


Cómo la puntuación basada en la entropía puede decirle cuándo su modelo está inventando cosas - y dónde - envuelto en artefactual, nuestro paquete Python.
Nota: Este artículo es una continuación de el artículo de nuestros amigos de Ardian, en el que se detalla lo crucial que es la IA responsable para las instituciones financieras. ¡No deje de consultarlo!
El problema de la alucinación
Los modelos de lenguaje grandes son asombrosamente capaces. Resumen, traducen, razonan y programan (mejor que yo). Pero a diferencia de mí, también se han hecho notorios por inventar hechos con una confianza inquietante.
En la literatura del Procesamiento del Lenguaje Natural (PLN), una alucinación es cualquier contenido generado por un modelo que sea incorrecto en cuanto a los hechos, disparatado o infiel a una fuente proporcionada, aunque parezca perfectamente verosímil. Las consecuencias van desde benignas (una respuesta errónea a un trivial) hasta graves (una cita legal inventada, una dosis incorrecta de un medicamento). A medida que las organizaciones integran los LLM en los sistemas de producción, la cuestión pasa de “¿Puede este modelo generar un texto útil?” a “¿podemos fiarnos de lo que acaba de decir?”
Considere un ejemplo concreto. Usted trabaja en una institución financiera y pregunta a su LLM local:
“¿Cuáles fueron los ingresos netos de Emerson Electric en 2023?”
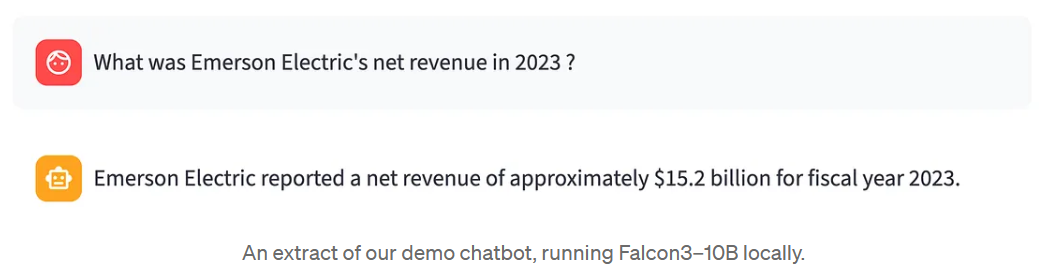
La modelo responde: “Emerson Electric informó de unos ingresos netos de aproximadamente $15.200 millones para el año fiscal 2023”.” Suena razonable. ¿Pero es correcto? No tiene el informe anual abierto. No tiene una verdad de base con la que comparar. Sólo tiene el resultado del modelo... y la duda.
Este es el escenario en el que trabajamos. Sin oráculo. Ninguna respuesta de referencia en el momento de la inferencia. Sólo una respuesta LLM y el metadata que produce al generarla. El objetivo: cuantificar la probabilidad de que esta salida sea alucinada, a partir de un único pase de generación.
Detectar alucinaciones: es más difícil de lo que parece
El enfoque de fuerza bruta
Una idea natural es hacer la misma pregunta al modelo varias veces y comprobar si las respuestas coinciden. Si cinco de seis ejecuciones dicen “$15.200 millones” y una dice “$18.700 millones”, el consenso le da cierta confianza. Este es el principio en el que se basan métodos como SelfCheckGPT, que miden la coherencia entre varias salidas muestreadas: un enfoque “estilo Montecarlo” para la detección de alucinaciones.
Funciona. Pero tiene dos inconvenientes importantes:
- Coste. Cada generación adicional multiplica su presupuesto de inferencia. Para SelfCheckGPT con 10 muestras, usted paga aproximadamente 10 veces el cálculo, más el coste de un modelo de similitud semántica por encima. A escala, esto es prohibitivo.
- Granularidad. Los métodos multidisparo operan a nivel de secuencia. Le dicen “esta respuesta parece poco fiable”, pero no qué parte de la respuesta es problemática. Una respuesta podría ser 90% exacta con una única figura alucinada enterrada en el medio. Le gustaría saber dónde.
Estas limitaciones nos motivaron a buscar una señal diferente, que fuera barata, de un solo disparo y que funcionara a nivel de token (los fragmentos individuales de palabras que el LLM manipula internamente).
La señal ya está ahí
Cuando un LLM genera texto, no se limita a emitir tokens. En cada paso, calcula una distribución de probabilidad sobre todo su vocabulario: “Teniendo en cuenta la indicación y todo lo que he generado hasta ahora, ¿cuál es la probabilidad de cada posible ficha siguiente?” La ficha ganadora se muestrea. El resto se descartan. Pero esas probabilidades (y más concretamente, lo repartidas que están) llevan información sobre la confianza interna del modelo.
Si el modelo está muy seguro, la mayor parte de la masa de probabilidad se concentra en una sola ficha. Si el modelo duda, la probabilidad se reparte entre muchos candidatos. Esta dispersión es exactamente lo que mide la entropía.
Entropía: un desvío rápido
La entropía es una magnitud teórica de la información que mide la incertidumbre de una distribución de probabilidad. La intuición es sencilla. Imagine tres cajas. Una contiene una galleta. Tiene que adivinar cuál.

- Escenario A: Usted sabe que la galleta está en la caja 2. Su incertidumbre es cero. Entropía = 0.
- Escenario B: No tiene ni idea. Cada casilla tiene una probabilidad de 1/3. Su incertidumbre es máxima. Entropía = log₂(3) ≈ 1,58 bits.
Ahora sustituya las casillas por tokens y la galleta por la palabra siguiente “correcta”. En cada paso de generación, un LLM se enfrenta a esta elección exacta - excepto que en lugar de 3 casillas, elige entre un vocabulario de más de 100.000 tokens. Cuando el modelo está seguro, un token domina y la entropía es baja. Cuando duda, la entropía aumenta.
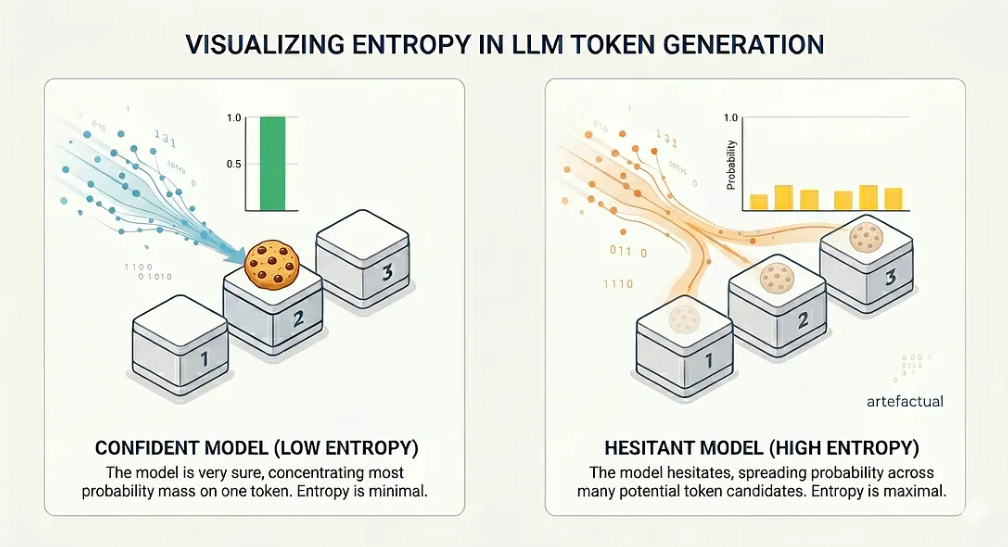
La distribución de probabilidad se extiende en dos casos diferentes.
La idea clave es que una entropía elevada en una posición dada de la ficha se correlaciona con una mayor probabilidad de error en esa posición. El modelo nos está diciendo, a través de su distribución de probabilidades, que no está seguro de lo que viene a continuación. Sólo tenemos que escuchar.
De la entropía a las puntuaciones de alucinación
EPR: Tasa de producción de entropía
Nuestra primera métrica, la EPR (tasa de producción de entropía), es directa. Para cada token de la secuencia generada, calculamos la entropía de las K probabilidades de token predichas más altas del modelo. A continuación, hacemos la media de toda la secuencia. Esto da un único número que refleja la vacilación media del modelo sobre la respuesta completa.
Se trata de una métrica no supervisada: no requiere etiquetas. En nuestros experimentos (publicados en ECIR 2026), la EPR por sí sola alcanza puntuaciones ROC-AUC de entre 74 y 81 en TriviaQA a través de cuatro LLM diferentes. No está mal para una métrica que no cuesta esencialmente nada más allá de un único pase de generación.
Pero podemos hacerlo mejor.
WEPR: Tasa de producción de entropía ponderada
La entropía bruta trata todos los rangos de tokens por igual. La contribución a la entropía del token clasificado en primer lugar (el más probable) y del token clasificado en décimo lugar se ponderan igual. En la práctica, la forma en que la incertidumbre se distribuye entre los rangos conlleva información discriminatoria.
La WEPR (EPR ponderada) aprende un conjunto de ponderaciones para reequilibrar estas contribuciones. Utiliza dos señales:
- El media entropía ponderada a lo largo de la secuencia - capturando la vacilación general.
- El máximo contribución de entropía por rango: captar los picos de incertidumbre. Un único momento de gran vacilación puede ser el sello distintivo de una alucinación, aunque el resto de la secuencia se haya generado con confianza.
Estas características se introducen en una regresión logística, entrenada en un conjunto data etiquetado. La salida de la sigmoide es una probabilidad calibrada:
“Esta respuesta tiene una probabilidad 86% de contener una alucinación”.”
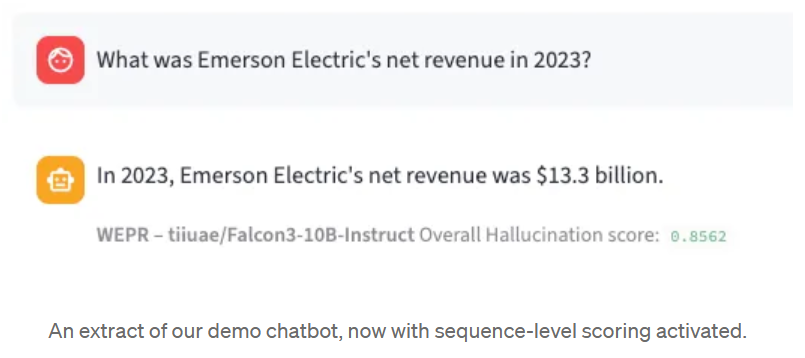
Más allá de la clasificación, WEPR también produce puntuaciones a nivel de token. Cada token de la secuencia generada recibe su propia probabilidad de alucinación, lo que le permite señalar exactamente qué partes de una respuesta merecen ser examinadas. Esto se computa en tiempo real, token por token, a medida que el modelo genera - sin necesidad de esperar a la salida completa.

¿Y las etiquetas?
Un método supervisado requiere anotaciones. Etiquetar a mano miles de pares de GC es lento. Así que utilizamos un LLM como juez enfoque: un modelo independiente compara cada respuesta generada con la verdad del terreno conocida y la etiqueta como correcta o incorrecta.
¿Es fiable? Lo validamos con anotadores humanos. Un grupo de 15 investigadores etiquetó a mano más de 1.300 pares de respuestas. El acuerdo entre el juez automatizado y los evaluadores humanos alcanzó el 95,7%, con un Kappa de Cohen de 0,90. Las etiquetas automatizadas son un sustituto fiable del juicio humano y son lo suficientemente sólidas como para entrenar un detector de alucinaciones con ellas.
Presentamos artefactual: ahora le toca jugar a usted.
Hemos empaquetado todo esto en una biblioteca Python de código abierto: artefactual.
La biblioteca se suministra con pesos de calibración precalculados para varias familias de modelos (Mistral-Small, Falcon-3, Phi-4, Ministral-8B), por lo que puede empezar a puntuar las salidas inmediatamente sin necesidad de ejecutar ningún proceso de formación. Analiza los resultados de vLLM, la API de finalización de conversaciones de OpenAI y la API de respuestas de OpenAI.
He aquí el uso más sencillo posible:

Las puntuaciones a nivel de token son especialmente útiles para la visualización. Cada token de la respuesta recibe su propia probabilidad de alucinación, que puede representar como un gradiente de color, verde para seguro o rojo para incierto. De un vistazo, verá exactamente qué partes de una respuesta merecen ser examinadas.
En una tubería RAG
Donde esto se vuelve práctico es en la generación mejorada por recuperación. Imagine una tubería que recupera documentos de una base de conocimientos y los alimenta como contexto a un LLM. Si la recuperación falla (documentos erróneos, páginas que faltan, contexto incompleto, etc.) el modelo intentará rellenar los huecos a partir de su memoria paramétrica, y ahí es donde aparecen las alucinaciones.
Con artefactual, puede añadir una puerta:

Nuestro artículo científico En pocas palabras - Lo que encontramos
Probamos la EPR y la WEPR en cuatro LLM (Mistral-Small-24B, Falcon-3-10B, Phi-4, Ministral-8B) en tres tareas: detección de alucinaciones en TriviaQA, generalización a WebQuestions y detección de contextos perdidos en un entorno de RAG financiero.
Algunos puntos destacados:
- La WEPR supera sistemáticamente a los métodos existentes. Supera tanto a SelfCheckGPT (un método multidisparo que requiere 10 veces más cálculo) como a HalluDetect (un competidor de disparo único) en casi todas las combinaciones modelo-dataset.
- No necesita muchas log-probabilidades. El rendimiento se estabiliza en torno a K = 8-10 log-probabilidades accesibles por token. Incluso con un acceso limitado a la API, la señal está ahí.
- Generaliza. WEPR entrenado en TriviaQA se transfiere bien a WebQuestions e incluso a un corpus financiero especializado, detectando casos en los que un sistema RAG generaba respuestas sin suficiente contexto.
- Es rápido. La puntuación tarda aproximadamente 80 microsegundos por secuencia. Compárelo con los >10 segundos de SelfCheckGPT.
En nuestros experimentos sobre una tarea RAG financiera (analizando 10-K anuales reports del conjunto ArGiMi-Ardian data), WEPR alcanzó hasta 93,6 ROC-AUC en la detección de respuestas generadas sin el contexto adecuado. Se trata de una señal fuerte para activar una segunda pasada de recuperación.
Nota sobre el acceso log-probabilidad:
Todo lo descrito anteriormente depende de una cosa: el acceso a las probabilidades de registro a nivel de testigo del modelo. Esto es lo que nos permite calcular la entropía y, por extensión, las puntuaciones de alucinación.
Hoy en día, este acceso no está garantizado. Anthropic no expone log-probabilities a través de su API. OpenAI las proporciona para los modelos sin razonamiento - puede solicitar top_logprobs con GPT-5.4 o GPT-5.4-mini, pero sólo si establece el esfuerzo de razonamiento en ninguno . Por otro lado, Google permite acceder a todos los logprobs con su API generate_content.
Los modelos de peso abierto servidos a través de vLLM o motores de inferencia similares dan acceso completo.
Esto es importante. Las probabilidades logarítmicas son una señal ligera y rica en información. No cuesta nada producirlas (el modelo las calcula de todos modos durante la generación) y permiten toda una clase de métodos de cuantificación de la incertidumbre, el nuestro incluido. Restringir el acceso a ellas empuja a los usuarios hacia una confianza ciega en los resultados de los modelos o hacia costosos métodos de detección de disparos múltiples.
Si trabaja con LLM en producción y le preocupa la fiabilidad de los resultados, la disponibilidad de las log-probabilidades debería formar parte de sus criterios de selección de modelos. Y si usted es un proveedor de modelos: exponer las log-probabilidades es una de las formas más baratas de hacer que sus modelos sean más fiables.
