


Comment la notation basée sur l'entropie peut vous indiquer quand votre modèle invente des choses - et où - enveloppé dans artefactual, notre paquetage Python.
Note : Cet article fait suite à l'article de nos amis d'Ardian, La Commission européenne a publié un article dans lequel elle explique en détail l'importance de l'IA pour les institutions financières. Ne manquez pas de le consulter !
Le problème des hallucinations
Les grands modèles linguistiques sont étonnamment capables. Ils résument, traduisent, raisonnent et codent (mieux que moi). Mais contrairement à moi, ils sont également devenus célèbres pour avoir inventé des faits avec une confiance déconcertante.
Dans la littérature sur le traitement du langage naturel (NLP), une hallucination est un contenu généré par un modèle qui est factuellement incorrect, absurde ou infidèle à une source fournie, tout en paraissant parfaitement plausible. Les conséquences peuvent être bénignes (une mauvaise réponse à un jeu-questionnaire) ou graves (une citation juridique fabriquée de toutes pièces, une posologie de médicament incorrecte). Au fur et à mesure que les organisations intègrent les LLM dans les systèmes de production, la question se déplace de “Ce modèle peut-il générer un texte utile ?” à “Peut-on se fier à ce qu'il vient de dire ?”
Prenons un exemple concret. Vous travaillez dans une institution financière et vous demandez à votre LLM local :
“Quel a été le chiffre d'affaires net d'Emerson Electric en 2023 ?”
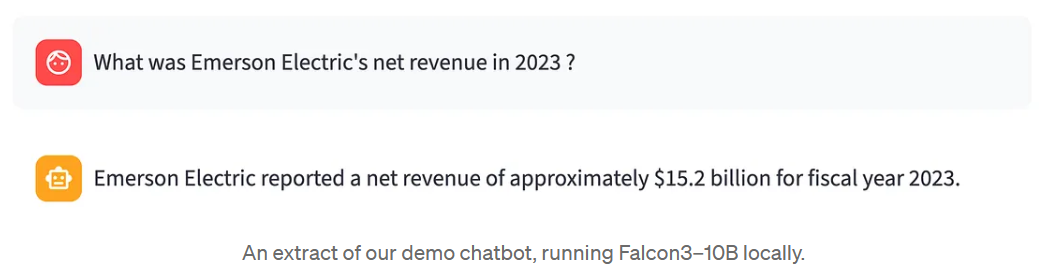
Le modèle répond : “Emerson Electric a déclaré un revenu net d'environ $15,2 milliards pour l'année fiscale 2023.” Cela semble raisonnable. Mais est-ce bien le cas ? Vous n'avez pas le rapport annuel ouvert. Vous n'avez pas de vérité de base à laquelle comparer. Vous n'avez que les résultats du modèle - et des doutes.
C'est dans ce cadre que nous travaillons. Pas d'oracle. Pas de réponse de référence au moment de l'inférence. Juste une réponse LLM et la métadata qu'elle produit en la générant. Le but : quantifier la probabilité que cette sortie soit hallucinée, à partir d'une seule passe de génération.
Détecter les hallucinations : c'est plus difficile qu'il n'y paraît
L'approche par la force brute
Une idée naturelle consiste à poser plusieurs fois la même question au modèle et à vérifier si les réponses concordent. Si cinq des six exécutions disent “$15,2 milliards” et une “$18,7 milliards”, le consensus vous donne une certaine confiance. C'est le principe qui sous-tend des méthodes telles que SelfCheckGPT, qui mesurent la cohérence entre plusieurs résultats échantillonnés - une approche “de type Monte Carlo” de la détection des hallucinations.
Cela fonctionne. Mais il présente deux inconvénients majeurs :
- Coût. Chaque génération supplémentaire multiplie votre budget d'inférence. Pour SelfCheckGPT avec 10 échantillons, vous payez environ 10 fois le calcul, plus le coût d'un modèle de similarité sémantique. À grande échelle, ce coût est prohibitif.
- Granularité. Les méthodes à tirs multiples opèrent au niveau de la séquence. Elles vous disent “cette réponse ne semble pas fiable”, mais pas quelle partie de la réponse pose problème. Une réponse peut être 90% exacte avec une seule figure hallucinée enfouie au milieu. Vous aimeriez savoir où.
Ces limitations nous ont incités à rechercher un signal différent - un signal bon marché, à prise unique et fonctionnant au niveau des jetons (les morceaux individuels de mots que le LLM manipule en interne).
Le signal est déjà là
Lorsqu'un LLM génère du texte, il ne se contente pas de produire des tokens. À chaque étape, il calcule une distribution de probabilité sur l'ensemble de son vocabulaire : “Compte tenu de l'invitation et de tout ce que j'ai généré jusqu'à présent, quelle est la probabilité de chacun des prochains jetons possibles ?” Le jeton gagnant est échantillonné. Les autres sont rejetés. Mais ces probabilités (et plus précisément leur dispersion) sont porteuses d'informations sur la confiance interne du modèle.
Si le modèle est très sûr, la majeure partie de la masse de probabilité se concentre sur un seul jeton. Si le modèle hésite, la probabilité se répartit entre plusieurs candidats. Cette dispersion est exactement ce que mesure l'entropie.
Entropie : un petit détour
L'entropie est une grandeur de la théorie de l'information qui mesure l'incertitude d'une distribution de probabilité. L'intuition est simple. Imaginez trois boîtes. L'une d'elles contient un biscuit. Vous devez deviner laquelle.

- Scénario A : Vous savez que le biscuit se trouve dans la boîte 2. Votre incertitude est nulle. Entropie = 0.
- Scénario B : Vous n'en avez aucune idée. Chaque boîte a un tiers de chances. Votre incertitude est maximale. Entropie = log₂(3) ≈ 1,58 bits.
Remplacez maintenant les boîtes par des tokens et le cookie par le “bon” mot suivant. À chaque étape de la génération, un LLM est confronté à ce choix exact - sauf qu'au lieu de 3 boîtes, il choisit parmi un vocabulaire de plus de 100 000 jetons. Lorsque le modèle est confiant, un mot domine et l'entropie est faible. Lorsqu'il hésite, l'entropie augmente.
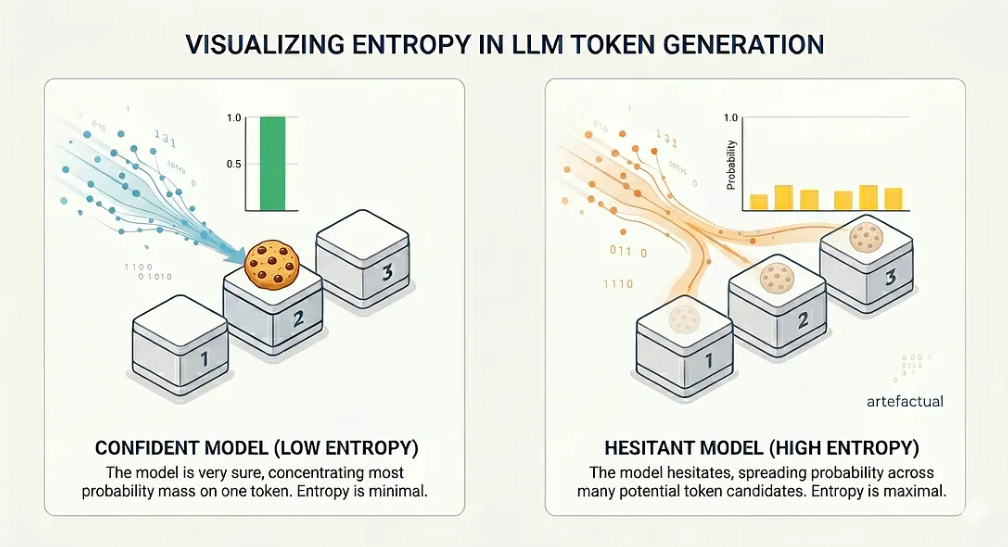
La distribution de probabilité s'étend dans deux cas différents.
L'idée clé est qu'une entropie élevée à une position donnée du jeton est en corrélation avec une probabilité d'erreur plus élevée à cette position. Le modèle vous dit, par le biais de sa distribution de probabilités, qu'il n'est pas sûr de ce qui va suivre. Il suffit de l'écouter.
De l'entropie aux scores d'hallucination
EPR : Taux de production d'entropie
Notre première mesure, EPR (Entropy Production Rate), est directe. Pour chaque jeton de la séquence générée, nous calculons l'entropie des K premières probabilités de jeton prédites par le modèle. Nous calculons ensuite la moyenne sur l'ensemble de la séquence. Nous obtenons ainsi un chiffre unique reflétant l'hésitation moyenne du modèle sur l'ensemble de la réponse.
Il s'agit d'une mesure non supervisée : aucune étiquette n'est nécessaire. Dans nos expériences (publiées à ECIR 2026), EPR seul atteint des scores ROC-AUC entre 74 et 81 sur TriviaQA à travers quatre LLM différents. Ce n'est pas mal pour une métrique qui ne coûte pratiquement rien au-delà d'une seule passe de génération.
Mais nous pouvons faire mieux.
WEPR : Taux de production d'entropie pondérée
L'entropie brute traite tous les rangs des jetons de la même manière. La contribution à l'entropie du jeton classé au premier rang (le plus probable) et celle du jeton classé au dixième rang sont pondérées de la même manière. Dans la pratique, la manière dont l'incertitude se répartit entre les rangs est porteuse d'informations discriminantes.
WEPR (EPR pondéré) apprend un ensemble de poids pour rééquilibrer ces contributions. Il utilise deux signaux :
- Au sein du moyenne l'entropie pondérée sur l'ensemble de la séquence, qui reflète l'hésitation générale.
- Au sein du maximum contribution de l'entropie par rang - capture des pics d'incertitude. Un seul moment de forte hésitation peut être la marque d'une hallucination, même si le reste de la séquence a été généré en toute confiance.
Ces caractéristiques sont introduites dans une régression logistique, entraînée sur un ensemble 1TP41 étiqueté. La sortie de la sigmoïde est une probabilité calibrée :
“Cette réponse a une probabilité de 86% de contenir une hallucination.”
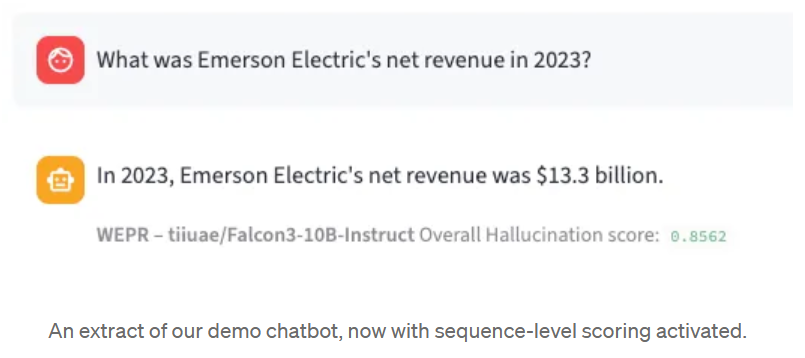
Au-delà de la classification, WEPR produit également des scores au niveau des jetons. Chaque jeton de la séquence générée reçoit sa propre probabilité d'hallucination, ce qui vous permet de déterminer exactement quelles parties d'une réponse méritent d'être examinées. Cette probabilité est calculée en temps réel, jeton par jeton, au fur et à mesure que le modèle est généré - il n'est pas nécessaire d'attendre la sortie complète.

Qu'en est-il des étiquettes ?
Une méthode supervisée nécessite des annotations. L'étiquetage de milliers de paires d'AQ à la main est lent. Nous utilisons donc un LLM en tant que juge un modèle distinct compare chaque réponse générée à la vérité de terrain connue et la qualifie de correcte ou incorrecte.
Est-ce fiable ? Nous l'avons validé par rapport à des annotateurs humains. Un groupe de 15 chercheurs a étiqueté à la main plus de 1 300 paires de réponses. L'accord entre le juge automatisé et les évaluateurs humains a atteint 95,7%, avec un Kappa de Cohen de 0,90. Les étiquettes automatisées sont une approximation fiable du jugement humain et sont suffisamment robustes pour former un détecteur d'hallucinations.
Présentation d'artefactual : c'est maintenant à vous de jouer.
Nous avons intégré tout cela dans une bibliothèque Python à code source ouvert : artefactuel.
La bibliothèque est livrée avec des poids d'étalonnage précalculés pour plusieurs familles de modèles (Mistral-Small, Falcon-3, Phi-4, Ministral-8B), de sorte que vous pouvez commencer à évaluer les résultats immédiatement sans exécuter de pipeline d'apprentissage. Elle analyse les sorties de vLLM, de l'API OpenAI Chat Completions et de l'API OpenAI Responses.
Voici l'utilisation la plus simple possible :

Les scores au niveau des jetons sont particulièrement utiles pour la visualisation. Chaque jeton de la réponse reçoit sa propre probabilité d'hallucination, que vous pouvez représenter sous forme de gradient de couleur, vert pour confiant ou rouge pour incertain. En un coup d'œil, vous voyez exactement quelles parties d'une réponse méritent d'être examinées de près.
Dans une canalisation RAG
C'est dans le cadre de la génération assistée par récupération que cela devient pratique. Imaginez un pipeline qui extrait des documents d'une base de connaissances et les transmet en tant que contexte à un LLM. Si l'extraction échoue (mauvais documents, pages manquantes, contexte incomplet, etc.), le modèle tentera de combler les lacunes à partir de sa mémoire paramétrique, et c'est là que les hallucinations font leur apparition.
Avec l'artefactuel, vous pouvez ajouter un portail :

Notre article scientifique en bref - Ce que nous avons trouvé
Nous avons testé EPR et WEPR sur quatre LLM (Mistral-Small-24B, Falcon-3-10B, Phi-4, Ministral-8B) sur trois tâches : détection d'hallucinations sur TriviaQA, généralisation aux WebQuestions, et détection de contextes manquants dans un contexte financier RAG.
Quelques points forts :
- WEPR surpasse systématiquement les méthodes existantes. Elle surpasse à la fois SelfCheckGPT (une méthode multi-coup nécessitant 10 fois plus de calculs) et HalluDetect (un concurrent à coup unique) pour presque toutes les combinaisons modèle-dataset.
- Vous n'avez pas besoin de beaucoup de probabilités logarithmiques. Les performances plafonnent autour de K = 8-10 log-probabilités accessibles par jeton. Même avec un accès limité à l'API, le signal est là.
- Elle se généralise. WEPR formé sur TriviaQA s'applique bien aux questions Web et même à un corpus financier spécialisé, détectant les cas où un système RAG a généré des réponses sans contexte suffisant.
- C'est rapide. La notation prend environ 80 microsecondes par séquence. Comparez cela à plus de 10 secondes pour le SelfCheckGPT.
Dans nos expériences sur une tâche de RAG financier (analyse de 10-K annuel reports de l'ensemble ArGiMi-Ardian data), WEPR a atteint jusqu'à 93,6 ROC-AUC dans la détection des réponses générées sans le bon contexte. Il s'agit d'un signal fort pour déclencher une deuxième passe d'extraction.
Note sur l'accès à la log-probabilité :
Tout ce qui est décrit ci-dessus repose sur une chose : l'accès aux probabilités de log du modèle au niveau du jeton. C'est ce qui nous permet de calculer l'entropie et, par extension, les scores d'hallucination.
Aujourd'hui, cet accès n'est pas garanti. Anthropic n'expose pas les log-probabilités à travers son API. OpenAI les fournit pour les modèles sans raisonnement - vous pouvez demander top_logprobs avec GPT-5.4 ou GPT-5.4-mini, mais seulement si vous réglez l'effort de raisonnement sur none . D'autre part, Google permet l'accès à tous les logprobs avec son API generate_content.
Les modèles à poids ouvert servis par vLLM ou des moteurs d'inférence similaires donnent un accès complet.
C'est important. Les log-probabilités sont un signal léger et riche en informations. Leur production ne coûte rien de plus (le modèle les calcule de toute façon lors de la génération) et elles permettent toute une série de méthodes de quantification de l'incertitude, dont la nôtre. En restreignant l'accès à ces signaux, on pousse les utilisateurs à faire une confiance aveugle aux résultats des modèles ou à recourir à des méthodes de détection coûteuses à plusieurs niveaux.
Si vous travaillez avec des LLM en production et que vous vous souciez de la fiabilité des résultats, la disponibilité des log-probabilités devrait faire partie de vos critères de sélection des modèles. Et si vous êtes un fournisseur de modèles : l'exposition des log-probabilités est l'un des moyens les moins coûteux de rendre vos modèles plus fiables.
