
")

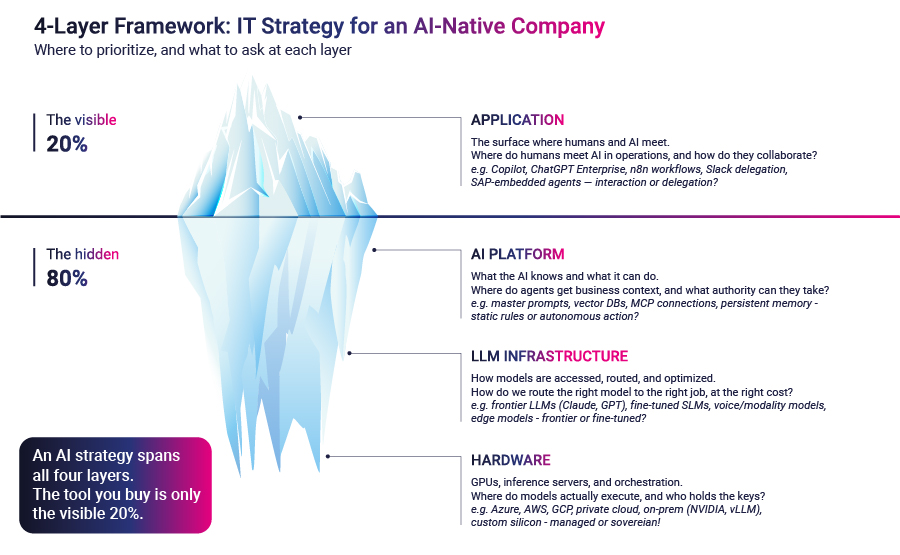
La mayoría de los directores de tecnología en 2026 están diseñando la estrategia de IA en la capa visible de la pila. Están comprando asientos de Copilot, desplegando chatbots empresariales y reuniendo una cartera de licencias de proveedores. El trabajo es real, y en muchas empresas ha producido un aumento apreciable de la productividad. También es, en cualquier lectura honesta del panorama, la 20% del iceberg que todo el mundo puede ver. El 80% que se encuentra bajo la línea de flotación es donde realmente se construye una organización agéntica. Los equipos que nunca miran hacia abajo seguirán pagando por chatbots mientras sus competidores se convierten silenciosamente en otra cosa.
La arquitectura de una empresa nativa de la IA se asienta en cuatro capas: Aplicación, Plataforma de IA, Infraestructura LLM y Hardware. La capa de aplicación es la que la mayoría de las juntas directivas ya han discutido. En las otras tres es donde se tomarán las verdaderas decisiones estratégicas de los próximos 24 meses.
La capa de aplicación es la superficie donde se encuentran los humanos y la IA. Incluye los chatbots integrados en las herramientas de productividad, los copilotos para desarrolladores, los creadores de agentes de bajo código y los agentes autónomos más avanzados que algunos equipos han empezado a comercializar. Comprar acceso a ello es un ejercicio de adquisición. Los proveedores son bien conocidos. Los precios están publicados. El despliegue es sobre todo un problema de gestión del cambio.
Esta es la razón por la que la mayoría de las conversaciones sobre la estrategia de la IA se detienen aquí. La capa de aplicación es legible para el comité ejecutivo, fácil de presupuestar y visible para el resto de la empresa en un trimestre. Produce historias que se traducen bien en un ayuntamiento.
También es la capa en la que la diferenciación competitiva es más difícil de construir. Todas las empresas de un sector compran a la misma lista reducida de proveedores. La interfaz está cada vez más estandarizada. La experiencia del usuario converge. Un despliegue de Copilot, por sí solo, no constituye todavía una estrategia. Es el acceso a una capacidad para la que la empresa no ha diseñado una arquitectura. Sin las capas subyacentes, ese acceso produce un chatbot, no un agente que pueda actuar dentro de la empresa.
Tres presiones que empujan a los CTO por debajo de la línea de flotación
Hasta hace poco, el argumento de dejar el resto de la pila a los hiperescaladores era defendible. En 2024, una empresa podía enviar un asistente interno útil sobre una API de frontera y considerar el trabajo hecho. Este año han convergido tres presiones que hacen que esa postura sea mucho más difícil de mantener.
1- Presión en la plataforma
La primera presión es que el La capa de la plataforma de IA ya no es opcional. Esta es la capa que define lo que un sistema de IA sabe y lo que puede hacer. Incluye los avisos maestros y las bibliotecas de habilidades, la recuperación contra bases de vectores data y bases de conocimientos estructuradas, los protocolos de conexión que permiten a los agentes actuar a través de los sistemas empresariales y la memoria persistente que les permite mantener el estado a través de las sesiones.
Hace un año, esta capa era una interesante dirección de investigación. Hoy es portante. Las empresas que han pasado de pilotos de chatbot a agentes desplegados lo han hecho invirtiendo aquí. Las empresas que aún realizan pilotos suelen saltarse esta capa e intentan cablear el contexto empresarial directamente en las indicaciones e integraciones en el lado de la aplicación. Ese enfoque funciona para un caso de uso bien delimitado. No se adapta a una cartera de agentes que actúan en toda la empresa.
2- Presión de los costes
La segunda presión es económica. Los precios subvencionados de los laboratorios de IA de frontera están llegando a su fin. Los costes de inferencia que solían absorberse a nivel del proveedor del modelo se están repercutiendo cada vez más, y las primeras señales no son sutiles. Al parecer, Uber ha consumido todo su presupuesto para el LLM 2026 en los cuatro primeros meses del año. Ese tipo de sobrecoste ya no es una anécdota de aprovisionamiento, es una señal de que la economía de la inferencia merece un lugar en la revisión trimestral del director de tecnología.
La respuesta no es utilizar menos IA. La respuesta es una estrategia de inferencia deliberada que utiliza el encaminamiento inteligente entre la frontera y modelos más pequeños, modelos afinados o especializados para tareas de gran volumen que no requieren razonamiento de frontera y, en algunos casos, arneses personalizados construidos en torno a pesos de código abierto. Lo que casi ninguna empresa tiene aún en su hoja de ruta es la formación o el ajuste de sus propios modelos para las cargas de trabajo cuyo volumen lo justifique. Los pequeños modelos lingüísticos, los ajustes al estilo LoRA y las arquitecturas específicas de cada dominio empiezan a parecerse menos a una curiosidad de investigación y más a una decisión de coste operativo.
3- Presión soberanista
La tercera presión es política y normativa. Los requisitos de residencia Data, la Ley de IA de la UE, las normas específicas del sector en los servicios financieros y la atención sanitaria, y la fragmentación geopolítica más amplia de la computación son empujando por primera vez las decisiones sobre hardware e infraestructura a la mesa del director de tecnología. La cuestión de quién tiene las llaves de la infraestructura sobre la que se ejecutan sus modelos solía ser un detalle de aprovisionamiento informático. En 2026 se ha convertido en una cuestión de nivel directivo para cualquier empresa que maneje data regulados o que opere a través de jurisdicciones.
Esta presión también es diferente en especie de la conversación cloud-soberanía de hace una década, y merece la pena detenerse en esa diferencia. El debate sobre la cloud giraba en torno a la informática de consumo: servidores, almacenamiento y ancho de banda. Los humanos permanecían en el bucle en cada decisión significativa que la infraestructura soportaba. La infraestructura de la IA no es informática de consumo. Lo que se ejecuta en estas GPU es inteligencia, y para una parte cada vez mayor de los procesos empresariales, la infraestructura no se limitará a apoyar una decisión humana, sino que tomará la decisión.
Eso cambia el peso político de quién controla el hardware. De las tres presiones, la soberanía es hoy la más ensombrecida, ya que La mayoría de los consejos de administración aún no han interiorizado lo que significa dirigir una empresa con inteligencia que no les pertenece. Esto quedará mucho más claro cuando la IA física empiece a comercializarse a gran escala. Las empresas que hayan construido una estrategia deliberada de Hardware para entonces, y que entiendan cómo configurarla para su contexto, probablemente se encontrarán con una ventaja competitiva que tarda años en cerrarse.
En conjunto, estas tres presiones disuelven la cómoda postura de 2024. Ninguna de ellas puede abordarse en la capa de aplicación. Cada una arrastra al CTO a una parte diferente de la pila.
Las cuatro capas, reducidas a la pregunta a la que cada una responde
Para tomar una decisión deliberada sobre la pila, hay que reducir cada capa a la pregunta a la que realmente responde.
La capa de aplicación es la superficie donde se encuentran los humanos y la IA. La cuestión es: ¿dónde se encuentran los humanos con la IA en nuestras operaciones y cómo colaboran? Las opciones van desde chatbots incrustados en herramientas de productividad, a agentes activados por un mensaje en Teams o Slack, a agentes activados por eventos del flujo de trabajo, a agentes incrustados dentro de sistemas empresariales como SAP o Salesforce. El patrón adecuado depende de cuánta presencia humana en el bucle tolere el trabajo.
La plataforma de IA es la capa que define lo que la IA sabe y lo que puede hacer. La cuestión es: ¿de dónde sacan nuestros agentes el contexto empresarial y qué autoridad podemos delegar en ellos? Las opciones son el contexto estático (indicaciones maestras, habilidades, archivos de reglas estructuradas), la recuperación contra bases de conocimiento y almacenes de vectores, la toma de acciones a través de protocolos estandarizados de conexión de agentes y la memoria persistente a través de las sesiones. Cada opción corresponde a un nivel diferente de autonomía que se concede al agente.
La infraestructura LLM es la capa en la que se accede a los modelos, se enrutan, se gobiernan y se optimizan. La cuestión es: ¿cómo dirigimos el modelo adecuado al trabajo adecuado, al coste adecuado? Las opciones van desde los LLM de frontera para razonamientos complejos, pasando por modelos pequeños o afinados para tareas de gran volumen bien definidas, hasta modelos de modalidad especializados para la comprensión de voz o documentos, o modelos de borde para trabajos de latencia crítica. Esta es la capa en la que vive realmente la economía de la inferencia.
La capa de hardware incluye las GPU, los servidores de inferencia y la orquestación que ejecutan los modelos. La cuestión es: ¿dónde se ejecutan realmente nuestros modelos y quién tiene las llaves de esa infraestructura? Las opciones van desde la informática gestionada por hyperscaler, a la infraestructura privada cloud o dedicada, a los clústeres de inferencia in situ, al silicio personalizado o la informática integrada. Para la mayoría de las empresas, la respuesta es el hiperescalador gestionado. Para las industrias sensibles al data, es cada vez más otra cosa.
Estas cuatro capas no son estrategias separadas. Son una sola estrategia expresada en cuatro niveles de profundidad.
La secuenciación bate la cobertura
La lectura honesta del panorama no es que todas las empresas deban poseer todas las capas. Algunas de las posiciones más defendibles de la IA en 2026 pertenecerán a empresas que hayan elegido conscientemente montar abstracciones hiperescalares en la parte inferior de la pila y concentrar su inversión en otro lugar. Poseer más de la pila no es el argumento. El argumento es que la elección tiene que ser deliberada.
Un CTO que ha decidido dónde se sitúa Microsoft, AWS, Google u otro socio en su pila, y que ha decidido en qué capa invertirá su propio equipo este año, tiene una estrategia. Un CTO que nunca tomó la decisión está pagando por una sin poseerla. El coste de esa omisión se agrava: el equipo acaba con una cartera de pilotos desconectados, una factura de adquisiciones que crece más rápido que el valor y ninguna respuesta clara cuando la junta directiva pregunta adónde debe ir el próximo año de inversión.
El trabajo, por tanto, es la secuenciación. La cuestión no es qué capa poseer y cuál externalizar, ya que en un horizonte lo suficientemente largo cada empresa nativa de la IA tendrá que adoptar una posición en las cuatro. La cuestión es qué capa priorizar ahora y cuál volver a revisar en 12, 24 y 36 meses.
El arquetipo de la empresa es la señal más fuerte para esa secuenciación: Las empresas de nueva creación, los servicios especializados más pequeños y las boutiques normalmente pueden mantener su inversión centrada en las capas de Aplicación y Plataforma.
- Corporaciones multiregionales en CPG, B2B, farmacéuticas, legales y sanitarias normalmente necesitan extenderse a la capa de Plataforma para gestionar su contexto empresarial, con movimientos selectivos hacia Infraestructura a medida que crece el volumen de inferencia.
- Corporaciones multirregionales con mayor madurez de IA, especialmente en servicios financieros, telecomunicaciones y sectores nativos digitales, ya están tomando decisiones reales de Infraestructura en torno al enrutamiento, la puesta a punto y la residencia.
- BigTech, gobierno y fabricación altamente especializada, donde la propia capacidad de IA es el producto o el activo estratégico, acaban tomando decisiones reales en la capa de Hardware.
No se trata de que un arquetipo sea más avanzado que otro. Se trata de que el La secuencia de las cuatro capas es diferente para cada una. Una empresa farmacéutica que intente comportarse como SpaceX en la capa de Hardware está malgastando capital. Un banco que se comporta como una start-up en la capa Plataforma está dejando sin gestionar su activo principal, su contexto data.
Transición a la nube, con un reloj más rápido
La forma de esta transición ya se ha visto antes. En 2012, la conversación cloud en la mayoría de las salas de juntas era binaria: ¿deberíamos usar AWS o no? En 2018, esa única pregunta se había convertido en una decisión multiaxial sobre qué cargas de trabajo pertenecían a dónde, qué proveedores encajaban en qué casos de uso, qué multi-cloud y dónde importaba la residencia data. Las empresas que trataron el cloud como una decisión de adquisición única en 2012 pasaron los seis años siguientes alcanzando a las que lo trataron como una decisión de arquitectura desde el principio.
La pila de IA está pasando por la misma maduración en un reloj mucho más rápido. El cloud tardó casi una década en pasar de una pregunta única a una decisión por capas. La pila de IA lo está haciendo en tres o cuatro años. Los CTO que traten la IA en 2026 como los mejores trataron el cloud en 2012, como una decisión de arquitectura y no de adquisición, son probablemente se encuentren varios años por delante de sus homólogos a finales de la década.
Lo que esto significa para el CTO este año
Tres movimientos, en particular, merecen un lugar en la agenda.
La primera es que la capa de la Plataforma de IA merece una apropiación explícita. Para la mayoría de las empresas que han realizado trabajos del tipo Copilot en los últimos dos años, ésta es la capa en la que los próximos 12 meses de inversión producirán el rendimiento más diferenciado. El contexto es la parte de la pila cuya digitalización no resulta más barata. Los modelos seguirán mejorando y los precios seguirán moviéndose. El propio conocimiento estructurado de la empresa, las reglas de decisión y los puntos de conexión con sus sistemas operativos son lo que dan sentido a un modelo de negocio.
La segunda es que la economía de la inferencia ya forma parte de la agenda trimestral. Una estrategia de inferencia seria incluye un enrutamiento inteligente, modelos pequeños o afinados para el nivel de volumen y, al menos, una conversación exploratoria sobre la formación interna para las cargas de trabajo en las que la economía unitaria lo justifique. La curva de costes de la inferencia en la frontera no se moverá en una única dirección, y cualquier estrategia que dependa de los precios de un único proveedor es estructuralmente frágil.
La tercera es que Deberían revisarse las opciones de hardware e infraestructura, aunque la respuesta acabe siendo hyperscaler por ahora. La decisión de montar una pila gestionada es legítima, pero debería ser una decisión y no un defecto. Para las industrias reguladas, las cuestiones de la inferencia soberana, el despliegue híbrido y las pilas in situ ya no son hipotéticas.
Ninguno de estos movimientos requiere construirlo todo internamente. Requieren pensar en cada capa con la misma seriedad que la mayoría de las juntas directivas ya aplican a la capa de Aplicación.
Una pregunta cada vez
La arquitectura de una empresa nativa de la IA se decide pregunta a pregunta, y cada pregunta vive en una capa diferente. El 20% visible es la parte fácil. El trabajo que compone sucede por debajo de la línea de flotación, en las capas que no aparecen en una demostración de un proveedor.
Los CTO que se detienen en la capa visible acaban gestionando herramientas. Los CTO que miran por debajo de la línea de flotación acaban gestionando la capacidad cognitiva. La cuestión no es qué modelo comprar, sino en qué tipo de CTO decide convertirse la empresa: operativo o estratégico.
