

Author


MLflow is a commonly used tool for machine learning experiments tracking, models versioning, and serving. In our first article of the series “Serving ML models at scale”, we explain how to deploy the tracking instance on Kubernetes and use it to log experiments and store models.
Part 1 — How to deploy Mlflow tracking instance on Kubernetes?
Introduction
Mlflow is a widely used tool in the data science/ML community to track experiments and manage machine learning models at different stages. Using it, we can store metrics, models, and artifacts to easily compare models’ performances and handle their life cycles. Besides, Mlflow provides a module to serve models as an API endpoint which facilitates their integration to any product or web app.
That being said, using machine learning in products online is cool, but depending on model size, nature (ML, deep learning,… ), and load (users’ requests) it could be challenging to dimension the needed resources and guarantee a reasonable response time. Therefore, using a scalable infrastructure such as Kubernetes clusters is key to maintain service availability and performance in the inference phase.
In this context, we are publishing a three-article series in which we answer the following questions:
So let’s start this first article by introducing Kubernetes and its components and go through the deployment of a tracking instance to log models.
Overview on Kubernetes
Kubernetes is an open-source project, released by Google in 2014. It is a container control and orchestration system that allows automatic applications deployment, scaling, and scheduling. It has the following architecture:
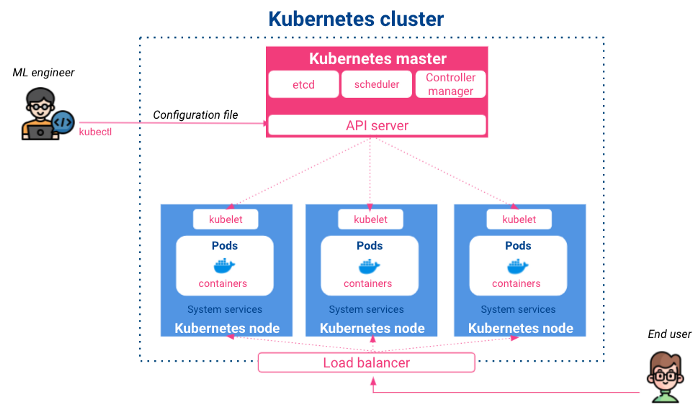
Master: It handles input configurations, schedules containerized apps on the different nodes, and monitors their states. The master is composed of:
Nodes: they are the execution nodes in which deployed containers live. Their main components are:
It’s the go-to choice when an application has multiple services communicating with each other as it ensures that every service has its own containerized environment with a set of rules to interact with others. Besides, it offers the interesting capability to scale up an application without worrying about managing or synchronizing new services and to balance resources between different machines.
From a high-level perspective, as data scientists or ML engineers, we will interact with Kubernetes via its server API using CLI commands or YAML config files either to deploy and expose apps or get our resources states.
Hands-on pre-requirements
For this hands-on, we will use GCP as a cloud provider. First, we need to :
1. Create the infrastructural elements
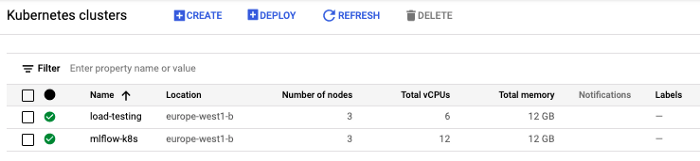
2. Configure the local workstation
3. Clone the hands-on project repository to get the code
Mlflow Tracking instance deployment
1. Setup the Cluster environment

2. Tracking server deployment
Once the image is pushed to the image registry we can deploy it on the cluster via helm using the below commands.
helm repo add mlflow-tracking https://artefactory-global.github.io/mlflow-tracking-server/helm install mlf-ts mlflow-tracking/mlflow-tracking-server --set env.mlflowArtifactPath=$ --set env.mlflowDBAddr=mlf-db-postgresql --set env.mlflowUser=postgres --set env.mlflowPass=mlflow --set env.mlflowDBName=mlflow_db --set env.mlflowDBPort=5432 --set service.type=LoadBalancer --set image.repository=$/mlflow-tracking-server --set image.tag=v1
Now, Mlflow should be up and running and the UI should be accessible via the load balancer IP. We can check the assigned IP using kubectl get services.Also, we can debug the deployment by accessing logs via kubectl describe pods.
So far, our current architecture looks like the following:
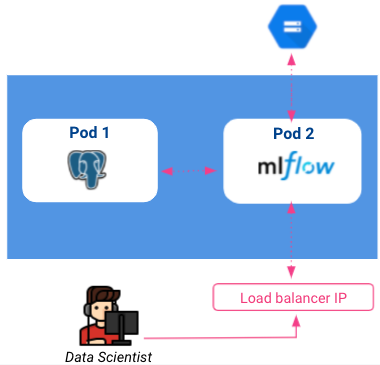
Please note that load balancers are accessible to anyone on the internet, so it is essential to think about securing our tracking instance by adding an authentication layer. This could be done with the identity-aware proxy on GCP but won’t be tackled in this article.
3. Basic model creation
Now that our infrastructure and Mlflow instance are ready, we can try to run a simple ML model and save it in the model registry for later use.
We will be using the wine-quality dataset which is composed of around 4900 samples and 11 features reflecting wine characteristics. The label ranges from 3 to 9 and could be seen as ratings.
This is a classic example, in which we train an Xgboost regression model and store it along with its parameters and metrics. The full code could be found in this notebook.
You may have noticed that Mlflow integration is straightforward and it could be summarized in the below code snippet that invokes mlflow.start_run(), mlflow.log_param(), mlflow.log_metric() and mlflow.xgboost.log_model()to respectively create a new experiment, store the training parameters, the evaluation metrics and the trained model itself.
By running the provided notebook, a new row will be added in the tracking instance interface that corresponds to the new experiment.
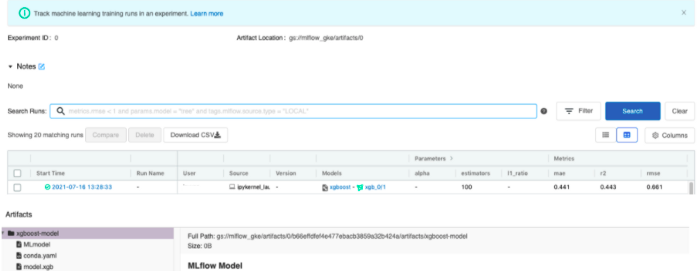
Finally, supposing that we are satisfied with the model performance, we can load it from the tracking instance and use it for inference in python. This could be done also with the notebook shared previously. Notice that in this example, we loaded the model using the run ID but keep in mind that Mlflow offers also other interesting ways to identify models by tags, versions, or stages. For more details please refer to the model registry documentation here.
Conclusion
Throughout this article, we managed to deploy Mlflow tracking instance to handle our data science experiments and we went through a quick example showing how to log a model and save it for future inference on python. In the next article of this series, we will learn how to serve this model as an API. This has great importance as it facilitates the interaction with the model and its integration into a product or an application. Moreover, doing it on Kubernetes ensures that it remains easily scalable and able to handle different load levels.
