
")

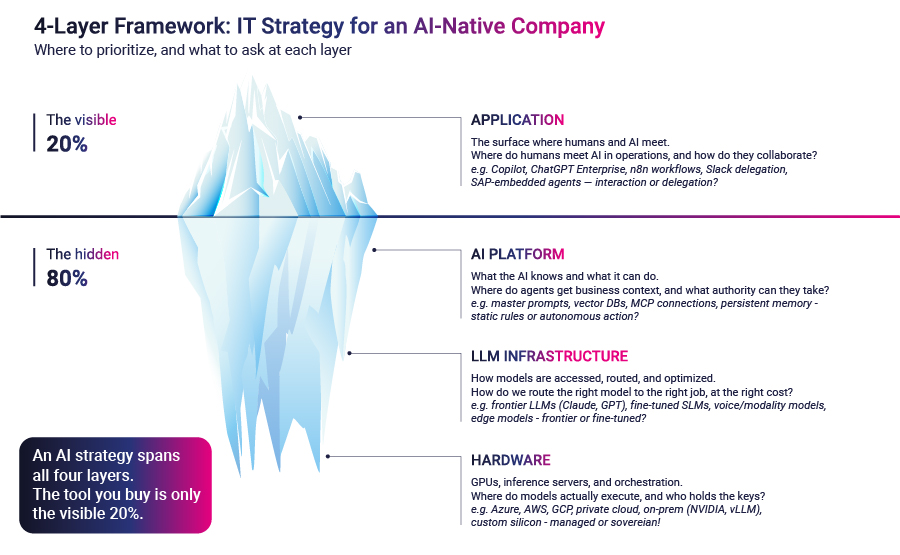
Most CTOs in 2026 are designing AI strategy at the visible layer of the stack. They are buying Copilot seats, rolling out enterprise chatbots, and assembling a portfolio of vendor licenses. The work is real, and in many companies it has produced a measurable bump in productivity. It is also, on any honest reading of the picture, the 20% of the iceberg that everyone can see. The 80% that sits below the waterline is where an agentic organization actually gets built. Teams that never look down there will keep paying for chatbots while their competitors quietly become something else.
The architecture of an AI-native company sits in four layers: Application, AI Platform, LLM Infrastructure, and Hardware. The Application layer is the one most boards have already discussed. The other three are where the real strategic decisions of the next 24 months will be made.
The Application layer is the surface where humans and AI meet. It includes the chatbots embedded in productivity tools, the developer copilots, the low-code agent builders, and the more advanced autonomous agents that some teams have started to ship. Buying access to it is a procurement exercise. The vendors are well known. The pricing is published. The deployment is mostly a change-management problem.
This is why most AI strategy conversations stop here. The Application layer is legible to the executive committee, easy to budget for, and visible to the rest of the business within a quarter. It produces stories that translate well into a town hall.
It is also the layer where competitive differentiation is hardest to build. Every company in a sector is buying from the same short list of vendors. The interface is increasingly standardized. The user experience converges. A Copilot rollout, on its own, does not yet constitute a strategy. It is access to a capability that the company has not architected for. Without the layers underneath, that access produces a chatbot, not an agent that can act inside the business.
Three pressures pushing CTOs below the waterline
Until recently, the case for leaving the rest of the stack to hyperscalers was defensible. In 2024, an enterprise could ship a useful internal assistant on top of a frontier API and consider the work done. Three pressures have converged this year that make that posture much harder to hold.
1- Platform pressure
The first pressure is that the AI Platform layer is no longer optional. This is the layer that defines what an AI system knows and what it can do. It includes master prompts and skill libraries, retrieval against vector databases and structured knowledge bases, connection protocols that let agents act across business systems, and the persistent memory that allows them to maintain state across sessions.
A year ago, this layer was an interesting research direction. Today it is load-bearing. Companies that have moved from chatbot pilots to deployed agents have done so by investing here. Companies still running pilots usually skipped this layer and tried to wire business context directly into prompts and integrations on the application side. That approach works for one well-bounded use case. It does not scale to a portfolio of agents acting across the business.
2- Cost pressure
The second pressure is economic. The subsidized pricing of frontier AI labs is coming to an end. Inference costs that used to be absorbed at the model-provider level are increasingly being passed through, and the early signals are not subtle. Uber has reportedly consumed its entire 2026 LLM budget within the first four months of the year. That kind of overrun is no longer a procurement anecdote, it is a signal that inference economics deserve a place on the CTO’s quarterly review.
The response is not to use less AI. The response is a deliberate inference strategy using smart routing between frontier and smaller models, fine-tuned or specialized models for high-volume tasks that do not require frontier reasoning, and in some cases custom harnesses built around open-source weights. The move that almost no enterprise has on its roadmap yet is training or fine-tuning its own models for the workloads where the volume justifies it. Small language models, LoRA-style fine-tunes, and domain-specific architectures are starting to look less like a research curiosity and more like an operating-cost decision.
3- Sovereignty pressure
The third pressure is political and regulatory. Data residency requirements, the EU AI Act, sector-specific rules in financial services and healthcare, and the broader geopolitical fragmentation of compute are pushing Hardware and Infrastructure decisions onto the CTO’s desk for the first time. The question of who holds the keys to the infrastructure your models run on used to be an IT-procurement detail. In 2026 it has become a board-level question for any company that handles regulated data or operates across jurisdictions.
This pressure is also different in kind from the cloud-sovereignty conversation a decade ago, and that difference is worth pausing on. The cloud debate was about commodity compute: servers, storage, and bandwidth. Humans remained in the loop on every meaningful decision the infrastructure supported. AI infrastructure is not commodity compute. What runs on these GPUs is intelligence, and for a growing share of business processes, the infrastructure will not merely support a human decision, it will make the decision.
That changes the political weight of who controls the hardware. Of the three pressures, Sovereignty is the most shadowed today, as most boards have not yet internalized what it means to run a business on intelligence they do not own. It will become much clearer once Physical AI starts to ship at scale. Companies that have built a deliberate Hardware strategy by then, and that understand how to set it up for their context, are likely to find themselves with a competitive advantage that takes years to close.
Taken together, these three pressures dissolve the comfortable 2024 posture. None of them can be addressed at the Application layer. Each one pulls the CTO into a different part of the stack.
The four layers, reduced to the question each one answers
To make a deliberate decision about the stack, each layer has to be reduced to the question it actually answers.
The Application layer is the surface where humans and AI meet. The question is: where do humans meet AI in our operations, and how do they collaborate? The choices range from chatbots embedded in productivity tools, to agents triggered by a message in Teams or Slack, to agents triggered by workflow events, to agents embedded inside business systems like SAP or Salesforce. The right pattern depends on how much human-in-the-loop the work tolerates.
AI Platform is the layer that defines what the AI knows and what it can do. The question is: where do our agents get business context, and what authority can we delegate to them? The choices are static context (master prompts, skills, structured rule files), retrieval against knowledge bases and vector stores, action-taking through standardized agent connection protocols, and persistent memory across sessions. Each choice corresponds to a different level of autonomy the agent is granted.
LLM Infrastructure is the layer where models are accessed, routed, governed, and optimized. The question is: how do we route the right model to the right job, at the right cost? The choices range from frontier LLMs for complex reasoning, to small or fine-tuned models for high-volume well-defined tasks, to specialized modality models for voice or document understanding, to edge models for latency-critical work. This is the layer where inference economics actually live.
The Hardware layer includes the GPUs, inference servers, and orchestration that run the models. The question is: where do our models actually execute, and who holds the keys to that infrastructure? The choices run from hyperscaler-managed compute, to private cloud or dedicated infrastructure, to on-premise inference clusters, to custom silicon or embedded compute. For most enterprises, the answer is hyperscaler-managed. For data-sensitive industries, it is increasingly something else.
These four layers are not separate strategies. They are one strategy expressed at four levels of depth.
Sequencing beats coverage
The honest reading of the picture is not that every company should own every layer. Some of the most defensible AI positions in 2026 will belong to companies that consciously chose to ride hyperscaler abstractions at the bottom of the stack and to concentrate their investment somewhere else. Owning more of the stack is not the argument. The argument is that the choice has to be deliberate.
A CTO who has decided where Microsoft, AWS, Google, or another partner sits in their stack, and who has decided which layer their own team will invest in this year, has a strategy. A CTO who never made the decision is paying for one without owning it. The cost of that omission compounds: the team ends up with a portfolio of disconnected pilots, a procurement bill that grows faster than the value, and no clear answer when the board asks where the next year of investment should go.
The work, then, is sequencing. The question is not which layer to own and which to outsource, since over a long enough horizon every AI-native company will have to take a position on all four. The question is which layer to prioritize now, and which to revisit in 12, 24, and 36 months.
The archetype of the company is the strongest signal for that sequencing: Start-ups, smaller specialized services, and boutiques can usually keep their investment focused on the Application and Platform layers.
- Multi-regional corporations in CPG, B2B, pharma, legal, and healthcare typically need to extend into the Platform layer to manage their business context, with selective moves into Infrastructure as inference volume grows.
- Multi-regional corporations with higher AI maturity, especially in financial services, telecommunications, and digital-native sectors, are already making real Infrastructure decisions around routing, fine-tuning, and residency.
- BigTech, government, and highly specialized manufacturing, where the AI capability itself is the product or the strategic asset, end up making real choices at the Hardware layer.
The point is not that one archetype is more advanced than another. It is that the sequencing of the four layers is different for each. A pharmaceutical company that tries to behave like SpaceX at the Hardware layer is wasting capital. A bank that behaves like a start-up at the Platform layer is leaving its core asset, its data context, unmanaged.
Cloud transition, on a faster clock
The shape of this transition has been seen before. In 2012, the cloud conversation in most boardrooms was binary: should we use AWS, or should we not? By 2018, that single question had unfolded into a multi-axis decision about which workloads belonged where, which providers fit which use cases, what to multi-cloud, and where data residency mattered. The companies that treated cloud as a single procurement decision in 2012 spent the next six years catching up to those that treated it as an architecture decision from the start.
The AI stack is going through the same maturation on a much faster clock. The cloud took most of a decade to fragment from a single question into a layered decision. The AI stack is doing it in three to four years. CTOs who treat AI in 2026 the way the best ones treated cloud in 2012, as an architecture decision rather than a procurement decision, are likely to find themselves several years ahead of their peers by the end of the decade.
What this means for the CTO this year
Three moves, in particular, deserve a place on the agenda.
The first is that the AI Platform layer deserves explicit ownership. For most enterprises that have shipped Copilot-style work in the last two years, this is the layer where the next 12 months of investment will produce the most differentiated return. Context is the part of the stack that does not get cheaper to digitize. Models will keep improving and prices will keep moving. The company’s own structured knowledge, decision rules, and connection points to its operational systems are what give a model business meaning.
The second is that inference economics now belong on the quarterly agenda. A serious inference strategy includes smart routing, small or fine-tuned models for the volume tier, and at least an exploratory conversation about training in-house for workloads where the unit economics justify it. The cost curve of frontier inference will not move in a single direction, and any strategy that depends on a single provider’s pricing is structurally fragile.
The third is that Hardware and Infrastructure choices should be revisited, even if the answer ends up being hyperscaler for now. The decision to ride a managed stack is a legitimate one, but it should be a decision rather than a default. For regulated industries, the questions of sovereign inference, hybrid deployment, and on-premise stacks are no longer hypothetical.
None of these moves requires building everything in-house. They require thinking through every layer with the same seriousness most boards already apply to the Application layer.
One question at a time
The architecture of an AI-native company is decided one question at a time, and each question lives in a different layer. The visible 20 percent is the easy part. The work that compounds happens below the waterline, in the layers that do not show up in a vendor demo.
CTOs who stop at the visible layer end up managing tools. CTOs who look below the waterline end up managing cognitive capacity. The question is not which model to buy, but which kind of CTO the company decides to become: operational, or strategic.
