
")

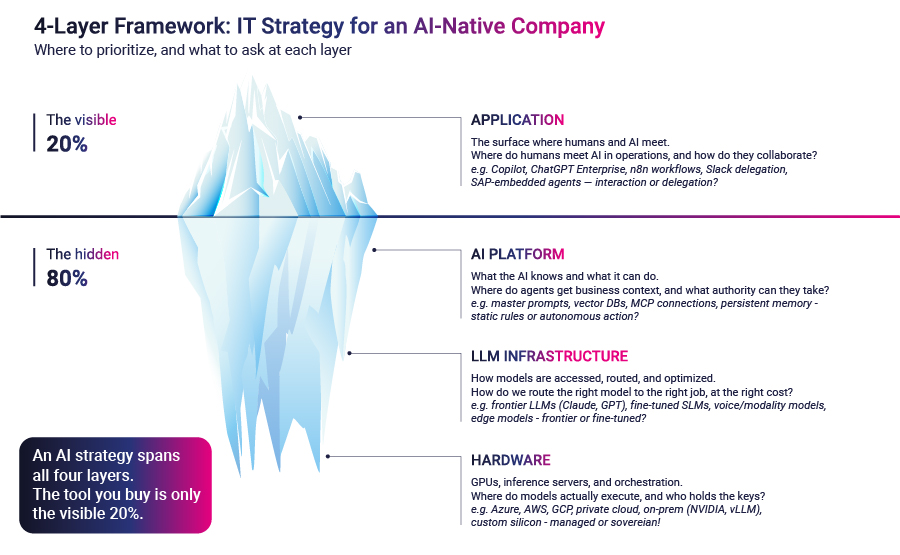
En 2026, la plupart des directeurs techniques conçoivent une stratégie d'IA au niveau de la couche visible de la pile. Ils achètent des sièges Copilot, déploient des chatbots d'entreprise et rassemblent un portefeuille de licences de fournisseurs. Le travail est réel et, dans de nombreuses entreprises, il a produit une augmentation mesurable de la productivité. Il s'agit également, selon une lecture honnête de l'image, du 20% de l'iceberg que tout le monde peut voir. Le 80% qui se trouve sous la ligne de flottaison est l'endroit où une organisation agentique se construit réellement. Les équipes qui ne regardent jamais en bas continueront à payer pour des chatbots tandis que leurs concurrents deviendront tranquillement quelque chose d'autre.
L'architecture d'une entreprise native de l'IA s'articule autour de quatre couches : Application, plateforme d'IA, infrastructure LLM et matériel. La couche application est celle dont la plupart des conseils d'administration ont déjà discuté. C'est dans les trois autres couches que seront prises les véritables décisions stratégiques des 24 prochains mois.
La couche d'application est la surface où les humains et l'IA se rencontrent. Il s'agit des chatbots intégrés aux outils de productivité, des copilotes des développeurs, des créateurs d'agents à code bas et des agents autonomes plus avancés que certaines équipes ont commencé à livrer. Acheter l'accès à ces agents est un exercice d'approvisionnement. Les fournisseurs sont bien connus. Les prix sont publiés. Le déploiement est essentiellement un problème de gestion du changement.
C'est pourquoi la plupart des conversations sur la stratégie d'IA s'arrêtent ici. La couche d'application est lisible pour le comité exécutif, facile à budgétiser et visible pour le reste de l'entreprise en l'espace d'un trimestre. Elle produit des histoires qui se traduisent bien dans une assemblée générale.
C'est également à ce niveau qu'il est le plus difficile de se différencier de la concurrence. Toutes les entreprises d'un secteur achètent auprès de la même liste restreinte de fournisseurs. L'interface est de plus en plus standardisée. L'expérience de l'utilisateur converge. Le déploiement d'un copilote, en soi, ne constitue pas encore une stratégie. Il s'agit d'un accès à une capacité pour laquelle l'entreprise n'a pas élaboré d'architecture. Sans les couches sous-jacentes, cet accès produit un chatbot, et non un agent capable d'agir au sein de l'entreprise.
Trois pressions qui poussent les CTO sous la ligne de flottaison
Jusqu'à récemment, il était justifié de laisser le reste de la pile aux hyperscalers. En 2024, une entreprise pouvait livrer un assistant interne utile au sommet d'une API d'avant-garde et considérer que le travail était fait. Cette année, trois pressions ont convergé pour rendre cette position beaucoup plus difficile à tenir.
1- Pression de la plate-forme
La première pression est que la La couche de la plateforme d'IA n'est plus optionnelle. Il s'agit de la couche qui définit ce qu'un système d'IA sait et ce qu'il peut faire. Elle comprend les invites principales et les bibliothèques de compétences, la recherche dans les bases de vecteurs et les bases de connaissances structurées, les protocoles de connexion qui permettent aux agents d'agir à travers les systèmes d'entreprise, et la mémoire persistante qui leur permet de conserver leur état à travers les sessions.
Il y a un an, cette couche était une piste de recherche intéressante. Aujourd'hui, elle est porteuse. Les entreprises qui sont passées d'un chatbot pilote à des agents déployés l'ont fait en investissant dans cette couche. Les entreprises qui mènent encore des projets pilotes ont généralement ignoré cette couche et ont essayé d'intégrer le contexte commercial directement dans les messages-guides et les intégrations du côté de l'application. Cette approche fonctionne pour un cas d'utilisation bien délimité. Il n'est pas adapté à un portefeuille d'agents agissant dans l'ensemble de l'entreprise.
2- Pression sur les coûts
La deuxième pression est économique. La tarification subventionnée des laboratoires d'IA pionniers touche à sa fin. Les coûts d'inférence qui étaient auparavant absorbés au niveau du fournisseur de modèle sont de plus en plus souvent répercutés, et les premiers signaux ne sont pas subtils. Uber aurait consommé la totalité de son budget LLM 2026 au cours des quatre premiers mois de l'année. Ce type de dépassement n'est plus une anecdote d'approvisionnement, c'est un signal que l'économie de l'inférence mérite une place dans l'examen trimestriel du directeur de la technologie.
La réponse n'est pas d'utiliser moins d'IA. La réponse est une une stratégie d'inférence délibérée utilisant un routage intelligent entre la frontière et les modèles plus petits, les modèles affinés ou spécialisés. pour les tâches à fort volume qui ne nécessitent pas de raisonnement frontalier et, dans certains cas, des harnais personnalisés construits à partir de poids open-source. L'étape que presque aucune entreprise n'a encore inscrite sur sa feuille de route consiste à former ou à affiner ses propres modèles pour les charges de travail dont le volume le justifie. Les petits modèles linguistiques, les réglages fins de type LoRA et les architectures spécifiques à un domaine commencent à ressembler de moins en moins à une curiosité de recherche et de plus en plus à une décision de coût opérationnel.
3- La pression de la souveraineté
La troisième pression est d'ordre politique et réglementaire. Les exigences de résidence Data, la loi européenne sur l'IA, les règles sectorielles dans les services financiers et les soins de santé, et la fragmentation géopolitique plus large de l'informatique sont autant de facteurs qui influent sur la compétitivité des entreprises. en poussant les décisions relatives au matériel et à l'infrastructure sur le bureau du directeur de la technologie pour la première fois. La question de savoir qui détient les clés de l'infrastructure sur laquelle fonctionnent vos modèles était auparavant un détail de l'approvisionnement informatique. En 2026, c'est devenu une question qui se pose au niveau du conseil d'administration de toute entreprise qui gère des data réglementés ou qui opère dans plusieurs juridictions.
Cette pression est également différente de la conversation cloud-souveraineté d'il y a dix ans, et cette différence mérite que l'on s'y arrête. Le débat sur le cloud portait sur l'informatique de base : serveurs, stockage et bande passante. Les humains restaient au courant de toutes les décisions importantes prises par l'infrastructure. L'infrastructure de l'IA n'est pas un ordinateur de base. Ce qui tourne sur ces GPU, c'est l'intelligence, et ce pour une part croissante des processus d'entreprise, l'infrastructure ne se contentera pas de soutenir une décision humaine, elle prendra la décision.
Cela modifie le poids politique de ceux qui contrôlent le matériel. Des trois pressions, c'est la souveraineté qui est la plus menacée aujourd'hui. la plupart des conseils d'administration n'ont pas encore assimilé ce que cela signifie de gérer une entreprise à partir d'informations qui ne leur appartiennent pas. Les choses deviendront beaucoup plus claires lorsque l'IA physique commencera à être livrée à grande échelle. Les entreprises qui auront élaboré une stratégie matérielle délibérée d'ici là, et qui comprendront comment la mettre en place dans leur contexte, se retrouveront probablement avec un avantage de taille. Il s'agit d'un avantage concurrentiel qui met des années à se concrétiser.
Prises ensemble, ces trois pressions dissolvent la position confortable de 2024. Aucune d'entre elles ne peut être traitée au niveau de la couche applicative. Chacune d'entre elles entraîne le CTO dans une partie différente de la pile.
Les quatre couches, réduites à la question à laquelle chacune répond
Pour prendre une décision délibérée concernant la pile, chaque couche doit être réduite à la question à laquelle elle répond réellement.
La couche d'application est la surface où les humains et l'IA se rencontrent. La question est la suivante : où les humains rencontrent-ils l'IA dans nos opérations, et comment collaborent-ils ? Les choix vont des chatbots intégrés aux outils de productivité, aux agents déclenchés par un message dans Teams ou Slack, aux agents déclenchés par des événements de flux de travail, aux agents intégrés dans des systèmes d'entreprise tels que SAP ou Salesforce. Le bon modèle dépend de la quantité d'humain dans la boucle que le travail tolère.
La plateforme d'IA est la couche qui définit ce que l'IA sait et ce qu'elle peut faire. La question est la suivante : où nos agents obtiennent-ils le contexte commercial et quelle autorité pouvons-nous leur déléguer ? Les choix sont le contexte statique (invites principales, compétences, fichiers de règles structurés), la recherche dans les bases de connaissances et les magasins de vecteurs, la prise d'action par le biais de protocoles de connexion d'agent normalisés et la mémoire persistante au fil des sessions. Chaque choix correspond à un niveau d'autonomie différent accordé à l'agent.
L'infrastructure LLM est la couche où les modèles sont accessibles, acheminés, gouvernés et optimisés. La question est la suivante : comment acheminer le bon modèle vers la bonne tâche, au bon coût ? Les choix vont des LLM d'avant-garde pour les raisonnements complexes, aux modèles de petite taille ou finement ajustés pour les tâches bien définies à volume élevé, aux modèles de modalité spécialisés pour la compréhension de la voix ou des documents, en passant par les modèles de périphérie pour les travaux critiques en termes de latence. C'est à ce niveau que se situe l'économie de l'inférence.
La couche matérielle comprend les GPU, les serveurs d'inférence et l'orchestration qui exécutent les modèles. La question est la suivante : où nos modèles s'exécutent-ils réellement et qui détient les clés de cette infrastructure ? Les choix vont de l'informatique gérée par l'hyperscaler à l'infrastructure privée cloud ou dédiée, en passant par les clusters d'inférence sur site, le silicium personnalisé ou l'informatique intégrée. Pour la plupart des entreprises, la réponse est la gestion par hyperscaler. Pour les industries sensibles au data, c'est de plus en plus autre chose.
Ces quatre niveaux ne sont pas des stratégies distinctes. Il s'agit d'une seule stratégie exprimée à quatre niveaux de profondeur.
Couverture des battements de séquençage
La lecture honnête de ce tableau n'est pas que chaque entreprise devrait posséder chaque couche. Certaines des positions les plus défendables en matière d'IA en 2026 appartiendront à des entreprises qui auront délibérément choisi d'utiliser les abstractions de l'hyperscaler au bas de la pile et de concentrer leurs investissements ailleurs. L'argument n'est pas de posséder une plus grande part de la pile. L'argument est que le choix doit être délibéré.
Un directeur technique qui a décidé de la place de Microsoft, d'AWS, de Google ou d'un autre partenaire dans sa pile, et qui a décidé dans quelle couche son équipe investira cette année, dispose d'une stratégie. Un directeur technique qui n'a jamais pris cette décision paie pour une stratégie sans la posséder. Le coût de cette omission s'aggrave : l'équipe se retrouve avec un portefeuille de projets pilotes déconnectés, une facture d'achat qui augmente plus vite que la valeur, et aucune réponse claire lorsque le conseil d'administration demande où devrait aller l'investissement de l'année suivante.
Il s'agit donc d'un travail de séquençage. La question n'est pas de savoir quelle couche posséder ou externaliser, car, à long terme, chaque entreprise native de l'IA devra prendre position sur ces quatre aspects. La question est de savoir quelle couche doit être prioritaire aujourd'hui et laquelle doit être réexaminée dans 12, 24 et 36 mois.
L'archétype de l'entreprise est le signal le plus fort pour ce séquençage : Les start-ups, les petits services spécialisés et les boutiques peuvent généralement concentrer leurs investissements sur les couches Application et Plateforme.
- Entreprises multirégionales des secteurs CPG, B2B, pharmaceutique, juridique et de la santé ont généralement besoin de s'étendre à la couche Plateforme pour gérer leur contexte commercial, avec des déplacements sélectifs vers l'Infrastructure à mesure que le volume d'inférences augmente.
- Sociétés multirégionales ayant une plus grande maturité en matière d'IA, en particulier dans les services financiers, les télécommunications et les secteurs natifs du numérique., Les utilisateurs de l'Internet, de l'Internet et de l'Internet, prennent déjà des décisions d'infrastructure réelles concernant l'acheminement, le réglage fin et la résidence.
- BigTech, gouvernement et fabrication hautement spécialisée, où la capacité d'IA elle-même est le produit ou l'actif stratégique, finissent par faire des choix réels au niveau du matériel.
Il ne s'agit pas de dire qu'un archétype est plus avancé qu'un autre. C'est que l'archétype La séquence des quatre couches est différente pour chacune d'entre elles. Une entreprise pharmaceutique qui essaie de se comporter comme SpaceX au niveau du matériel gaspille du capital. Une banque qui se comporte comme une start-up au niveau de la plateforme laisse son actif principal, son contexte data, sans gestion.
Transition vers le nuage, à une cadence plus rapide
La forme de cette transition a déjà été observée auparavant. En 2012, la conversation cloud dans la plupart des salles de conférence était binaire : devrions-nous utiliser AWS ou non ? En 2018, cette simple question s'est transformée en une décision multiaxiale concernant les charges de travail, les fournisseurs adaptés aux différents cas d'utilisation, le multi-cloud et l'importance de la résidence data. Les entreprises qui ont traité le cloud comme une décision d'achat unique en 2012 ont passé les six années suivantes à rattraper celles qui l'ont traité comme une décision d'architecture dès le départ.
La pile d'IA subit la même maturation à une cadence beaucoup plus rapide. Le cloud a mis la majeure partie d'une décennie pour passer d'une simple question à une décision stratifiée. La pile d'IA y parvient en trois ou quatre ans. Les directeurs techniques qui traiteront l'IA en 2026 comme les meilleurs ont traité le cloud en 2012, c'est-à-dire comme une décision d'architecture plutôt que comme une décision d'approvisionnement, sont les suivants Les jeunes de l'Union européenne sont susceptibles de se retrouver plusieurs années en avance sur leurs pairs d'ici à la fin de la décennie.
Ce que cela signifie pour le directeur technique cette année
Trois initiatives, en particulier, méritent d'être inscrites à l'ordre du jour.
La première est que la couche de la plateforme d'IA mérite d'être explicitement prise en charge. Pour la plupart des entreprises qui ont réalisé des travaux de type Copilote au cours des deux dernières années, il s'agit de la couche où les 12 prochains mois d'investissement produiront le rendement le plus différencié. Le contexte est la partie de la pile qui n'est pas moins chère à numériser. Les modèles continueront à s'améliorer et les prix à évoluer. Les connaissances structurées de l'entreprise, les règles de décision et les points de connexion avec ses systèmes opérationnels sont ce qui donne un sens à un modèle d'entreprise.
La seconde est que l'économie de l'inférence a désormais sa place dans l'agenda trimestriel. Une stratégie d'inférence sérieuse comprend un routage intelligent, des modèles de petite taille ou finement ajustés pour le niveau de volume, et au moins une conversation exploratoire sur la formation en interne pour les charges de travail où l'économie unitaire le justifie. La courbe des coûts de l'inférence de frontière n'évoluera pas dans une seule direction, et toute stratégie qui dépend de la tarification d'un seul fournisseur est structurellement fragile.
La troisième est que Les choix en matière de matériel et d'infrastructure doivent être revus, même si la réponse finit par être hyperscaler pour l'instant. La décision d'opter pour une pile gérée est légitime, mais elle doit être une décision plutôt qu'un choix par défaut. Pour les industries réglementées, les questions de l'inférence souveraine, du déploiement hybride et des piles sur site ne sont plus hypothétiques.
Aucune de ces mesures n'exige de tout construire en interne. Elles nécessitent de réfléchir à chaque couche avec le même sérieux que la plupart des conseils d'administration appliquent déjà à la couche "application".
Une question à la fois
L'architecture d'une entreprise native de l'IA est décidée une question à la fois, et chaque question se situe dans une couche différente. Les 20 % visibles sont la partie la plus facile. Le travail sur les composés se fait sous la ligne de flottaison, dans les couches qui n'apparaissent pas dans la démonstration d'un fournisseur.
Les directeurs techniques qui s'arrêtent à la couche visible finissent par gérer des outils. Les directeurs techniques qui regardent sous la ligne de flottaison finissent par gérer la capacité cognitive. La question n'est pas de savoir quel modèle acheter, mais quel type de CTO l'entreprise décide de devenir : opérationnel ou stratégique.
