

作者


MLflow 是机器学习实验跟踪、模型版本管理和服务的常用工具。在 “大规模服务 ML 模型 ”系列的第一篇文章中,我们介绍了如何在 Kubernetes 上部署跟踪实例,并用它来记录实验和存储模型。.
第 1 部分 - 如何在 Kubernetes 上部署 Mlflow 跟踪实例?
导言
Mlflow 是 data 科学/ML 社区广泛使用的工具,用于在不同阶段跟踪实验和管理机器学习模型。利用它,我们可以存储指标、模型和工件,从而轻松比较模型的性能并处理其生命周期。此外,Mlflow 还提供了一个模块,可将模型作为 API 端点提供,从而方便将其集成到任何产品或网络应用程序中。.
也就是说,在在线产品中使用机器学习很酷,但根据模型的大小、性质(ML、深度学习......)和负载(用户请求),对所需资源进行维度调整并保证合理的响应时间可能具有挑战性。因此,使用 Kubernetes 集群等可扩展基础设施是在推理阶段保持服务可用性和性能的关键。.
为此,我们将发表三篇系列文章,回答以下问题:
因此,让我们从第一篇文章开始,介绍 Kubernetes 及其组件,并通过日志模型部署跟踪实例。.
Kubernetes 概述
Kubernetes 是谷歌在 2014 年发布的一个开源项目。它是一个容器控制和编排系统,可实现应用程序的自动部署、扩展和调度。其架构如下:
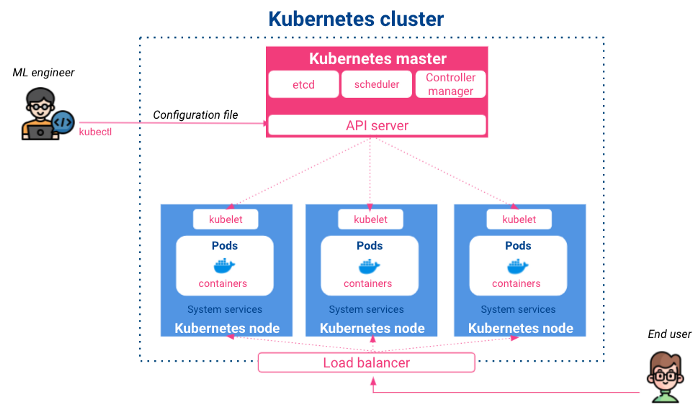
主人:它处理输入配置,调度不同节点上的容器化应用程序,并监控它们的状态。主节点由以下部分组成
节点: 它们是已部署容器所在的执行节点。它们的主要组成部分是
当应用程序有多个服务相互通信时,它是首选,因为它能确保每个服务都有自己的容器化环境,并有一套与其他服务交互的规则。此外,它还提供了一种有趣的功能,即可以扩展应用程序,而不必担心管理或同步新服务以及平衡不同机器之间的资源。.
从高层次的角度来看,作为 data 科学家或 ML 工程师,我们将通过 Kubernetes 的服务器 API,使用 CLI 命令或 YAML 配置文件与 Kubernetes 进行交互,以部署和公开应用程序或获取资源状态。.
实践前要求
在本次实践中,我们将使用 GCP 作为 cloud 提供商。首先,我们需要.NET Framework:
1.创建基础设施要素
2.配置本地工作站
3.克隆实践项目仓库以获取代码
Mlflow 跟踪实例部署
1.设置群集环境

2.跟踪服务器部署情况
将镜像推送到镜像注册表后,我们就可以使用以下命令通过 helm 将其部署到群集上。.
helm repo 添加 mlflow-tracking https://artefactory-global.github.io/mlflow-tracking-server/helm install mlf-ts mlflow-tracking/mlflow-tracking-server --set env.mlflowArtifactPath=$ --set env.mlflowDBAddr=mlf-db-postgresql --设置 env.mlflowUser=postgres --设置 env.mlflowPass=mlflow --设置 env.mlflowDBName=mlflow_db --set env.mlflowDBPort=5432 --设置 service.type=LoadBalancer --设置 image.repository=$/mlflow-tracking-server --set image.tag=v1
现在,Mlflow 应已启动并运行,用户界面应可通过负载平衡器 IP 访问。我们可以使用 kubectl get services.A此外,我们还可以通过访问日志来调试部署 经由 kubectl describe pods.
到目前为止,我们目前的架构如下:
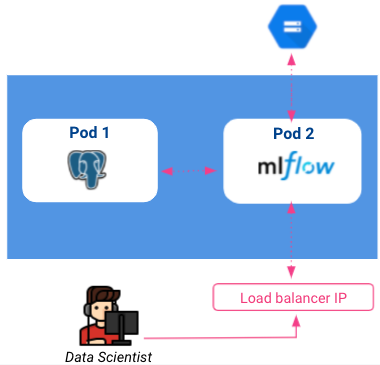
请注意,互联网上的任何人都可以访问负载平衡器,因此必须考虑通过添加验证层来保护我们的跟踪实例。这可以通过 身份识别代理 但本文不涉及。.
3.创建基本模型
现在,我们的基础架构和 Mlflow 实例已经准备就绪,我们可以尝试运行一个简单的 ML 模型,并将其保存在模型注册表中,以供以后使用。.
我们将使用葡萄酒质量 dataset,它由约 4900 个样本和 11 个反映葡萄酒特征的特征组成。标签范围从 3 到 9,可视为评级。.
这是一个经典示例,我们在其中训练了一个 Xgboost 回归模型,并将其与参数和指标一起存储。完整代码如下 笔记本.
您可能已经注意到,Mlflow 的集成非常简单,可以用下面的代码片段来概括,即调用 mlflow.start_run()、mlflow.log_param()、mlflow.log_metric() 和 mlflow.xgboost.log_model()分别用于创建新实验、存储训练参数、评估指标和训练模型本身。.
运行所提供的笔记本后,跟踪实例界面中将新增一行,与新实验相对应。.
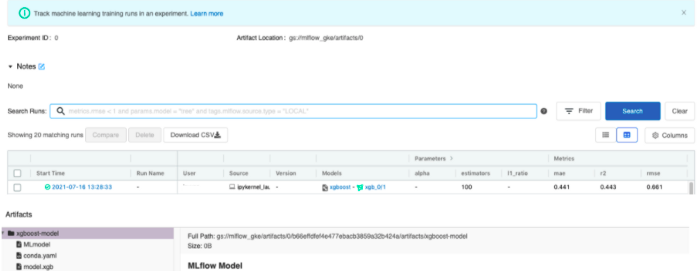
最后,如果我们对模型的性能感到满意,就可以从跟踪实例中加载模型,并在 python 中使用它进行推理。这也可以通过之前共享的笔记本来实现。请注意,在本例中,我们使用运行 ID 加载了模型,但请记住,Mlflow 还提供了其他有趣的方法,可以通过标签、版本或阶段来识别模型。更多详情请参考模型注册文档 这里.
结论
在这篇文章中,我们设法部署了 Mlflow 跟踪实例来处理我们的 data 科学实验,并通过一个快速示例演示了如何记录模型并将其保存起来,以便将来在 python 上进行推理。在本系列的下一篇文章中,我们将学习如何将此模型作为 API 提供。这一点非常重要,因为它有助于与模型进行交互并将其集成到产品或应用程序中。此外,在 Kubernetes 上运行可确保模型易于扩展,并能处理不同的负载水平。.

