
")

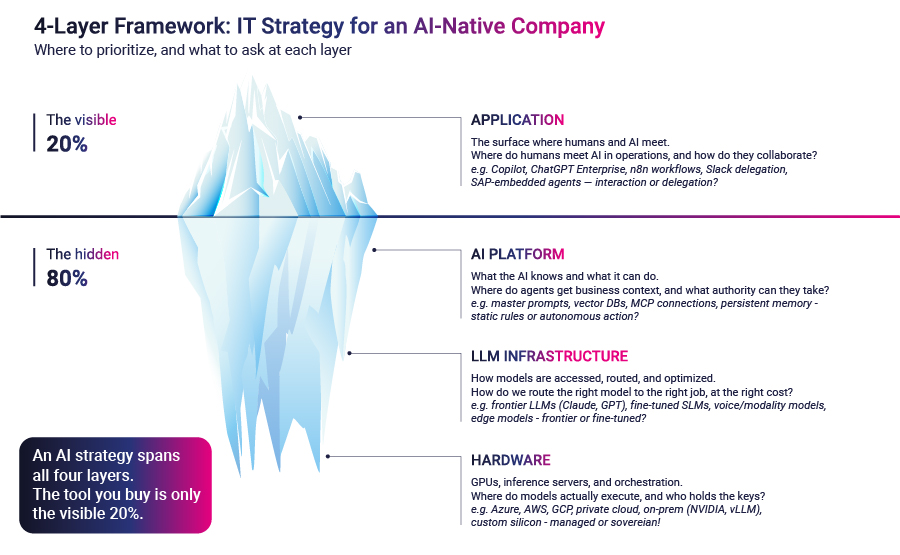
A maioria dos CTOs em 2026 está projetando a estratégia de IA na camada visível da pilha. Eles estão comprando assentos no Copilot, implementando chatbots empresariais e montando um portfólio de licenças de fornecedores. O trabalho é real e, em muitas empresas, produziu um aumento mensurável na produtividade. Em qualquer leitura honesta da imagem, ele também é o 20% do iceberg que todos podem ver. O 80% que fica abaixo da linha d'água é onde uma organização autêntica é realmente construída. As equipes que nunca olham para baixo continuarão pagando por chatbots enquanto seus concorrentes se transformam silenciosamente em outra coisa.
A arquitetura de uma empresa nativa de IA está dividida em quatro camadas: Aplicativo, plataforma de IA, infraestrutura LLM e hardware. A camada de aplicativos é a que a maioria dos conselhos já discutiu. As outras três são onde as decisões estratégicas reais dos próximos 24 meses serão tomadas.
A camada de aplicativos é a superfície onde os seres humanos e a IA se encontram. Isso inclui os chatbots incorporados em ferramentas de produtividade, os copilotos de desenvolvedores, os criadores de agentes de baixo código e os agentes autônomos mais avançados que algumas equipes começaram a enviar. Comprar acesso a eles é um exercício de aquisição. Os fornecedores são bem conhecidos. O preço é publicado. A implementação é principalmente um problema de gerenciamento de mudanças.
É por isso que a maioria das conversas sobre estratégia de IA termina aqui. A camada de aplicativos é legível para o comitê executivo, fácil de orçar e visível para o restante da empresa dentro de um trimestre. Ela produz histórias que se traduzem bem em uma prefeitura.
É também a camada em que a diferenciação competitiva é mais difícil de ser construída. Todas as empresas de um setor estão comprando da mesma pequena lista de fornecedores. A interface está cada vez mais padronizada. A experiência do usuário converge. A implementação do Copilot, por si só, ainda não constitui uma estratégia. É o acesso a um recurso para o qual a empresa não foi projetada. Sem as camadas subjacentes, esse acesso produz um chatbot, não um agente que possa agir dentro da empresa.
Três pressões que empurram os CTOs para baixo da linha d'água
Até recentemente, o argumento para deixar o restante da pilha para os hiperescaladores era defensável. Em 2024, uma empresa poderia enviar um assistente interno útil com base em uma API de ponta e considerar o trabalho concluído. Este ano, três pressões convergiram e tornaram essa postura muito mais difícil de ser mantida.
1- Pressão da plataforma
A primeira pressão é que o A camada da plataforma de IA não é mais opcional. Essa é a camada que define o que um sistema de IA sabe e o que pode fazer. Ela inclui prompts mestres e bibliotecas de habilidades, recuperação em bases vetoriais e bases de conhecimento estruturadas, protocolos de conexão que permitem que os agentes atuem em sistemas de negócios e a memória persistente que permite que eles mantenham o estado entre as sessões.
Há um ano, essa camada era uma direção de pesquisa interessante. Hoje, ela é um suporte de carga. As empresas que passaram de pilotos de chatbot para agentes implantados fizeram isso investindo nessa camada. As empresas que ainda estão executando pilotos geralmente ignoraram essa camada e tentaram conectar o contexto comercial diretamente aos prompts e às integrações no lado do aplicativo. Essa abordagem funciona para um caso de uso bem delimitado. Ele não se adapta a um portfólio de agentes que atuam em toda a empresa.
2- Pressão de custos
A segunda pressão é econômica. O preço subsidiado dos laboratórios de IA de fronteira está chegando ao fim. Os custos de inferência que costumavam ser absorvidos no nível do provedor de modelos estão sendo cada vez mais repassados, e os primeiros sinais não são sutis. Segundo informações, a Uber consumiu todo o seu orçamento do LLM 2026 nos primeiros quatro meses do ano. Esse tipo de excesso não é mais uma anedota de aquisição, é um sinal de que a economia de inferência merece um lugar na revisão trimestral do CTO.
A resposta não é usar menos IA. A resposta é um Estratégia de inferência deliberada usando roteamento inteligente entre modelos de fronteira e modelos menores, modelos ajustados ou especializados para tarefas de grande volume que não requerem raciocínio de fronteira e, em alguns casos, arreios personalizados criados com base em pesos de código aberto. A mudança que quase nenhuma empresa ainda tem em seu roteiro é treinar ou ajustar seus próprios modelos para as cargas de trabalho em que o volume o justifica. Pequenos modelos de linguagem, ajustes finos no estilo LoRA e arquiteturas específicas de domínio estão começando a parecer menos uma curiosidade de pesquisa e mais uma decisão de custo operacional.
3- Pressão da soberania
A terceira pressão é política e regulatória. Os requisitos de residência Data, a Lei de IA da UE, as regras específicas do setor de serviços financeiros e de saúde e a fragmentação geopolítica mais ampla da computação são empurrando as decisões de hardware e infraestrutura para a mesa do CTO pela primeira vez. A questão de quem detém as chaves da infraestrutura em que seus modelos são executados costumava ser um detalhe de aquisição de TI. Em 2026, ela se tornou uma questão de nível de diretoria para qualquer empresa que lide com data regulamentado ou opere em várias jurisdições.
Essa pressão também é diferente da conversa sobre a soberania do cloud há uma década, e vale a pena fazer uma pausa nessa diferença. O debate sobre o cloud foi sobre computação de commodities: servidores, armazenamento e largura de banda. Os seres humanos permaneciam no circuito de cada decisão significativa que a infraestrutura suportava. A infraestrutura de IA não é uma computação de commodity. O que é executado nessas GPUs é a inteligência, e para uma parcela cada vez maior dos processos de negócios, A infraestrutura não apenas apoiará uma decisão humana, ela tomará a decisão.
Isso muda o peso político de quem controla o hardware. Das três pressões, a Soberania é a mais sombria atualmente, pois o a maioria dos conselhos ainda não internalizou o que significa administrar uma empresa com inteligência que não lhes pertence. Isso se tornará muito mais claro quando a IA física começar a ser lançada em escala. As empresas que criaram uma estratégia deliberada de hardware até lá e que entendem como configurá-la para seu contexto provavelmente se encontrarão com um vantagem competitiva que leva anos para ser fechada.
Juntas, essas três pressões dissolvem a postura confortável de 2024. Nenhuma delas pode ser resolvida na camada de aplicativos. Cada uma delas puxa o CTO para uma parte diferente da pilha.
As quatro camadas, reduzidas à pergunta que cada uma responde
Para tomar uma decisão deliberada sobre a pilha, cada camada deve ser reduzida à pergunta que ela realmente responde.
A camada de aplicativos é a superfície onde os seres humanos e a IA se encontram. A questão é: onde os humanos encontram a IA em nossas operações e como eles colaboram? As opções variam de chatbots incorporados em ferramentas de produtividade a agentes acionados por uma mensagem no Teams ou no Slack, a agentes acionados por eventos de fluxo de trabalho e a agentes incorporados em sistemas de negócios como SAP ou Salesforce. O padrão certo depende da quantidade de humanos no circuito que o trabalho tolera.
A plataforma de IA é a camada que define o que a IA sabe e o que pode fazer. A questão é: Onde nossos agentes obtêm o contexto comercial e que autoridade podemos delegar a eles? As opções são: contexto estático (prompts mestre, habilidades, arquivos de regras estruturadas), recuperação de bases de conhecimento e armazenamentos de vetores, tomada de ações por meio de protocolos padronizados de conexão de agentes e memória persistente entre sessões. Cada opção corresponde a um nível diferente de autonomia concedida ao agente.
O LLM Infrastructure é a camada em que os modelos são acessados, roteados, governados e otimizados. A questão é: Como podemos encaminhar o modelo certo para o trabalho certo, com o custo certo? As opções variam de LLMs de ponta para raciocínio complexo, a modelos pequenos ou ajustados para tarefas bem definidas de alto volume, a modelos de modalidade especializados para compreensão de voz ou documentos, a modelos de ponta para trabalho crítico de latência. Essa é a camada em que a economia de inferência realmente vive.
A camada de hardware inclui as GPUs, os servidores de inferência e a orquestração que executam os modelos. A questão é: Onde nossos modelos são realmente executados e quem detém as chaves dessa infraestrutura? As opções vão desde a computação gerenciada pelo hyperscaler até a infraestrutura privada cloud ou dedicada, passando por clusters de inferência no local, silício personalizado ou computação incorporada. Para a maioria das empresas, a resposta é gerenciada pelo hyperscaler. Para os setores sensíveis ao data, a resposta é cada vez mais outra.
Essas quatro camadas não são estratégias separadas. Elas são uma única estratégia expressa em quatro níveis de profundidade.
Sequenciamento bate cobertura
A leitura honesta do quadro não é que todas as empresas devam possuir todas as camadas. Algumas das posições de IA mais defensáveis em 2026 pertencerão a empresas que escolheram conscientemente usar abstrações de hiperescalador na parte inferior da pilha e concentrar seus investimentos em outro lugar. O fato de o senhor possuir mais da pilha não é o argumento. O argumento é que a escolha deve ser deliberada.
Um CTO que tenha decidido onde a Microsoft, a AWS, o Google ou outro parceiro se situa em sua pilha e que tenha decidido em qual camada sua própria equipe investirá este ano tem uma estratégia. Um CTO que nunca tomou essa decisão está pagando por uma estratégia sem possuí-la. O custo dessa omissão aumenta: a equipe acaba com um portfólio de pilotos desconectados, uma conta de aquisição que cresce mais rápido do que o valor e nenhuma resposta clara quando a diretoria pergunta para onde deve ir o próximo ano de investimento.
O trabalho, portanto, é o sequenciamento. A questão não é qual camada deve ser própria e qual deve ser terceirizada, O senhor pode ter certeza de que a IA é uma das principais características da empresa, já que, em um horizonte suficientemente longo, toda empresa nativa de IA terá que se posicionar em todas as quatro. A questão é qual camada priorizar agora e qual revisitar em 12, 24 e 36 meses.
O arquétipo da empresa é o sinal mais forte para essa sequência: As start-ups, os serviços especializados de menor porte e as butiques geralmente podem manter seu investimento concentrado nas camadas de aplicativo e plataforma.
- Corporações multirregionais de CPG, B2B, farmacêutica, jurídica e de saúde normalmente precisam se estender para a camada de plataforma para gerenciar o contexto de negócios, com movimentos seletivos para a infraestrutura à medida que o volume de inferência aumenta.
- Corporações multirregionais com maior maturidade de IA, especialmente em serviços financeiros, telecomunicações e setores nativos digitais, Os clientes da Microsoft já estão tomando decisões reais de infraestrutura sobre roteamento, ajuste fino e residência.
- BigTech, governo e manufatura altamente especializada, O senhor pode ter certeza de que, quando a capacidade de IA em si é o produto ou o ativo estratégico, acaba fazendo escolhas reais na camada de hardware.
A questão não é que um arquétipo seja mais avançado do que outro. É que o A sequência das quatro camadas é diferente para cada uma. Uma empresa farmacêutica que tenta se comportar como a SpaceX na camada de hardware está desperdiçando capital. Um banco que se comporta como uma start-up na camada de plataforma está deixando seu principal ativo, seu contexto data, sem gerenciamento.
Transição para a nuvem, em um relógio mais rápido
O formato dessa transição já foi visto antes. Em 2012, a conversa sobre cloud na maioria das salas de reuniões era binária: devemos usar a AWS ou não? Em 2018, essa única pergunta havia se desdobrado em uma decisão de vários eixos sobre quais cargas de trabalho pertenciam a qual lugar, quais provedores se encaixavam em quais casos de uso, o que fazer com o multi-cloud e onde a residência do data era importante. As empresas que trataram o cloud como uma única decisão de aquisição em 2012 passaram os seis anos seguintes alcançando aquelas que o trataram como uma decisão de arquitetura desde o início.
A pilha de IA está passando pela mesma maturação em um clock muito mais rápido. O cloud levou quase uma década para se fragmentar de uma única pergunta em uma decisão em camadas. A pilha de IA está fazendo isso em três ou quatro anos. Os CTOs que tratam a IA em 2026 da mesma forma que os melhores trataram o cloud em 2012, como uma decisão de arquitetura em vez de uma decisão de aquisição, estão é provável que os senhores se encontrem vários anos à frente de seus pares até o final da década.
O que isso significa para o CTO este ano
Três movimentos, em particular, merecem um lugar na agenda.
A primeira é que o a camada da plataforma de IA merece uma propriedade explícita. Para a maioria das empresas que enviaram trabalhos no estilo Copilot nos últimos dois anos, essa é a camada em que os próximos 12 meses de investimento produzirão o retorno mais diferenciado. O contexto é a parte da pilha que não fica mais barata para digitalizar. Os modelos continuarão melhorando e os preços continuarão subindo. O conhecimento estruturado da própria empresa, as regras de decisão e os pontos de conexão com seus sistemas operacionais são o que dá significado a um modelo de negócios.
A segunda é que o a economia da inferência agora faz parte da agenda trimestral. Uma estratégia de inferência séria inclui roteamento inteligente, modelos pequenos ou ajustados para a camada de volume e, pelo menos, uma conversa exploratória sobre o treinamento interno para cargas de trabalho em que a economia da unidade o justifique. A curva de custo da inferência de fronteira não se moverá em uma única direção, e qualquer estratégia que dependa do preço de um único provedor é estruturalmente frágil.
A terceira é que o As escolhas de hardware e infraestrutura devem ser revisadas, mesmo que a resposta acabe sendo o hyperscaler por enquanto. A decisão de usar uma pilha gerenciada é legítima, mas deve ser uma decisão e não um padrão. Para os setores regulamentados, as questões de inferência soberana, implementação híbrida e pilhas no local não são mais hipotéticas.
Nenhuma dessas medidas exige a criação de tudo internamente. Elas exigem que se pense em cada camada com a mesma seriedade que a maioria das diretorias já aplica à camada de aplicativos.
Uma pergunta de cada vez
A arquitetura de uma empresa nativa de IA é decidida com base em uma pergunta de cada vez, e cada pergunta está em uma camada diferente. Os 20% visíveis são a parte fácil. O trabalho que compõe acontece abaixo da linha d'água, nas camadas que não aparecem em uma demonstração do fornecedor.
Os CTOs que param na camada visível acabam gerenciando ferramentas. Os CTOs que olham abaixo da linha d'água acabam gerenciando a capacidade cognitiva. A questão não é qual modelo comprar, mas que tipo de CTO a empresa decide se tornar: operacional ou estratégico.
