar Highlights:
- WEPR übertrifft durchweg die bestehenden Methoden. Es schlägt sowohl SelfCheckGPT (eine Multi-Shot-Methode, die das 10-fache an Berechnungen erfordert) als auch HalluDetect (ein Single-Shot-Konkurrent) bei fast allen Modell-dataset-Kombinationen.
- Sie brauchen nicht viele Log-Wahrscheinlichkeiten. Die Leistung pendelt sich bei K = 8-10 zugänglichen Log-Wahrscheinlichkeiten pro Token ein. Selbst bei eingeschränktem API-Zugriff ist das Signal vorhanden.
- Sie verallgemeinert. WEPR, das auf TriviaQA trainiert wurde, lässt sich gut auf WebQuestions und sogar auf einen spezialisierten Finanzkorpus übertragen und erkennt Fälle, in denen ein RAG-System Antworten ohne ausreichenden Kontext generiert.
- Es ist schnell. Das Scoring dauert etwa 80 Mikrosekunden pro Sequenz. Vergleichen Sie das mit >10 Sekunden für SelfCheckGPT.
In unseren Experimenten mit einer Finanz-RAG-Aufgabe (Analyse der jährlichen 10-K reports aus dem ArGiMi-Ardian data-Set) erreichte WEPR einen ROC-AUC von bis zu 93,6 bei der Erkennung von Antworten, die ohne den richtigen Kontext generiert wurden. Dies ist ein starkes Signal für das Auslösen eines zweiten Abrufdurchgangs.
Anmerkung zum Zugriff auf die Log-Wahrscheinlichkeit:
Alles, was oben beschrieben wurde, beruht auf einer Sache: dem Zugriff auf die Log-Wahrscheinlichkeiten des Modells auf Token-Ebene. Damit können wir die Entropie und damit auch die Halluzinationswerte berechnen.
Heute ist dieser Zugriff nicht mehr gewährleistet. Anthropic stellt über seine API keine Log-Wahrscheinlichkeiten zur Verfügung. OpenAI bietet sie für nicht-begründende Modelle an - Sie können top_logprobs mit GPT-5.4 oder GPT-5.4-mini anfordern, aber nur, wenn Sie den Begründungsaufwand auf none setzen. Auf der anderen Seite ermöglicht Google mit seiner generate_content API den Zugriff auf alle logprobs.
Modelle mit offenem Gewicht, die über vLLM oder ähnliche Inferenzmaschinen bedient werden, bieten vollen Zugriff.
Das ist wichtig. Log-Wahrscheinlichkeiten sind ein leichtes, informationsreiches Signal. Ihre Erstellung kostet nichts extra (das Modell berechnet sie ohnehin während der Erstellung) und sie ermöglichen eine ganze Klasse von Methoden zur Quantifizierung der Unsicherheit - unsere eingeschlossen. Wenn Sie den Zugang zu ihnen einschränken, müssen die Benutzer entweder blindem Vertrauen in die Modellergebnisse oder teuren Multi-Shot-Erkennungsmethoden vertrauen.
Wenn Sie mit LLMs in der Produktion arbeiten und Wert auf die Zuverlässigkeit der Ergebnisse legen, sollte die Verfügbarkeit von Log-Wahrscheinlichkeiten Teil Ihrer Modellauswahlkriterien sein. Und wenn Sie ein Modellanbieter sind: Die Offenlegung von Log-Wahrscheinlichkeiten ist eine der kostengünstigsten Möglichkeiten, Ihre Modelle vertrauenswürdiger zu machen.
