

Autor


MLflow ist ein häufig verwendetes Tool für die Verfolgung von Experimenten zum maschinellen Lernen, die Versionierung von Modellen und das Serving. In unserem ersten Artikel der Serie “ML-Modelle in großem Umfang bereitstellen” erklären wir, wie Sie die Tracking-Instanz auf Kubernetes bereitstellen und sie zum Protokollieren von Experimenten und Speichern von Modellen verwenden.
Teil 1 - Wie stelle ich eine Mlflow-Verfolgungsinstanz auf Kubernetes bereit?
Einführung
Mlflow ist ein in der data Science/ML-Community weit verbreitetes Tool zur Verfolgung von Experimenten und zur Verwaltung von Modellen für maschinelles Lernen in verschiedenen Phasen. Damit können wir Metriken, Modelle und Artefakte speichern, um die Leistung von Modellen einfach zu vergleichen und ihre Lebenszyklen zu verwalten. Außerdem bietet Mlflow ein Modul, mit dem Modelle als API-Endpunkt bereitgestellt werden können, was die Integration in beliebige Produkte oder Webanwendungen erleichtert.
Der Einsatz von maschinellem Lernen in Online-Produkten ist zwar cool, aber je nach Modellgröße, Art (ML, Deep Learning,...) und Last (Nutzeranfragen) kann es eine Herausforderung sein, die benötigten Ressourcen zu dimensionieren und eine angemessene Antwortzeit zu garantieren. Daher ist die Verwendung einer skalierbaren Infrastruktur wie Kubernetes-Cluster der Schlüssel zur Aufrechterhaltung der Serviceverfügbarkeit und Leistung in der Inferenzphase.
In diesem Zusammenhang veröffentlichen wir eine dreiteilige Serie, in der wir die folgenden Fragen beantworten:
Beginnen wir also diesen ersten Artikel mit einer Einführung in Kubernetes und seine Komponenten und gehen wir die Bereitstellung einer Tracking-Instanz für Protokollmodelle durch.
Überblick über Kubernetes
Kubernetes ist ein Open-Source-Projekt, das von Google im Jahr 2014 veröffentlicht wurde. Es handelt sich um ein Container-Kontroll- und Orchestrierungssystem, das die automatische Bereitstellung, Skalierung und Planung von Anwendungen ermöglicht. Es hat die folgende Architektur:
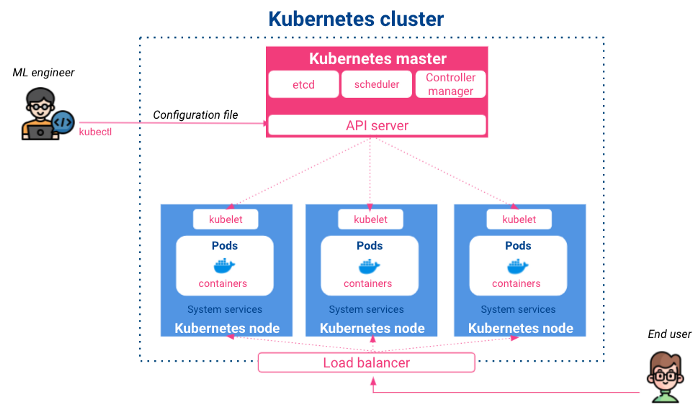
Meister: Er verwaltet Eingabekonfigurationen, plant containerisierte Anwendungen auf den verschiedenen Knoten und überwacht deren Status. Der Master besteht aus:
Knotenpunkte: Sie sind die Ausführungsknoten, in denen sich die bereitgestellten Container befinden. Ihre Hauptkomponenten sind:
Es ist die erste Wahl, wenn eine Anwendung aus mehreren Diensten besteht, die miteinander kommunizieren, denn es stellt sicher, dass jeder Dienst seine eigene Container-Umgebung mit einer Reihe von Regeln für die Interaktion mit anderen hat. Außerdem bietet es die interessante Möglichkeit, eine Anwendung zu skalieren, ohne sich um die Verwaltung oder Synchronisierung neuer Dienste kümmern zu müssen, und Ressourcen zwischen verschiedenen Rechnern auszugleichen.
Als data-Wissenschaftler oder ML-Ingenieure werden wir mit Kubernetes über die Server-API interagieren, indem wir CLI-Befehle oder YAML-Konfigurationsdateien verwenden, um Anwendungen bereitzustellen und zu veröffentlichen oder den Status unserer Ressourcen abzurufen.
Praktische Vorraussetzungen
Für diese praktische Übung werden wir GCP als cloud-Anbieter verwenden. Zunächst müssen wir :
1. Schaffen Sie die infrastrukturellen Elemente
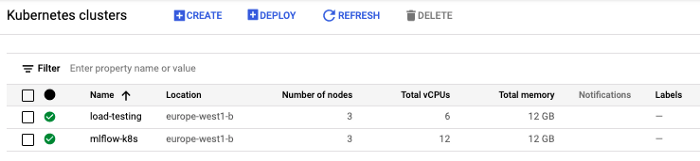
2. Konfigurieren Sie die lokale Workstation
3. Klonen Sie das Hands-on-Projekt-Repository, um den Code zu erhalten
Bereitstellung der Mlflow Tracking-Instanz
1. Einrichten der Cluster-Umgebung

2. Verfolgung des Servereinsatzes
Sobald das Image in die Image-Registry übertragen wurde, können wir es mit den folgenden Befehlen über helm auf dem Cluster verteilen.
helm repo hinzufügen mlflow-tracking https://artefactory-global.github.io/mlflow-tracking-server/helm install mlf-ts mlflow-tracking/mlflow-tracking-server --setzen env.mlflowArtifactPath=$ --set env.mlflowDBAddr=mlf-db-postgresql --set env.mlflowUser=postgres --set env.mlflowPass=mlflow -setzen env.mlflowDBName=mlflow_db --set env.mlflowDBPort=5432 --set service.type=LoadBalancer --set image.repository=$/mlflow-tracking-server --set image.tag=v1
Jetzt sollte Mlflow funktionieren und die Benutzeroberfläche sollte über die IP des Load Balancers zugänglich sein. Wir können die zugewiesene IP überprüfen mit kubectl get Dienste.AAußerdem können wir die Bereitstellung debuggen, indem wir auf die Protokolle zugreifen über kubectl beschreibt Pods.
Bislang sieht unsere derzeitige Architektur wie folgt aus:
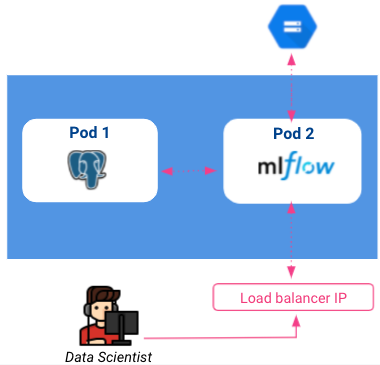
Bitte beachten Sie, dass Load Balancer für jeden im Internet zugänglich sind. Daher ist es wichtig, dass wir unsere Tracking-Instanz durch eine Authentifizierungsschicht absichern. Dies könnte mit dem identitätsbewusster Proxy auf GCP, wird aber in diesem Artikel nicht behandelt.
3. Grundlegende Modellerstellung
Nun, da unsere Infrastruktur und die Mlflow-Instanz bereit sind, können wir versuchen, ein einfaches ML-Modell auszuführen und es zur späteren Verwendung in der Modellregistrierung zu speichern.
Wir werden das Weinqualitätsset data verwenden, das aus etwa 4900 Proben und 11 Merkmalen besteht, die die Eigenschaften des Weins widerspiegeln. Das Etikett reicht von 3 bis 9 und kann als Bewertung angesehen werden.
Dies ist ein klassisches Beispiel, in dem wir ein Xgboost-Regressionsmodell trainieren und es zusammen mit seinen Parametern und Metriken speichern. Den vollständigen Code finden Sie in diesem Notizbuch.
Sie haben vielleicht schon bemerkt, dass die Integration von Mlflow sehr einfach ist und in dem folgenden Codeschnipsel zusammengefasst werden kann, der Folgendes aufruft mlflow.start_run(), mlflow.log_param(), mlflow.log_metric() und mlflow.xgboost.log_model()um jeweils ein neues Experiment zu erstellen, die Trainingsparameter, die Bewertungsmetriken und das trainierte Modell selbst zu speichern.
Wenn Sie das mitgelieferte Notizbuch ausführen, wird eine neue Zeile in der Tracking-Instanz-Schnittstelle hinzugefügt, die dem neuen Experiment entspricht.
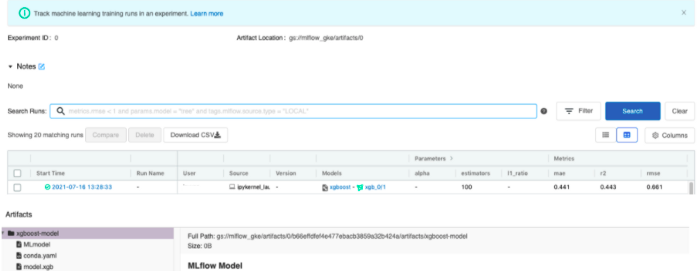
Wenn wir schließlich mit der Leistung des Modells zufrieden sind, können wir es aus der Tracking-Instanz laden und für die Inferenz in Python verwenden. Dies könnte auch mit dem zuvor geteilten Notebook geschehen. Beachten Sie, dass wir in diesem Beispiel das Modell über die Lauf-ID geladen haben. Beachten Sie jedoch, dass Mlflow auch andere interessante Möglichkeiten bietet, Modelle über Tags, Versionen oder Phasen zu identifizieren. Weitere Einzelheiten finden Sie in der Dokumentation zur Modellregistrierung Hier.
Fazit
In diesem Artikel haben wir es geschafft, eine Mlflow-Tracking-Instanz für unsere data-Wissenschaftsexperimente einzurichten, und wir haben ein kurzes Beispiel durchgespielt, das zeigt, wie man ein Modell protokolliert und es für zukünftige Inferenzen in Python speichert. Im nächsten Artikel dieser Serie werden wir lernen, wie wir dieses Modell als API bereitstellen können. Dies ist von großer Bedeutung, da es die Interaktion mit dem Modell und seine Integration in ein Produkt oder eine Anwendung erleichtert. Außerdem sorgt die Ausführung auf Kubernetes dafür, dass es leicht skalierbar bleibt und verschiedene Laststufen bewältigen kann.
