

Autor


O MLflow é uma ferramenta comumente usada para rastreamento de experimentos de aprendizado de máquina, controle de versão de modelos e fornecimento. Em nosso primeiro artigo da série “Servindo modelos de ML em escala”, explicamos como implantar a instância de rastreamento no Kubernetes e usá-la para registrar experimentos e armazenar modelos.
Parte 1 - Como implantar a instância de rastreamento do Mlflow no Kubernetes?
Introdução
O Mlflow é uma ferramenta amplamente usada na comunidade científica/ML do data para rastrear experimentos e gerenciar modelos de aprendizado de máquina em diferentes estágios. Com ela, podemos armazenar métricas, modelos e artefatos para comparar facilmente o desempenho dos modelos e lidar com seus ciclos de vida. Além disso, o Mlflow fornece um módulo para servir modelos como um endpoint de API que facilita sua integração a qualquer produto ou aplicativo da Web.
Dito isso, usar o aprendizado de máquina em produtos on-line é legal, mas dependendo do tamanho do modelo, da natureza (ML, aprendizado profundo,...) e da carga (solicitações dos usuários), pode ser um desafio dimensionar os recursos necessários e garantir um tempo de resposta razoável. Portanto, usar uma infraestrutura dimensionável, como clusters Kubernetes, é fundamental para manter a disponibilidade e o desempenho do serviço na fase de inferência.
Nesse contexto, estamos publicando uma série de três artigos nos quais respondemos às seguintes perguntas:
Portanto, vamos começar este primeiro artigo apresentando o Kubernetes e seus componentes e analisar a implantação de uma instância de rastreamento para modelos de registro.
Visão geral do Kubernetes
O Kubernetes é um projeto de código aberto, lançado pelo Google em 2014. É um sistema de controle e orquestração de contêineres que permite a implantação, o dimensionamento e o agendamento automáticos de aplicativos. Ele tem a seguinte arquitetura:
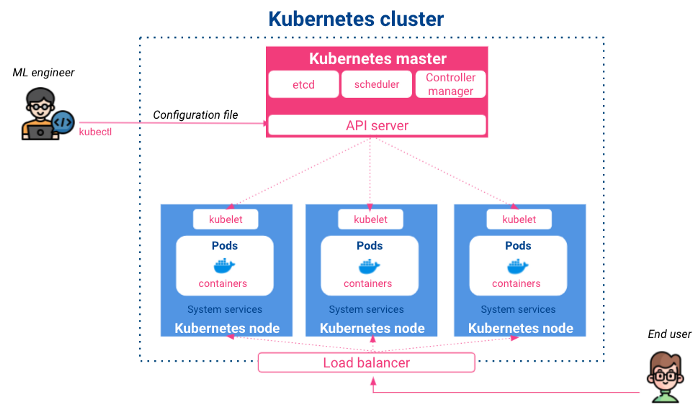
Mestre: Ele lida com as configurações de entrada, programa aplicativos em contêineres nos diferentes nós e monitora seus estados. O mestre é composto por:
Nós: Eles são os nós de execução nos quais vivem os contêineres implantados. Seus principais componentes são:
É a opção ideal quando um aplicativo tem vários serviços que se comunicam entre si, pois garante que cada serviço tenha seu próprio ambiente em contêiner com um conjunto de regras para interagir com os outros. Além disso, ele oferece o recurso interessante de dimensionar um aplicativo sem se preocupar com o gerenciamento ou a sincronização de novos serviços e com o equilíbrio de recursos entre diferentes máquinas.
De uma perspectiva de alto nível, como cientistas data ou engenheiros de ML, interagiremos com o Kubernetes por meio de sua API de servidor usando comandos CLI ou arquivos de configuração YAML para implantar e expor aplicativos ou obter os estados de nossos recursos.
Pré-requisitos práticos
Para esta prática, usaremos o GCP como um provedor cloud. Primeiro, precisamos do :
1. Criar os elementos de infraestrutura
2. Configurar a estação de trabalho local
3. Clone o repositório do projeto prático para obter o código
Implementação da instância do Mlflow Tracking
1. Configurar o ambiente do cluster

2. Rastreamento da implantação do servidor
Depois que a imagem é enviada para o registro de imagens, podemos implantá-la no cluster por meio do helm usando os comandos abaixo.
helm repo add mlflow-tracking https://artefactory-global.github.io/mlflow-tracking-server/helm install mlf-ts mlflow-tracking/mlflow-tracking-server --set env.mlflowArtifactPath=$ --set env.mlflowDBAddr=mlf-db-postgresql --set env.mlflowUser=postgres --set env.mlflowPass=mlflow --set env.mlflowDBName=mlflow_db --set env.mlflowDBPort=5432 --set service.type=LoadBalancer --set image.repository=$/mlflow-tracking-server --set image.tag=v1
Agora, o Mlflow deve estar funcionando e a interface do usuário deve estar acessível por meio do IP do balanceador de carga. Podemos verificar o IP atribuído usando kubectl get services.AAlém disso, podemos depurar a implantação acessando os registros via kubectl describe pods.
Até o momento, nossa arquitetura atual é parecida com a seguinte:
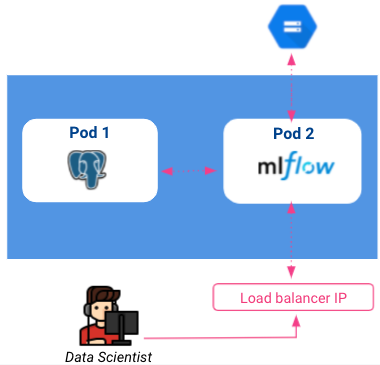
Observe que os balanceadores de carga são acessíveis a qualquer pessoa na Internet, portanto, é essencial pensar em proteger nossa instância de rastreamento adicionando uma camada de autenticação. Isso pode ser feito com o proxy com reconhecimento de identidade no GCP, mas não será abordado neste artigo.
3. Criação de modelos básicos
Agora que nossa infraestrutura e a instância do MLflow estão prontas, podemos tentar executar um modelo simples de ML e salvá-lo no registro de modelos para uso posterior.
Usaremos o conjunto dataset de qualidade do vinho, que é composto por cerca de 4900 amostras e 11 recursos que refletem as características do vinho. O rótulo varia de 3 a 9 e pode ser visto como classificações.
Esse é um exemplo clássico, no qual treinamos um modelo de regressão Xgboost e o armazenamos junto com seus parâmetros e métricas. O código completo pode ser encontrado no seguinte notebook.
O senhor deve ter notado que a integração com o Mlflow é simples e pode ser resumida no trecho de código abaixo que invoca mlflow.start_run(), mlflow.log_param(), mlflow.log_metric() e mlflow.xgboost.log_model()para, respectivamente, criar um novo experimento, armazenar os parâmetros de treinamento, as métricas de avaliação e o próprio modelo treinado.
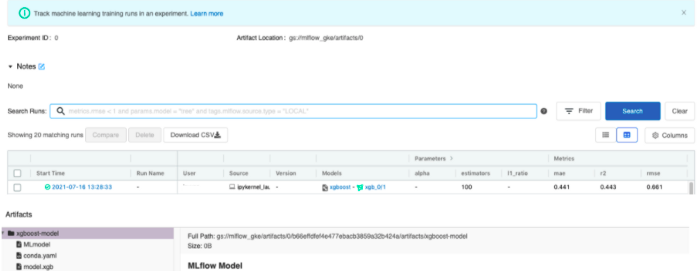
Ao executar o notebook fornecido, uma nova linha será adicionada na interface da instância de rastreamento que corresponde ao novo experimento.
Por fim, supondo que estejamos satisfeitos com o desempenho do modelo, podemos carregá-lo a partir da instância de rastreamento e usá-lo para inferência em python. Isso também pode ser feito com o notebook compartilhado anteriormente. Observe que, neste exemplo, carregamos o modelo usando o ID de execução, mas lembre-se de que o Mlflow também oferece outras maneiras interessantes de identificar modelos por tags, versões ou estágios. Para obter mais detalhes, consulte a documentação de registro do modelo aqui.
Conclusão
Ao longo deste artigo, conseguimos implantar a instância de rastreamento do Mlflow para lidar com nossos experimentos científicos data e passamos por um exemplo rápido que mostra como registrar um modelo e salvá-lo para inferência futura em python. No próximo artigo desta série, aprenderemos a servir esse modelo como uma API. Isso é muito importante, pois facilita a interação com o modelo e sua integração em um produto ou aplicativo. Além disso, fazer isso no Kubernetes garante que ele permaneça facilmente dimensionável e capaz de lidar com diferentes níveis de carga.
