

Autor


MLflow es una herramienta de uso común para el seguimiento de experimentos de aprendizaje automático, versionado de modelos y servicio. En nuestro primer artículo de la serie “Servir modelos ML a escala”, explicamos cómo desplegar la instancia de seguimiento en Kubernetes y utilizarla para registrar experimentos y almacenar modelos.
Parte 1 - ¿Cómo desplegar la instancia de seguimiento de Mlflow en Kubernetes?
Introducción
Mlflow es una herramienta muy utilizada en la comunidad científica/ML de data para hacer un seguimiento de los experimentos y gestionar los modelos de aprendizaje automático en diferentes etapas. Utilizándola, podemos almacenar métricas, modelos y artefactos para comparar fácilmente el rendimiento de los modelos y gestionar sus ciclos de vida. Además, Mlflow proporciona un módulo para servir modelos como un punto final API que facilita su integración en cualquier producto o aplicación web.
Dicho esto, utilizar el aprendizaje automático en productos en línea es genial, pero dependiendo del tamaño del modelo, la naturaleza (ML, aprendizaje profundo,... ) y la carga (solicitudes de los usuarios) podría ser un reto dimensionar los recursos necesarios y garantizar un tiempo de respuesta razonable. Por lo tanto, utilizar una infraestructura escalable como los clústeres Kubernetes es clave para mantener la disponibilidad y el rendimiento del servicio en la fase de inferencia.
En este contexto, publicamos una serie de tres artículos en los que respondemos a las siguientes preguntas:
Así que empecemos este primer artículo introduciendo Kubernetes y sus componentes y pasemos por el despliegue de una instancia de rastreo a modelos de registro.
Visión general sobre Kubernetes
Kubernetes es un proyecto de código abierto, lanzado por Google en 2014. Es un sistema de control y orquestación de contenedores que permite el despliegue, escalado y programación automáticos de aplicaciones. Tiene la siguiente arquitectura:
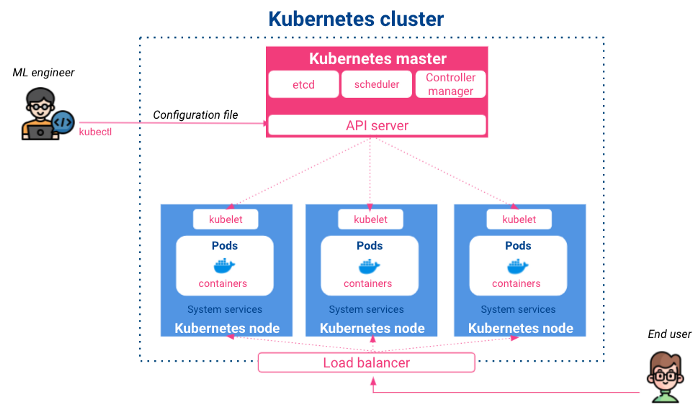
Maestro: Se encarga de las configuraciones de entrada, programa las aplicaciones en contenedores en los distintos nodos y supervisa sus estados. El maestro se compone de:
Nodos: Son los nodos de ejecución en los que viven los contenedores desplegados. Sus componentes principales son:
Es la mejor opción cuando una aplicación tiene varios servicios que se comunican entre sí, ya que garantiza que cada servicio tenga su propio entorno en contenedores con un conjunto de reglas para interactuar con los demás. Además, ofrece la interesante capacidad de escalar una aplicación sin preocuparse de gestionar o sincronizar nuevos servicios y de equilibrar los recursos entre diferentes máquinas.
Desde una perspectiva de alto nivel, como científicos data o ingenieros ML, interactuaremos con Kubernetes a través de su API de servidor utilizando comandos CLI o archivos de configuración YAML para desplegar y exponer aplicaciones u obtener los estados de nuestros recursos.
Prerrequisitos prácticos
Para esta práctica, utilizaremos GCP como proveedor de cloud. En primer lugar, necesitamos :
1. Crear los elementos infraestructurales
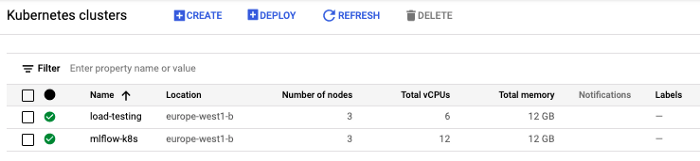
2. Configure la estación de trabajo local
3. Clone el repositorio del proyecto práctico para obtener el código
Despliegue de la instancia Mlflow Tracking
1. Configure el entorno del clúster

2. Seguimiento del despliegue del servidor
Una vez que la imagen es empujada al registro de imágenes podemos desplegarla en el cluster a través de helm utilizando los siguientes comandos.
helm repo add mlflow-tracking https://artefactory-global.github.io/mlflow-tracking-server/helm install mlf-ts mlflow-tracking/mlflow-tracking-server --set env.mlflowArtifactPath=$ --set env.mlflowDBAddr=mlf-db-postgresql --set env.mlflowUser=postgres --set env.mlflowPass=mlflow --set env.mlflowDBName=mlflow_db --set env.mlflowDBPort=5432 --set service.type=LoadBalancer --set image.repository=$/mlflow-tracking-server --set image.tag=v1
Ahora, Mlflow debería estar en funcionamiento y la interfaz de usuario debería ser accesible a través de la IP del equilibrador de carga. Podemos comprobar la IP asignada utilizando kubectl obtener servicios.AAdemás, podemos depurar el despliegue accediendo a los registros vía kubectl describe pods.
Hasta ahora, nuestra arquitectura actual tiene el siguiente aspecto:
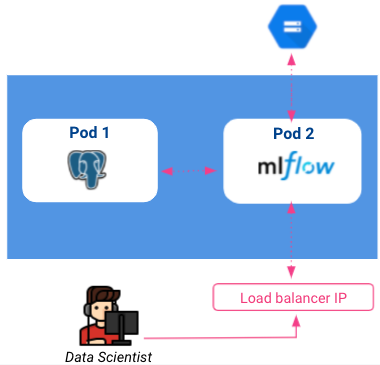
Tenga en cuenta que los equilibradores de carga son accesibles a cualquier persona en Internet, por lo que es esencial pensar en asegurar nuestra instancia de seguimiento añadiendo una capa de autenticación. Esto podría hacerse con el proxy consciente de la identidad en GCP, pero no se abordará en este artículo.
3. Creación de modelos básicos
Ahora que nuestra infraestructura y nuestra instancia de Mlflow están listas, podemos intentar ejecutar un modelo ML sencillo y guardarlo en el registro de modelos para su uso posterior.
Utilizaremos el conjunto data de calidad del vino, compuesto por unas 4900 muestras y 11 características que reflejan las características del vino. La etiqueta oscila entre 3 y 9 y podría considerarse como una calificación.
Se trata de un ejemplo clásico, en el que entrenamos un modelo de regresión Xgboost y lo almacenamos junto con sus parámetros y métricas. El código completo puede encontrarse en cuaderno.
Se habrá dado cuenta de que la integración de Mlflow es sencilla y podría resumirse en el siguiente fragmento de código que invoca a mlflow.start_run(), mlflow.log_param(), mlflow.log_metric() y mlflow.xgboost.log_model()para crear respectivamente un nuevo experimento, almacenar los parámetros de entrenamiento, las métricas de evaluación y el propio modelo entrenado.
Al ejecutar el cuaderno proporcionado, se añadirá una nueva fila en la interfaz de la instancia de seguimiento que corresponderá al nuevo experimento.
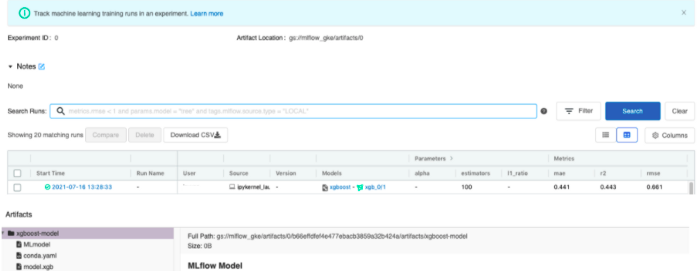
Por último, suponiendo que estemos satisfechos con el rendimiento del modelo, podemos cargarlo desde la instancia de seguimiento y utilizarlo para la inferencia en python. Esto podría hacerse también con el cuaderno compartido anteriormente. Observe que en este ejemplo, cargamos el modelo utilizando el ID de ejecución, pero tenga en cuenta que Mlflow ofrece también otras formas interesantes de identificar modelos por etiquetas, versiones o etapas. Para más detalles, consulte la documentación del registro de modelos aquí.
Conclusión
A lo largo de este artículo, hemos conseguido desplegar la instancia de seguimiento de Mlflow para gestionar nuestros experimentos científicos data y hemos realizado un ejemplo rápido que muestra cómo registrar un modelo y guardarlo para futuras inferencias en python. En el próximo artículo de esta serie, aprenderemos a servir este modelo como una API. Esto tiene una gran importancia, ya que facilita la interacción con el modelo y su integración en un producto o una aplicación. Además, hacerlo sobre Kubernetes garantiza que siga siendo fácilmente escalable y capaz de manejar diferentes niveles de carga.
