
")

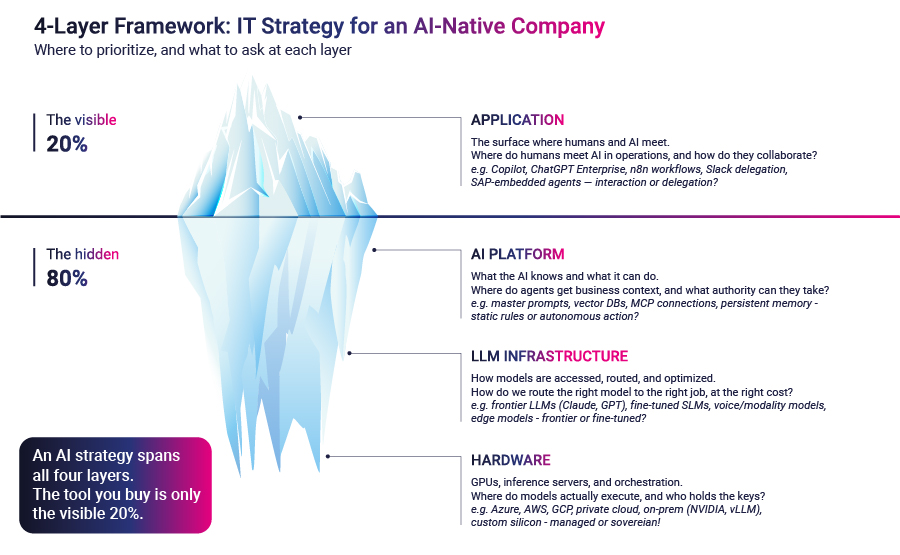
Die meisten CTOs im Jahr 2026 entwickeln eine KI-Strategie auf der sichtbaren Ebene des Stacks. Sie kaufen Copilot-Sitze, führen Unternehmens-Chatbots ein und stellen ein Portfolio von Anbieterlizenzen zusammen. Die Arbeit ist real und hat in vielen Unternehmen zu einem messbaren Produktivitätsanstieg geführt. Wenn man das Bild ehrlich liest, ist es auch die 20% des Eisbergs, die jeder sehen kann. Der 80%, der unter der Wasserlinie sitzt, ist der Ort, an dem eine agenturische Organisation tatsächlich aufgebaut wird. Teams, die nie nach unten schauen, werden weiterhin für Chatbots bezahlen, während ihre Konkurrenten im Stillen etwas anderes werden.
Die Architektur eines KI-nativen Unternehmens besteht aus vier Schichten: Anwendung, KI-Plattform, LLM-Infrastruktur und Hardware. Die Anwendungsebene ist diejenige, die die meisten Vorstände bereits diskutiert haben. Auf den anderen drei Ebenen werden die wirklichen strategischen Entscheidungen der nächsten 24 Monate getroffen.
Die Anwendungsschicht ist die Oberfläche, auf der Menschen und KI aufeinandertreffen. Dazu gehören die Chatbots, die in Produktivitätstools eingebettet sind, die Copiloten für Entwickler, die Low-Code-Agenten und die fortgeschritteneren autonomen Agenten, die einige Teams bereits auf den Markt gebracht haben. Der Erwerb des Zugangs dazu ist eine Beschaffungsmaßnahme. Die Anbieter sind gut bekannt. Die Preise sind veröffentlicht. Die Bereitstellung ist hauptsächlich ein Problem des Änderungsmanagements.
Deshalb hören die meisten Gespräche über KI-Strategien hier auf. Die Anwendungsebene ist für den Vorstand lesbar, leicht zu budgetieren und für den Rest des Unternehmens innerhalb eines Quartals sichtbar. Sie bringt Geschichten hervor, die sich gut in einer Stadthalle umsetzen lassen.
Es ist auch die Ebene, auf der es am schwierigsten ist, sich vom Wettbewerb abzuheben. Jedes Unternehmen in einer Branche kauft bei denselben Anbietern ein. Die Schnittstelle ist zunehmend standardisiert. Das Benutzererlebnis konvergiert. Eine Copilot-Einführung ist für sich genommen noch keine Strategie. Es ist der Zugang zu einer Fähigkeit, für die das Unternehmen keine Architektur entwickelt hat. Ohne die darunter liegenden Schichten ergibt dieser Zugang einen Chatbot und keinen Agenten, der innerhalb des Unternehmens agieren kann.
Drei Drücke, die CTOs unter die Wasserlinie drücken
Bis vor kurzem war es noch vertretbar, den Rest des Stacks den Hyperscalern zu überlassen. Im Jahr 2024 konnte ein Unternehmen einen nützlichen internen Assistenten auf der Grundlage einer Grenz-API ausliefern und die Arbeit als erledigt betrachten. In diesem Jahr sind drei Faktoren zusammengekommen, die diese Haltung sehr viel schwieriger machen.
1- Druck der Plattform
Der erste Druck ist, dass die AI Platform Layer ist nicht mehr optional. Dies ist die Schicht, die definiert, was ein KI-System weiß und was es tun kann. Sie umfasst Master-Prompts und Skill-Bibliotheken, die Abfrage von Vektor-data-Datenbanken und strukturierten Wissensdatenbanken, Verbindungsprotokolle, die es Agenten ermöglichen, über Geschäftssysteme hinweg zu agieren, und den persistenten Speicher, der es ihnen ermöglicht, ihren Zustand über Sitzungen hinweg zu erhalten.
Vor einem Jahr war diese Schicht eine interessante Forschungsrichtung. Heute ist sie eine tragende Säule. Unternehmen, die von Chatbot-Piloten zu implementierten Agenten übergegangen sind, haben hier investiert. Unternehmen, die noch Pilotprojekte durchführen, haben diese Ebene in der Regel übersprungen und versucht, den Geschäftskontext direkt in die Prompts und Integrationen auf der Anwendungsseite einzubinden. Dieser Ansatz funktioniert für einen gut eingegrenzten Anwendungsfall. Es lässt sich nicht auf ein Portfolio von Agenten übertragen, die im gesamten Unternehmen tätig sind.
2- Kostendruck
Der zweite Druck ist wirtschaftlicher Natur. Die subventionierten Preise für die KI-Labore der Pioniere gehen zu Ende. Die Kosten für Schlussfolgerungen, die früher auf der Ebene des Modellanbieters absorbiert wurden, werden zunehmend weitergegeben, und die ersten Signale sind nicht gerade subtil. Uber hat Berichten zufolge sein gesamtes LLM-Budget für 2026 innerhalb der ersten vier Monate des Jahres verbraucht. Diese Art von Überschreitung ist nicht länger eine Anekdote aus dem Beschaffungswesen, sondern ein Zeichen dafür, dass das Thema Inferenzökonomie einen Platz in der Quartalsübersicht des CTO verdient hat.
Die Antwort ist nicht, weniger KI zu verwenden. Die Antwort ist eine gezielte Inferenzstrategie mit intelligentem Routing zwischen Frontier und kleineren Modellen, fein abgestimmten oder spezialisierten Modellen für hochvolumige Aufgaben, die kein Frontier Reasoning erfordern, und in einigen Fällen benutzerdefinierte Kabelbäume, die auf Open-Source-Gewichten basieren. Der Schritt, den fast kein Unternehmen auf seiner Roadmap hat, ist das Training oder die Feinabstimmung seiner eigenen Modelle für die Arbeitslasten, bei denen das Volumen dies rechtfertigt. Kleine Sprachmodelle, LoRA-ähnliche Feinabstimmungen und domänenspezifische Architekturen sehen allmählich weniger wie eine Forschungskuriosität und mehr wie eine Betriebskostenentscheidung aus.
3- Souveränitätsdruck
Der dritte Druck ist politischer und regulatorischer Natur. Data Residenzpflicht, das EU-KI-Gesetz, sektorspezifische Vorschriften für Finanzdienstleistungen und das Gesundheitswesen sowie die allgemeine geopolitische Fragmentierung der Datenverarbeitung sind Hardware- und Infrastrukturentscheidungen zum ersten Mal auf den Schreibtisch des CTO zu verlagern. Die Frage, wer die Schlüssel zu der Infrastruktur besitzt, auf der Ihre Modelle laufen, war früher ein Detail der IT-Beschaffung. Im Jahr 2026 ist sie zu einer Frage auf Vorstandsebene für jedes Unternehmen geworden, das mit regulierten data arbeitet oder über Ländergrenzen hinweg tätig ist.
Dieser Druck unterscheidet sich auch in seiner Art von der cloud-Souveränitätsdiskussion vor einem Jahrzehnt, und dieser Unterschied ist es wert, innezuhalten. Bei der cloud-Debatte ging es um Standardcomputer: Server, Speicher und Bandbreite. Der Mensch blieb bei jeder bedeutsamen Entscheidung, die die Infrastruktur unterstützte, im Spiel. Die KI-Infrastruktur ist kein Standardcomputer. Was auf diesen GPUs läuft, ist Intelligenz, und zwar für einen wachsenden Teil der Geschäftsprozesse, wird die Infrastruktur nicht nur eine menschliche Entscheidung unterstützen, sondern sie wird die Entscheidung treffen.
Dadurch ändert sich das politische Gewicht derjenigen, die die Hardware kontrollieren. Von den drei Druckmitteln ist die Souveränität heute am stärksten beschattet, da Die meisten Vorstände haben noch nicht verinnerlicht, was es bedeutet, ein Unternehmen mit Informationen zu führen, die ihnen nicht gehören. Es wird viel klarer werden, wenn Physikalische KI in großem Umfang auf den Markt kommt. Unternehmen, die bis dahin eine bewusste Hardware-Strategie entwickelt haben und wissen, wie sie diese für ihren Kontext einrichten können, werden wahrscheinlich einen Wettbewerbsvorteil, der Jahre braucht, um zu schließen.
Zusammengenommen lösen diese drei Belastungen die komfortable Haltung von 2024 auf. Keiner von ihnen kann auf der Anwendungsebene angegangen werden. Jeder dieser Faktoren zieht den CTO in einen anderen Teil des Stacks.
Die vier Ebenen, reduziert auf die Frage, die jede Ebene beantwortet
Um eine bewusste Entscheidung über den Stapel zu treffen, muss jede Ebene auf die Frage reduziert werden, die sie tatsächlich beantwortet.
Die Anwendungsschicht ist die Oberfläche, auf der Menschen und KI aufeinandertreffen. Die Frage ist: Wo treffen Menschen und KI in unseren Abläufen aufeinander, und wie arbeiten sie zusammen? Die Auswahl reicht von Chatbots, die in Produktivitätstools eingebettet sind, über Agenten, die durch eine Nachricht in Teams oder Slack ausgelöst werden, bis hin zu Agenten, die durch Workflow-Ereignisse ausgelöst werden, oder Agenten, die in Geschäftssysteme wie SAP oder Salesforce eingebettet sind. Welches Muster das richtige ist, hängt davon ab, wie viel Mensch in der Schleife die Arbeit verträgt.
Die KI-Plattform ist die Ebene, die definiert, was die KI weiß und was sie tun kann. Die Frage ist: Woher bekommen unsere Agenten den geschäftlichen Kontext und welche Befugnisse können wir an sie delegieren? Sie haben die Wahl zwischen statischem Kontext (Master-Prompts, Fähigkeiten, strukturierte Regeldateien), dem Abruf von Wissensdatenbanken und Vektorspeichern, der Durchführung von Aktionen über standardisierte Agentenverbindungsprotokolle und einem sitzungsübergreifenden persistenten Speicher. Jede Wahl entspricht einem anderen Grad an Autonomie, der dem Agenten gewährt wird.
Die LLM-Infrastruktur ist die Ebene, auf der auf Modelle zugegriffen wird, die geroutet, verwaltet und optimiert werden. Die Frage ist: Wie leiten wir das richtige Modell zum richtigen Auftrag und zu den richtigen Kosten weiter? Die Auswahl reicht von Frontier-LLMs für komplexe Schlussfolgerungen über kleine oder fein abgestimmte Modelle für hochvolumige, klar definierte Aufgaben bis hin zu spezialisierten Modalitätsmodellen für das Sprach- oder Dokumentenverständnis und Edge-Modellen für latenzkritische Aufgaben. Dies ist die Ebene, auf der die Inferenzökonomie tatsächlich lebt.
Die Hardware-Ebene umfasst die GPUs, Inferenzserver und die Orchestrierung, die die Modelle ausführen. Die Frage ist: wo werden unsere Modelle tatsächlich ausgeführt, und wer hat die Schlüssel zu dieser Infrastruktur? Sie haben die Wahl zwischen Hyperscaler-verwaltetem Compute, privater cloud- oder dedizierter Infrastruktur, Inferenz-Clustern vor Ort, kundenspezifischem Silizium oder eingebettetem Compute. Für die meisten Unternehmen lautet die Antwort hyperscaler-managed. Für data-empfindliche Branchen ist es zunehmend etwas anderes.
Diese vier Ebenen sind keine separaten Strategien. Sie sind eine einzige Strategie, die sich auf vier Ebenen der Tiefe ausdrückt.
Sequenzierung schlägt Abdeckung
Die ehrliche Lesart des Bildes ist nicht, dass jedes Unternehmen jede Schicht besitzen sollte. Einige der vertretbarsten KI-Positionen im Jahr 2026 werden Unternehmen gehören, die sich bewusst dafür entschieden haben, auf Hyperscaler-Abstraktionen am unteren Ende des Stacks zu setzen und ihre Investitionen woanders zu konzentrieren. Mehr vom Stapel zu besitzen ist nicht das Argument. Das Argument ist, dass die Entscheidung bewusst getroffen werden muss.
Ein CTO, der entschieden hat, wo Microsoft, AWS, Google oder ein anderer Partner in seinem Stack sitzt, und der entschieden hat, in welche Schicht sein eigenes Team dieses Jahr investieren wird, hat eine Strategie. Ein CTO, der diese Entscheidung nicht getroffen hat, zahlt für eine Strategie, ohne sie zu besitzen. Die Kosten für dieses Versäumnis summieren sich: Das Team endet mit einem Portfolio unzusammenhängender Pilotprojekte, einer Beschaffungsrechnung, die schneller wächst als der Wert, und keiner klaren Antwort, wenn der Vorstand fragt, wohin die Investitionen im nächsten Jahr fließen sollen.
Die Arbeit ist also die Sequenzierung. Die Frage ist nicht, welche Schicht man besitzen und welche man auslagern sollte., Denn auf lange Sicht wird jedes Unternehmen, das KI einsetzt, eine Position zu allen vier Themen einnehmen müssen. Die Frage ist, welcher Ebene Sie jetzt den Vorrang geben und welche Sie in 12, 24 und 36 Monaten erneut überprüfen sollten.
Der Archetyp des Unternehmens ist das stärkste Signal für diese Sequenzierung: Start-ups, kleinere spezialisierte Dienste und Boutiquen können ihre Investitionen in der Regel auf die Anwendungs- und Plattformebene konzentrieren.
- Überregionale Unternehmen aus den Bereichen CPG, B2B, Pharma, Recht und Gesundheitswesen müssen in der Regel in die Plattform-Ebene erweitert werden, um ihren Geschäftskontext zu verwalten, wobei sie bei wachsendem Datenvolumen selektiv in die Infrastruktur-Ebene wechseln.
- Multiregionale Unternehmen mit höherem KI-Reifegrad, insbesondere in den Bereichen Finanzdienstleistungen, Telekommunikation und digital-native Sektoren, treffen bereits echte Infrastrukturentscheidungen in Bezug auf Routing, Feinabstimmung und Wohnsitz.
- BigTech, Regierung und hochspezialisierte Fertigung, Wenn die KI-Fähigkeit selbst das Produkt oder der strategische Vermögenswert ist, müssen Sie auf der Hardware-Ebene echte Entscheidungen treffen.
Es geht nicht darum, dass ein Archetyp fortgeschrittener ist als ein anderer. Es geht darum, dass der Die Abfolge der vier Schichten ist bei jeder unterschiedlich. Ein Pharmaunternehmen, das versucht, sich auf der Hardware-Ebene wie SpaceX zu verhalten, verschwendet Kapital. Eine Bank, die sich auf der Plattformebene wie ein Start-up-Unternehmen verhält, lässt ihren wichtigsten Vermögenswert, den data-Kontext, unbewirtschaftet.
Cloud-Übergang, mit einer schnelleren Uhr
Die Form dieses Übergangs wurde schon einmal gesehen. Im Jahr 2012 war die cloud-Diskussion in den meisten Vorstandsetagen binär: Sollen wir AWS nutzen oder sollen wir es lassen? Im Jahr 2018 hatte sich diese einzelne Frage zu einer vielschichtigen Entscheidung darüber entwickelt, welche Arbeitslasten wohin gehören, welche Anbieter für welche Anwendungsfälle geeignet sind, was mit Multi-cloud zu tun hat und wo die data-Residenz wichtig ist. Die Unternehmen, die cloud im Jahr 2012 als eine einzige Beschaffungsentscheidung behandelten, verbrachten die nächsten sechs Jahre damit, die Unternehmen einzuholen, die es von Anfang an als eine Architekturentscheidung behandelten.
Der KI-Stack durchläuft die gleiche Reifung in einem viel schnelleren Takt. Das cloud brauchte fast ein ganzes Jahrzehnt, um von einer einzigen Frage zu einer mehrschichtigen Entscheidung zu kommen. Der KI-Stack schafft das in drei bis vier Jahren. CTOs, die KI im Jahr 2026 so behandeln, wie die besten CTOs cloud im Jahr 2012 behandelt haben, nämlich als eine Architekturentscheidung und nicht als eine Beschaffungsentscheidung, sind werden bis zum Ende des Jahrzehnts wahrscheinlich mehrere Jahre Vorsprung haben.
Was dies für den CTO in diesem Jahr bedeutet
Vor allem drei Maßnahmen verdienen einen Platz auf der Tagesordnung.
Die erste ist, dass die KI-Plattform-Ebene verdient eine ausdrückliche Beteiligung. Für die meisten Unternehmen, die in den letzten zwei Jahren Arbeiten im Copilot-Stil ausgeliefert haben, ist dies die Schicht, in der die nächsten 12 Monate der Investitionen den größten Nutzen bringen werden. Kontext ist der Teil des Stacks, der nicht billiger zu digitalisieren ist. Die Modelle werden sich weiter verbessern und die Preise werden sich weiter bewegen. Das strukturierte Wissen des Unternehmens, die Entscheidungsregeln und die Verbindungspunkte zu den operativen Systemen sind es, die einem Geschäftsmodell Bedeutung verleihen.
Die zweite ist, dass Inferenzökonomie gehört jetzt auf die vierteljährliche Tagesordnung. Zu einer seriösen Inferenzstrategie gehören intelligentes Routing, kleine oder fein abgestimmte Modelle für die Volumenebene und zumindest ein Sondierungsgespräch über interne Schulungen für Arbeitslasten, bei denen die Stückkosten dies rechtfertigen. Die Kostenkurve der Grenzinferenz wird sich nicht nur in eine Richtung bewegen, und jede Strategie, die von der Preisgestaltung eines einzelnen Anbieters abhängt, ist strukturell anfällig.
Die dritte ist, dass Die Auswahl von Hardware und Infrastruktur sollte überdacht werden, selbst wenn die Antwort vorerst Hyperscaler lautet. Die Entscheidung für einen verwalteten Stack ist legitim, aber es sollte eine Entscheidung sein und kein Standard. Für regulierte Industrien sind die Fragen der souveränen Ableitung, des hybriden Einsatzes und der On-Premise-Stacks nicht mehr hypothetischer Natur.
Keiner dieser Schritte erfordert, dass Sie alles selbst entwickeln. Sie erfordern, dass jede Ebene mit der gleichen Ernsthaftigkeit durchdacht wird, die die meisten Unternehmen bereits für die Anwendungsebene aufbringen.
Eine Frage nach der anderen
Die Architektur eines KI-nativen Unternehmens wird von Frage zu Frage entschieden, und jede Frage befindet sich auf einer anderen Ebene. Die sichtbaren 20 Prozent sind der einfache Teil. Die Arbeit, die sich zusammensetzt, findet unter der Wasserlinie statt, in den Schichten, die in einer Herstellerdemo nicht zu sehen sind.
CTOs, die sich auf die sichtbare Ebene beschränken, enden bei der Verwaltung von Tools. CTOs, die unter die Wasserlinie schauen, enden bei der Verwaltung kognitiver Kapazitäten. Die Frage ist nicht, welches Modell Sie kaufen, sondern welche Art von CTO das Unternehmen werden will: operativ oder strategisch.
