

Auteur


MLflow est un outil couramment utilisé pour le suivi des expériences d'apprentissage automatique, le versionnage des modèles et le service. Dans notre premier article de la série “Serving ML models at scale”, nous expliquons comment déployer l'instance de suivi sur Kubernetes et l'utiliser pour enregistrer les expériences et stocker les modèles.
Partie 1 - Comment déployer une instance de suivi Mlflow sur Kubernetes ?
Introduction
Mlflow est un outil largement utilisé dans la communauté data science/ML pour suivre les expériences et gérer les modèles d'apprentissage automatique à différents stades. Grâce à lui, nous pouvons stocker des métriques, des modèles et des artefacts pour comparer facilement les performances des modèles et gérer leurs cycles de vie. En outre, Mlflow fournit un module pour servir les modèles en tant que point d'extrémité d'API, ce qui facilite leur intégration dans n'importe quel produit ou application web.
Cela dit, l'utilisation de l'apprentissage automatique dans les produits en ligne est cool, mais en fonction de la taille du modèle, de sa nature (ML, deep learning,... ) et de la charge (demandes des utilisateurs), il pourrait être difficile de dimensionner les ressources nécessaires et de garantir un temps de réponse raisonnable. Par conséquent, l'utilisation d'une infrastructure évolutive telle que les clusters Kubernetes est essentielle pour maintenir la disponibilité et la performance du service dans la phase d'inférence.
Dans ce contexte, nous publions une série de trois articles dans lesquels nous répondons aux questions suivantes :
Commençons donc ce premier article par une présentation de Kubernetes et de ses composants et passons par le déploiement d'une instance de suivi vers des modèles de logs.
Vue d'ensemble de Kubernetes
Kubernetes est un projet open-source lancé par Google en 2014. Il s'agit d'un système de contrôle et d'orchestration de conteneurs qui permet le déploiement, la mise à l'échelle et la planification automatiques d'applications. Son architecture est la suivante :
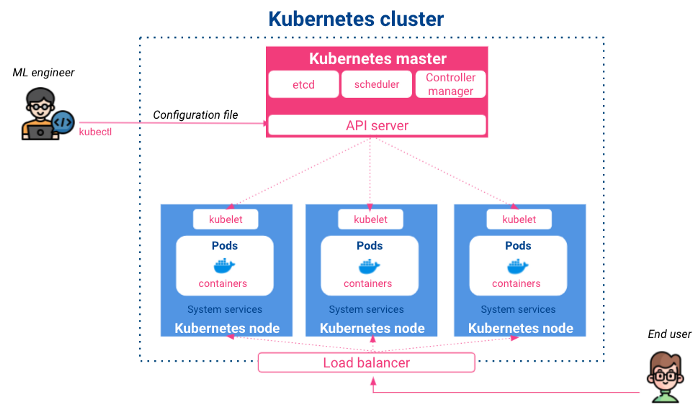
Maître: Il gère les configurations d'entrée, planifie les applications conteneurisées sur les différents nœuds et surveille leurs états. Le maître est composé de :
Nœuds : ce sont les nœuds d'exécution dans lesquels vivent les conteneurs déployés. Leurs principaux composants sont les suivants
C'est le choix idéal lorsqu'une application comporte plusieurs services qui communiquent entre eux, car il garantit que chaque service dispose de son propre environnement conteneurisé avec un ensemble de règles pour interagir avec les autres. En outre, il offre la possibilité intéressante de faire évoluer une application sans se soucier de la gestion ou de la synchronisation de nouveaux services et d'équilibrer les ressources entre différentes machines.
D'un point de vue de haut niveau, en tant que scientifiques data ou ingénieurs ML, nous interagirons avec Kubernetes via son API serveur en utilisant des commandes CLI ou des fichiers de configuration YAML, soit pour déployer et exposer des applications, soit pour obtenir les états de nos ressources.
Pré-requis pratiques
Pour ce travail pratique, nous utiliserons GCP comme fournisseur cloud. Tout d'abord, nous devons :
1. Créer les éléments d'infrastructure
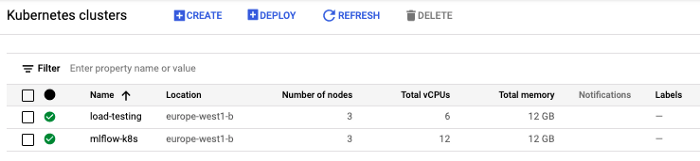
2. Configurez le poste de travail local
3. Clonez le dépôt du projet hands-on pour obtenir le code.
Déploiement de l'instance de suivi Mlflow
1. Configurez l'environnement du cluster

2. Suivi du déploiement du serveur
Une fois l'image poussée dans le registre d'images, nous pouvons la déployer sur le cluster via helm en utilisant les commandes ci-dessous.
helm repo add mlflow-tracking https://artefactory-global.github.io/mlflow-tracking-server/helm install mlf-ts mlflow-tracking/mlflow-tracking-server --set env.mlflowArtifactPath=$ --set env.mlflowDBAddr=mlf-db-postgresql --set env.mlflowUser=postgres --set env.mlflowPass=mlflow --set env.mlflowDBName=mlflow_db --set env.mlflowDBPort=5432 --set service.type=LoadBalancer --set image.repository=$/mlflow-tracking-server --set image.tag=v1
Maintenant, Mlflow devrait être opérationnel et l'interface utilisateur devrait être accessible via l'IP de l'équilibreur de charge. Nous pouvons vérifier l'IP assignée en utilisant kubectl get services.ANous pouvons également déboguer le déploiement en accédant aux journaux. via kubectl describe pods.
Jusqu'à présent, notre architecture actuelle ressemble à ce qui suit :
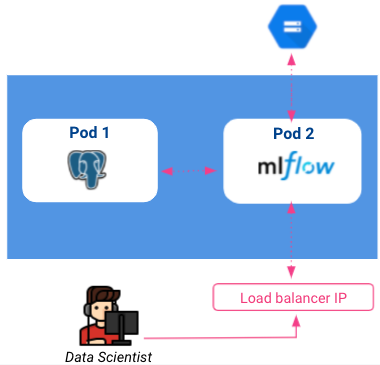
Veuillez noter que les équilibreurs de charge sont accessibles à n'importe qui sur internet, il est donc essentiel de penser à sécuriser notre instance de suivi en ajoutant une couche d'authentification. Cela peut être fait avec l'option proxy tenant compte de l'identité sur GCP mais ne sera pas abordé dans cet article.
3. Création d'un modèle de base
Maintenant que notre infrastructure et notre instance Mlflow sont prêtes, nous pouvons essayer d'exécuter un modèle ML simple et l'enregistrer dans le registre des modèles pour une utilisation ultérieure.
Nous utiliserons l'ensemble dataset sur la qualité du vin, qui est composé d'environ 4900 échantillons et de 11 caractéristiques reflétant les caractéristiques du vin. Les étiquettes vont de 3 à 9 et peuvent être considérées comme des notes.
Il s'agit d'un exemple classique, dans lequel nous formons un modèle de régression Xgboost et le stockons avec ses paramètres et métriques. Le code complet peut être trouvé dans ce document carnet de notes.
Vous avez peut-être remarqué que l'intégration de Mlflow est simple et qu'elle peut être résumée dans l'extrait de code ci-dessous qui invoque mlflow.start_run(), mlflow.log_param(), mlflow.log_metric() et mlflow.xgboost.log_model()pour respectivement créer une nouvelle expérience, stocker les paramètres d'entraînement, les mesures d'évaluation et le modèle entraîné lui-même.
En exécutant le carnet fourni, une nouvelle ligne sera ajoutée dans l'interface de l'instance de suivi qui correspond à la nouvelle expérience.
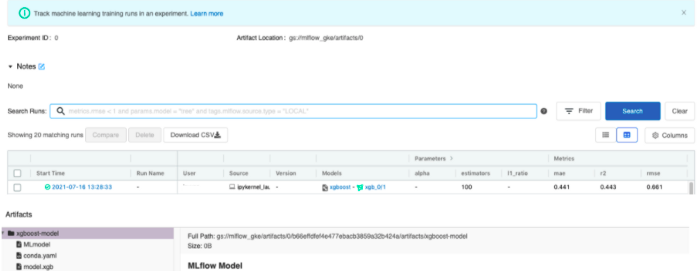
Enfin, en supposant que nous soyons satisfaits des performances du modèle, nous pouvons le charger à partir de l'instance de suivi et l'utiliser pour l'inférence en Python. Ceci pourrait être fait également avec le notebook partagé précédemment. Notez que dans cet exemple, nous avons chargé le modèle en utilisant le run ID mais gardez à l'esprit que Mlflow offre également d'autres façons intéressantes d'identifier les modèles par des tags, des versions, ou des étapes. Pour plus de détails, veuillez vous référer à la documentation du registre des modèles. ici.
Pour conclure
Tout au long de cet article, nous avons réussi à déployer une instance de suivi Mlflow pour gérer nos expériences scientifiques data et nous avons passé en revue un exemple rapide montrant comment enregistrer un modèle et le sauvegarder pour une inférence future sur python. Dans le prochain article de cette série, nous apprendrons comment servir ce modèle en tant qu'API. Cela a une grande importance car cela facilite l'interaction avec le modèle et son intégration dans un produit ou une application. De plus, le fait de le faire sur Kubernetes garantit qu'il reste facilement évolutif et capable de gérer différents niveaux de charge.
