


Como a pontuação baseada em entropia pode dizer ao senhor quando o seu modelo está inventando coisas - e onde - embrulhado no artefactual, nosso pacote Python.
Observação: Este artigo é uma continuação do artigo O artigo de nossos amigos da Ardian, detalhando como a IA responsável é crucial para as instituições financeiras. Não deixe de conferir!
O problema da alucinação
Os modelos de linguagem grandes são surpreendentemente capazes. Eles resumem, traduzem, raciocinam e codificam (melhor do que eu). Mas, ao contrário de mim, eles também se tornaram famosos por inventar fatos com uma confiança assustadora.
Na literatura de Processamento de Linguagem Natural (PLN), uma alucinação é qualquer conteúdo gerado por modelo que seja factualmente incorreto, sem sentido ou infiel a uma fonte fornecida, embora pareça perfeitamente plausível. As consequências variam de benignas (uma resposta errada a uma pergunta trivial) a graves (uma citação legal fabricada, uma dosagem incorreta de medicamento). À medida que as organizações integram os LLMs aos sistemas de produção, a questão muda de “Esse modelo pode gerar um texto útil?” para “Podemos confiar no que ele acabou de dizer?”
Considere um exemplo concreto. O senhor trabalha em uma instituição financeira e pergunta ao seu LLM local:
“Qual foi a receita líquida da Emerson Electric em 2023?”
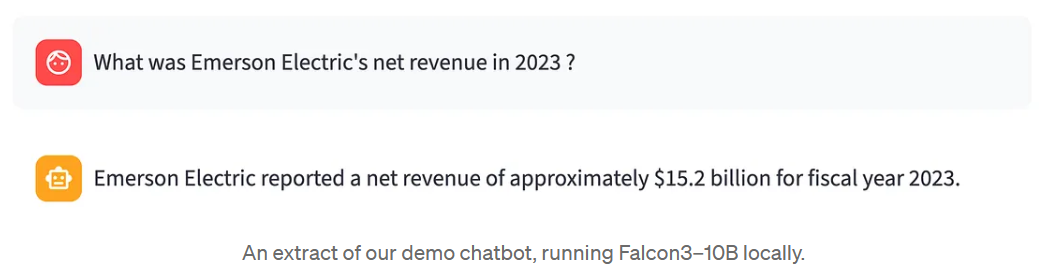
A modelo responde: “A Emerson Electric informou uma receita líquida de aproximadamente $15,2 bilhões para o ano fiscal de 2023.” Parece razoável. Mas será que está certo? O senhor não tem o relatório anual aberto. O senhor não tem uma verdade básica para comparar. O senhor só tem o resultado do modelo - e a dúvida.
Esse é o cenário em que trabalhamos. Sem oráculo. Nenhuma resposta de referência no momento da inferência. Apenas uma resposta LLM e o metadata que ela produz ao gerá-la. O objetivo: quantificar a probabilidade de essa saída ser alucinada, a partir de uma única passagem de geração.
Detectar alucinações: é mais difícil do que parece
A abordagem de força bruta
Uma ideia natural é fazer a mesma pergunta ao modelo várias vezes e verificar se as respostas estão de acordo. Se cinco das seis execuções disserem “$15,2 bilhões” e uma disser “$18,7 bilhões”, o consenso lhe dará alguma confiança. Esse é o princípio por trás de métodos como o SelfCheckGPT, que mede a consistência em vários resultados amostrados - uma abordagem “estilo Monte Carlo” para a detecção de alucinações.
Funciona. Mas tem duas desvantagens significativas:
- Custo. Cada geração adicional multiplica seu orçamento de inferência. Para o SelfCheckGPT com 10 amostras, o senhor paga cerca de 10 vezes a computação, mais o custo de um modelo de similaridade semântica. Em escala, isso é proibitivo.
- Granularidade. Os métodos multi-shot operam no nível da sequência. Eles dizem ao senhor “essa resposta parece não ser confiável”, mas não qual parte da resposta é problemática. Uma resposta pode ser 90% precisa com uma única figura alucinada enterrada no meio. O senhor gostaria de saber onde.
Essas limitações nos motivaram a procurar um sinal diferente, barato, de disparo único e que funcionasse no nível do token (as partes individuais das palavras que o LLM manipula internamente).
O sinal já está lá
Quando um LLM gera texto, ele não produz apenas tokens. Em cada etapa, ele calcula uma distribuição de probabilidade em todo o seu vocabulário: “Considerando o prompt e tudo o que gerei até agora, qual é a probabilidade de cada um dos possíveis próximos tokens?” O token vencedor é amostrado. As demais são descartadas. Mas essas probabilidades (e, mais especificamente, o quanto elas estão espalhadas) contêm informações sobre a confiança interna do modelo.
Se o modelo estiver muito seguro, a maior parte da massa de probabilidade se concentra em um único token. Se o modelo hesitar, a probabilidade se espalha por muitos candidatos. Essa distribuição é exatamente o que a entropia mede.
Entropia: um rápido desvio
A entropia é uma quantidade da teoria da informação que mede a incerteza de uma distribuição de probabilidade. A intuição é simples. Imagine três caixas. Uma delas contém um biscoito. O senhor precisa adivinhar qual delas é.

- Cenário A: O senhor sabe que o biscoito está na caixa 2. Sua incerteza é zero. Entropia = 0.
- Cenário B: O senhor não faz ideia. Cada caixa tem 1/3 de chance. Sua incerteza é máxima. Entropia = log₂(3) ≈ 1,58 bits.
Agora, substitua as caixas por tokens e o cookie pela próxima palavra “correta”. Em cada etapa de geração, um LLM enfrenta essa escolha exata - exceto que, em vez de 3 caixas, ele escolhe entre um vocabulário de mais de 100.000 tokens. Quando o modelo está confiante, um token domina e a entropia é baixa. Quando ele hesita, a entropia aumenta.
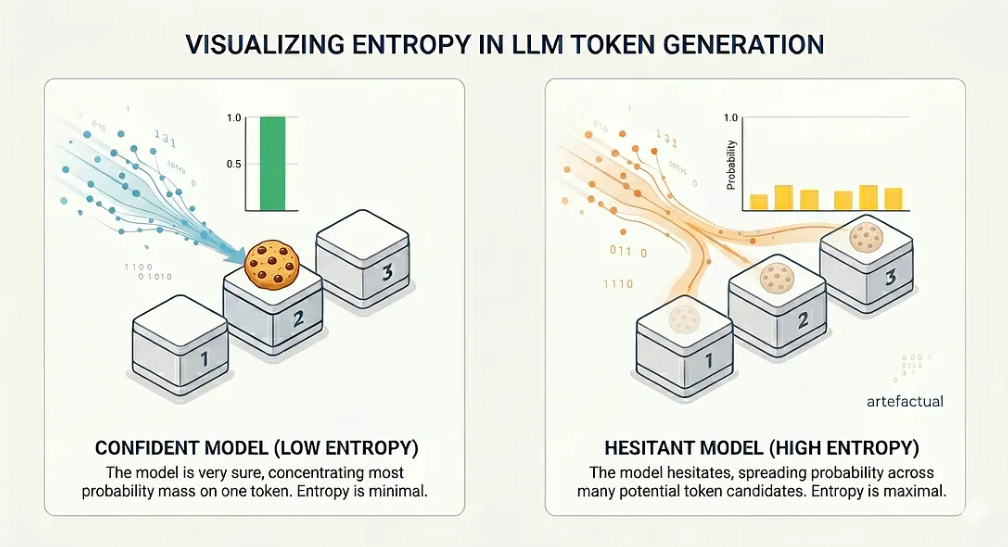
A distribuição de probabilidade se espalhou em dois casos diferentes.
O principal insight é que a alta entropia em uma determinada posição de token está correlacionada com uma maior probabilidade de erro nessa posição. O modelo está dizendo ao senhor, por meio de sua distribuição de probabilidade, que ele não tem certeza do que virá a seguir. Só precisamos ouvir.
Da entropia às pontuações de alucinação
EPR: Taxa de produção de entropia
Nossa primeira métrica, EPR (Entropy Production Rate), é direta. Para cada token na sequência gerada, calculamos a entropia das principais K probabilidades de token previstas pelo modelo. Em seguida, calculamos a média da sequência. Isso gera um único número que reflete a hesitação média do modelo em relação à resposta completa.
Essa é uma métrica não supervisionada: não são necessários rótulos. Em nossos experimentos (publicados no ECIR 2026), o EPR sozinho atinge pontuações ROC-AUC entre 74 e 81 no TriviaQA em quatro LLMs diferentes. Nada mal para uma métrica que não custa essencialmente nada além de uma única passagem de geração.
Mas podemos fazer melhor.
WEPR: Weighted Entropy Production Rate (taxa de produção de entropia ponderada)
A entropia bruta trata todas as classificações de tokens igualmente. A contribuição de entropia do token classificado em primeiro lugar (o mais provável) e do token classificado em décimo lugar têm o mesmo peso. Na prática, a maneira como a incerteza é distribuída entre as classificações traz informações discriminatórias.
O WEPR (Weighted EPR) aprende um conjunto de pesos para reequilibrar essas contribuições. Ele usa dois sinais:
- O média entropia ponderada em toda a sequência - capturando a hesitação geral.
- O máximo contribuição de entropia por classificação - capturando picos de incerteza. Um único momento de alta hesitação pode ser a marca registrada de uma alucinação, mesmo que o restante da sequência tenha sido gerado com confiança.
Esses recursos são inseridos em uma regressão logística, treinada em um dataset rotulado. A saída do sigmoide é uma probabilidade calibrada:
“Esta resposta tem uma probabilidade de 86% de conter uma alucinação.”
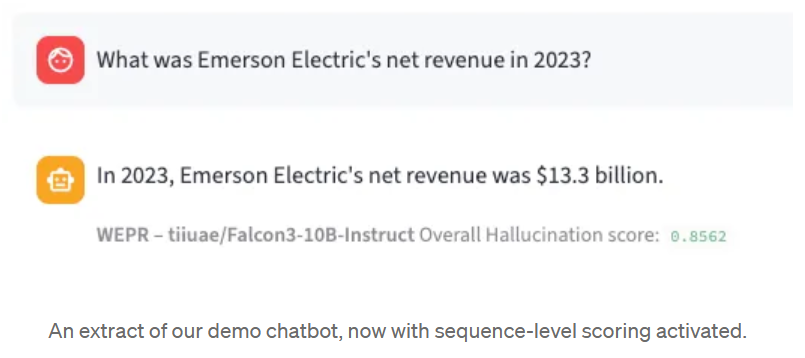
Além da classificação, o WEPR também produz pontuações em nível de token. Cada token na sequência gerada recebe sua própria probabilidade de alucinação, permitindo que o senhor identifique exatamente quais partes de uma resposta merecem ser examinadas. Isso é calculado em tempo real, token por token, à medida que o modelo é gerado - não há necessidade de esperar pelo resultado completo.

E quanto aos rótulos?
Um método supervisionado requer anotações. A rotulagem manual de milhares de pares de QA é lenta. Por isso, usamos um LLM como juiz abordagem: um modelo separado compara cada resposta gerada com a verdade básica conhecida e a rotula como correta ou incorreta.
Isso é confiável? Nós o validamos com anotadores humanos. Um grupo de 15 pesquisadores rotulou manualmente mais de 1.300 pares de respostas. A concordância entre o juiz automatizado e os avaliadores humanos atingiu 95,7%, com um Kappa de Cohen de 0,90. Os rótulos automatizados são um substituto confiável para o julgamento humano e são robustos o suficiente para treinar um detector de alucinação.
Apresentando o artefactual: agora é a vez do senhor jogar.
Empacotamos tudo isso em uma biblioteca Python de código aberto: artefatual.
A biblioteca é fornecida com pesos de calibração pré-computados para várias famílias de modelos (Mistral-Small, Falcon-3, Phi-4, Ministral-8B), para que o senhor possa começar a pontuar os resultados imediatamente sem executar nenhum pipeline de treinamento. Ele analisa os resultados do vLLM, da API OpenAI Chat Completions e da API OpenAI Responses imediatamente.
Aqui está o uso mais simples possível:

As pontuações em nível de token são particularmente úteis para visualização. Cada token na resposta recebe sua própria probabilidade de alucinação, que o senhor pode apresentar como um gradiente de cores, verde para confiante ou vermelho para incerto. Em um relance, o senhor vê exatamente quais partes de uma resposta merecem ser examinadas.
Em um pipeline RAG
Isso se torna prático na Geração Aumentada por Recuperação. Imagine um pipeline que recupera documentos de uma base de conhecimento e os alimenta como contexto para um LLM. Se a recuperação falhar (documentos errados, páginas faltantes, contexto incompleto etc.), o modelo tentará preencher as lacunas a partir de sua memória paramétrica, e é aí que surgem as alucinações.
Com o artefactual, o senhor pode adicionar um portão:

Nosso artigo científico em poucas palavras - O que descobrimos
Testamos a EPR e a WEPR em quatro LLMs (Mistral-Small-24B, Falcon-3-10B, Phi-4, Ministral-8B) em três tarefas: detecção de alucinação no TriviaQA, generalização para WebQuestions e detecção de contexto ausente em um cenário de RAG financeiro.
Alguns destaques:
- O WEPR supera consistentemente os métodos existentes. Ele supera o SelfCheckGPT (um método de várias tentativas que exige 10 vezes mais computação) e o HalluDetect (um concorrente de uma única tentativa) em quase todas as combinações de modelo-dataset.
- O senhor não precisa de muitas probabilidades de log. O desempenho atinge um patamar em torno de K = 8-10 probabilidades de registro acessíveis por token. Mesmo com acesso limitado à API, o sinal está lá.
- Ele generaliza. O WEPR treinado no TriviaQA é bem transferido para o WebQuestions e até mesmo para um corpus financeiro especializado, detectando casos em que um sistema RAG gerou respostas sem contexto suficiente.
- É rápido. A pontuação leva cerca de 80 microssegundos por sequência. Compare isso com mais de 10 segundos para o SelfCheckGPT.
Em nossos experimentos em uma tarefa RAG financeira (analisando o reports anual 10-K do conjunto ArGiMi-Ardian data), o WEPR atingiu até 93,6 ROC-AUC na detecção de respostas geradas sem o contexto correto. Esse é um sinal forte para acionar uma segunda passagem de recuperação.
Observação sobre o acesso à probabilidade de registro:
Tudo o que foi descrito acima depende de uma coisa: acesso às probabilidades de registro em nível de token do modelo. É isso que nos permite calcular a entropia e, por extensão, as pontuações de alucinação.
Atualmente, esse acesso não é garantido. O Anthropic não expõe as probabilidades de log por meio de sua API. A OpenAI as fornece para modelos sem raciocínio - o senhor pode solicitar top_logprobs com GPT-5.4 ou GPT-5.4-mini, mas somente se definir o esforço de raciocínio como none . Por outro lado, o Google permite o acesso a todos os logprobs com sua API generate_content.
Os modelos de peso aberto servidos pelo vLLM ou por mecanismos de inferência semelhantes oferecem acesso total.
Isso é importante. As probabilidades logarítmicas são um sinal leve e rico em informações. Elas não custam nada a mais para serem produzidas (o modelo as calcula de qualquer forma durante a geração) e permitem toda uma classe de métodos de quantificação de incerteza - inclusive o nosso. Restringir o acesso a elas faz com que os usuários confiem cegamente nos resultados do modelo ou em métodos caros de detecção de múltiplos disparos.
Se o senhor trabalha com LLMs na produção e se preocupa com a confiabilidade dos resultados, a disponibilidade das probabilidades de log deve fazer parte dos critérios de seleção de modelos. E se o senhor for um fornecedor de modelos: expor as probabilidades de log é uma das maneiras mais baratas de tornar seus modelos mais confiáveis.
