
")

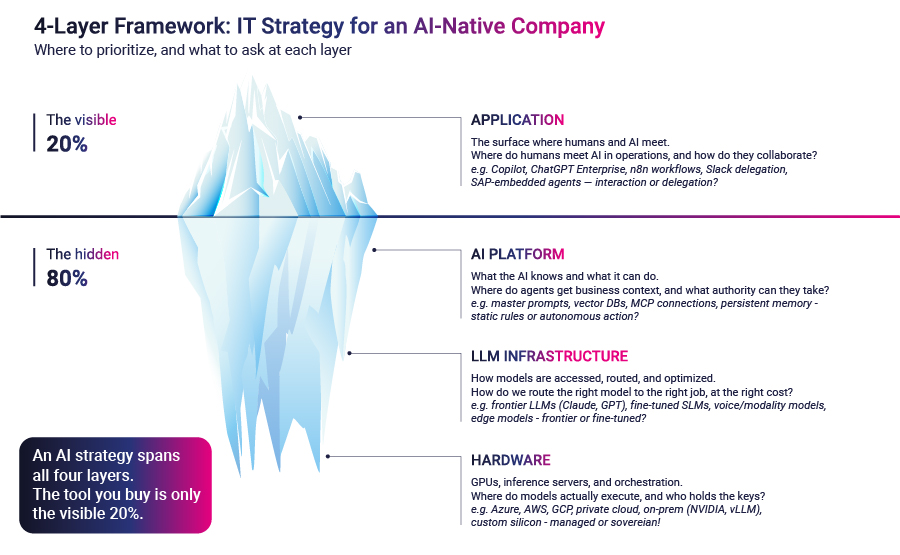
De meeste CTO's in 2026 ontwerpen een AI-strategie op de zichtbare laag van de stack. Ze kopen Copilot-zetels, rollen chatbots uit en stellen een portfolio van leverancierslicenties samen. Het werk is echt, en in veel bedrijven heeft het een meetbare productiviteitsstijging opgeleverd. Het is ook, bij elke eerlijke lezing van het plaatje, het 20% van de ijsberg die iedereen kan zien. De 80% die zich onder de waterlijn bevindt, is waar een agentschappelijke organisatie daadwerkelijk wordt opgebouwd. Teams die nooit naar beneden kijken, zullen blijven betalen voor chatbots terwijl hun concurrenten stilletjes iets anders worden.
De architectuur van een AI-native bedrijf bestaat uit vier lagen: Toepassing, AI-platform, LLM-infrastructuur en hardware. De toepassingslaag is degene die de meeste besturen al hebben besproken. In de andere drie worden de echte strategische beslissingen voor de komende 24 maanden genomen.
De toepassingslaag is het oppervlak waar mensen en AI elkaar ontmoeten. Het omvat de chatbots die zijn ingebed in productiviteitstools, de copilots voor ontwikkelaars, de low-code agentbouwers en de meer geavanceerde autonome agents die sommige teams beginnen te leveren. Toegang kopen is een inkoopexercitie. De leveranciers zijn bekend. De prijzen zijn gepubliceerd. De implementatie is meestal een probleem van verandermanagement.
Daarom houden de meeste gesprekken over AI-strategieën hier op. De toepassingslaag is leesbaar voor het directiecomité, gemakkelijk te budgetteren en binnen een kwartaal zichtbaar voor de rest van het bedrijf. Het levert verhalen op die zich goed laten vertalen naar een gemeentehuis.
Het is ook de laag waar differentiatie van de concurrentie het moeilijkst op te bouwen is. Elk bedrijf in een sector koopt van dezelfde korte lijst van leveranciers. De interface wordt steeds meer gestandaardiseerd. De gebruikerservaring convergeert. Een Copilot uitrol vormt op zichzelf nog geen strategie. Het is toegang tot een mogelijkheid waarvoor het bedrijf niet ontworpen is. Zonder de lagen eronder levert die toegang een chatbot op, geen agent die binnen het bedrijf kan handelen.
Drie drukfactoren die CTO's onder de waterlijn duwen
Tot voor kort was het verdedigbaar om de rest van de stack aan hyperscalers over te laten. In 2024 kon een bedrijf een nuttige interne assistent bovenop een grensverleggende API leveren en het werk als gedaan beschouwen. Dit jaar zijn er drie factoren samengekomen die deze houding veel moeilijker houdbaar maken.
1- Platformdruk
De eerste druk is dat de AI-platformlaag is niet langer optioneel. Dit is de laag die bepaalt wat een AI-systeem weet en kan. Deze laag omvat hoofdprompts en vaardigheidsbibliotheken, ophalen uit vector databases en gestructureerde kennisbanken, verbindingsprotocollen waarmee agents in verschillende bedrijfssystemen kunnen handelen, en het permanente geheugen waarmee ze de status van sessies kunnen behouden.
Een jaar geleden was deze laag een interessante onderzoeksrichting. Vandaag is het dragend. Bedrijven die van chatbotpilots naar ingezette agents zijn gegaan, hebben dat gedaan door hier te investeren. Bedrijven die nog steeds pilots uitvoeren, hebben deze laag meestal overgeslagen en geprobeerd om de bedrijfscontext rechtstreeks in prompts en integraties aan de applicatiekant te integreren. Die aanpak werkt voor één goed afgebakende use case. Het is niet geschikt voor een portefeuille van agenten die in het hele bedrijf actief zijn.
2- Kostendruk
De tweede druk is economisch. Er komt een einde aan de gesubsidieerde prijzen van grensverleggende AI-laboratoria. Inferentiekosten die vroeger werden geabsorbeerd op het niveau van de model-provider worden steeds vaker doorberekend, en de eerste signalen zijn niet subtiel. Naar verluidt heeft Uber in de eerste vier maanden van het jaar zijn volledige budget voor 2026 LLM verbruikt. Een dergelijke overschrijding is niet langer een inkoopanekdote, maar een signaal dat inferentie-economie een plaats verdient in het kwartaaloverzicht van de CTO.
Het antwoord is niet om minder AI te gebruiken. Het antwoord is een doelbewuste inferentiestrategie met slimme routering tussen frontier- en kleinere modellen, verfijnde of gespecialiseerde modellen voor taken met een groot volume die geen grensredenering vereisen, en in sommige gevallen aangepaste harnassen die gebouwd zijn rond open-source gewichten. De stap die bijna geen enkele onderneming nog op de planning heeft staan, is het trainen of verfijnen van eigen modellen voor de werklasten waarbij het volume dit rechtvaardigt. Kleine taalmodellen, LoRA-stijl fijnafstellingen, en domeinspecifieke architecturen beginnen minder op een onderzoekscuriositeit te lijken en meer op een beslissing over operationele kosten.
3- Soevereiniteitsdruk
De derde druk is politiek en regelgevend. Data verblijfsvereisten, de AI-wet van de EU, sectorspecifieke regels in de financiële dienstverlening en gezondheidszorg, en de bredere geopolitieke fragmentatie van compute zijn waardoor beslissingen over hardware en infrastructuur voor het eerst op het bureau van de CTO komen te liggen. De vraag wie de sleutels heeft van de infrastructuur waarop uw modellen draaien, was vroeger een IT-aankoopkwestie. In 2026 is het een vraag op directieniveau geworden voor elk bedrijf dat gereguleerde data verwerkt of in verschillende jurisdicties opereert.
Deze druk is ook anders dan het gesprek over cloud-soevereiniteit tien jaar geleden, en dat verschil is het waard om even bij stil te staan. Het cloud-debat ging over commodity computing: servers, opslag en bandbreedte. Mensen bleven betrokken bij elke zinvolle beslissing die de infrastructuur ondersteunde. AI-infrastructuur is geen commodity computing. Wat op deze GPU's draait is intelligentie, en voor een steeds groter deel van de bedrijfsprocessen, de infrastructuur zal niet alleen een menselijke beslissing ondersteunen, maar ook de beslissing nemen.
Dat verandert het politieke gewicht van wie de hardware controleert. Van de drie vormen van druk is Soevereiniteit vandaag de dag het meest overschaduwd, omdat De meeste raden van bestuur hebben zich nog niet eigen gemaakt van wat het betekent om een bedrijf te runnen op intelligentie die zij niet bezitten. Het zal veel duidelijker worden zodra Fysieke AI op grote schaal wordt geleverd. Bedrijven die tegen die tijd een weloverwogen hardwarestrategie hebben ontwikkeld en die begrijpen hoe ze die voor hun context moeten instellen, zullen waarschijnlijk een voorsprong hebben op de rest van de wereld. concurrentievoordeel dat jaren duurt om te sluiten.
Samen lossen deze drie vormen van druk de comfortabele houding van 2024 op. Ze kunnen geen van alle worden aangepakt op de applicatielaag. Elke druk trekt de CTO naar een ander deel van de stapel.
De vier lagen, teruggebracht tot de vraag die elke laag beantwoordt
Om een weloverwogen beslissing over de stapel te nemen, moet elke laag worden teruggebracht tot de vraag die hij eigenlijk beantwoordt.
De toepassingslaag is het oppervlak waar mensen en AI elkaar ontmoeten. De vraag is: waar ontmoeten mensen AI in onze activiteiten, en hoe werken ze samen? De keuzes variëren van chatbots die in productiviteitstools zijn ingebouwd, tot agents die worden geactiveerd door een bericht in Teams of Slack, tot agents die worden geactiveerd door workflowgebeurtenissen, tot agents die in bedrijfssystemen zoals SAP of Salesforce zijn ingebed. Het juiste patroon hangt af van hoeveel mens-in-de-lus het werk toelaat.
AI Platform is de laag die bepaalt wat de AI weet en kan. De vraag is: waar krijgen onze agenten zakelijke context, en welke autoriteit kunnen we aan hen delegeren? De keuzes zijn statische context (hoofdprompts, vaardigheden, gestructureerde regelbestanden), ophalen uit kennisbanken en vectoropslag, actie ondernemen via gestandaardiseerde verbindingsprotocollen voor agenten, en persistent geheugen over sessies heen. Elke keuze komt overeen met een ander niveau van autonomie dat aan de agent wordt toegekend.
LLM Infrastructuur is de laag waar modellen worden benaderd, gerouteerd, beheerd en geoptimaliseerd. De vraag is: Hoe leiden we het juiste model naar de juiste taak, tegen de juiste kosten? De keuzemogelijkheden variëren van frontier LLM's voor complexe redeneringen, tot kleine of fijn afgestemde modellen voor taken met een hoog volume, tot gespecialiseerde modaliteitsmodellen voor spraak- of documentbegrip, tot randmodellen voor werk waarbij de latentie van belang is. Dit is de laag waar inferentie-economieën eigenlijk leven.
De hardwarelaag omvat de GPU's, inferentieservers en orkestratie die de modellen uitvoeren. De vraag is: Waar worden onze modellen eigenlijk uitgevoerd en wie heeft de sleutels tot die infrastructuur? De keuzes lopen van door hyperscaler beheerde compute, tot privé cloud of dedicated infrastructuur, tot on-premise inferentieclusters, tot op maat gemaakte silicium of embedded compute. Voor de meeste ondernemingen is het antwoord hyperscaler-managed. Voor data-gevoelige industrieën is het steeds iets anders.
Deze vier lagen zijn geen afzonderlijke strategieën. Ze zijn één strategie, uitgedrukt op vier niveaus van diepte.
Sequencing verslaat dekking
De eerlijke lezing van het plaatje is niet dat elk bedrijf elke laag zou moeten bezitten. Sommige van de meest verdedigbare AI-posities in 2026 zullen in handen zijn van bedrijven die er bewust voor kiezen om hyperscalerabstracties onderaan de stack te gebruiken en hun investeringen ergens anders op te concentreren. Meer van de stapel bezitten is niet het argument. Het argument is dat de keuze weloverwogen moet zijn.
Een CTO die besloten heeft waar Microsoft, AWS, Google of een andere partner in hun stack zit, en die besloten heeft in welke laag hun eigen team dit jaar zal investeren, heeft een strategie. Een CTO die deze beslissing nooit heeft genomen, betaalt ervoor zonder er eigenaar van te zijn. De kosten van dat verzuim stapelen zich op: het team eindigt met een portfolio van losgekoppelde pilots, een inkooprekening die sneller groeit dan de waarde, en geen duidelijk antwoord wanneer de directie vraagt waar het volgende jaar van de investering naartoe moet gaan.
Het werk is dus volgordebepaling. De vraag is niet welke laag u moet bezitten en welke u moet uitbesteden, omdat over een voldoende lange horizon elk AI-bedrijf een positie zal moeten innemen op alle vier. De vraag is welke laag nu prioriteit moet krijgen en welke laag over 12, 24 en 36 maanden opnieuw bekeken moet worden.
Het archetype van het bedrijf is het sterkste signaal voor die opeenvolging: Start-ups, kleinere gespecialiseerde diensten en boetieks kunnen hun investeringen meestal gericht houden op de applicatie- en platformlagen.
- Multiregionale bedrijven in CPG, B2B, farma, juridisch en gezondheidszorg moeten meestal uitbreiden naar de platformlaag om hun bedrijfscontext te beheren, met selectieve verhuizingen naar de infrastructuur naarmate het inferentievolume toeneemt.
- Multiregionale bedrijven met een hogere AI-volwassenheid, vooral in financiële diensten, telecommunicatie en digital-native sectoren, maken al echte infrastructuurbeslissingen over routering, fijnafstemming en residentie.
- BigTech, overheid en zeer gespecialiseerde productie, waarbij de AI-capaciteit zelf het product of de strategische asset is, uiteindelijk echte keuzes maken op de hardwarelaag.
Het punt is niet dat het ene archetype geavanceerder is dan het andere. Het is dat het De volgorde van de vier lagen is voor elke laag anders. Een farmaceutisch bedrijf dat zich op de hardwarelaag als SpaceX probeert te gedragen, verspilt kapitaal. Een bank die zich op de platformlaag gedraagt als een start-up, laat haar kernactiva, haar data-context, onbeheerd achter.
Cloud overgang, op een snellere klok
De vorm van deze overgang is al eerder gezien. In 2012 was het cloud-gesprek in de meeste directiekamers binair: moeten we AWS gebruiken of niet? In 2018 was die ene vraag uitgegroeid tot een beslissing met meerdere assen over welke werklasten waar thuishoorden, welke providers bij welke use cases pasten, wat er met meerdere cloud moest gebeuren en waar data residentie van belang was. De bedrijven die cloud in 2012 als één inkoopbeslissing behandelden, hebben de volgende zes jaar de bedrijven ingehaald die het vanaf het begin als een architectuurbeslissing behandelden.
De AI-stapel ondergaat dezelfde rijping op een veel snellere klok. De cloud had bijna een decennium nodig om van een enkele vraag een gelaagde beslissing te maken. De AI-stapel doet dit in drie tot vier jaar. CTO's die AI in 2026 behandelen zoals de besten cloud in 2012 behandelden, als een architectuurbeslissing in plaats van een aankoopbeslissing, zijn tegen het einde van het decennium waarschijnlijk enkele jaren voor liggen op hun leeftijdsgenoten.
Wat dit betekent voor de CTO dit jaar
Drie zetten in het bijzonder verdienen een plaats op de agenda.
De eerste is dat verdient de AI-platformlaag expliciet eigendom. Voor de meeste bedrijven die de afgelopen twee jaar Copilot-achtig werk hebben geleverd, is dit de laag waarin de komende 12 maanden van investeringen het meest gedifferentieerde rendement zullen opleveren. Context is het deel van de stapel dat niet goedkoper wordt om te digitaliseren. Modellen zullen blijven verbeteren en prijzen zullen blijven bewegen. De eigen gestructureerde kennis, beslisregels en verbindingspunten met de operationele systemen van het bedrijf geven een model business betekenis.
De tweede is dat inferentie-economie hoort nu thuis op de kwartaalagenda. Een serieuze inferentiestrategie omvat slimme routering, kleine of verfijnde modellen voor het volumegedeelte, en op zijn minst een verkennend gesprek over interne training voor werklasten waarbij de kosten per eenheid dit rechtvaardigen. De kostencurve van frontier-inferentie zal niet in één enkele richting bewegen, en elke strategie die afhankelijk is van de prijzen van één aanbieder is structureel kwetsbaar.
De derde is dat Hardware- en infrastructuurkeuzes moeten opnieuw worden bekeken, zelfs als het antwoord uiteindelijk hyperscaler wordt. De beslissing om een beheerde stack te gebruiken is legitiem, maar het moet een beslissing zijn in plaats van een standaard. Voor gereguleerde sectoren zijn de kwesties van soevereine inferentie, hybride implementatie en on-premise stacks niet langer hypothetisch.
Voor geen van deze stappen is het nodig om alles intern te bouwen. Ze vereisen dat er over elke laag wordt nagedacht met dezelfde ernst die de meeste directies al toepassen op de applicatielaag.
Eén vraag per keer
De architectuur van een AI-native bedrijf wordt één vraag per keer bepaald, en elke vraag leeft in een andere laag. De zichtbare 20 procent is het makkelijke deel. Het werk dat verbindingen maakt, gebeurt onder de waterlijn, in de lagen die niet zichtbaar zijn in een demo van een verkoper.
CTO's die stoppen bij de zichtbare laag eindigen met het beheren van tools. CTO's die onder de waterlijn kijken, eindigen met het beheren van cognitieve capaciteit. De vraag is niet welk model te kopen, maar welk soort CTO het bedrijf besluit te worden: operationeel of strategisch.
