

Auteur


MLflow is een veelgebruikte tool voor het volgen van machine-leerexperimenten, het versiebeheer van modellen en het serveren ervan. In ons eerste artikel van de serie “ML-modellen op schaal serveren”, leggen we uit hoe u de traceerinstantie op Kubernetes kunt implementeren en gebruiken om experimenten te loggen en modellen op te slaan.
Deel 1 - Hoe implementeert u Mlflow tracking instance op Kubernetes?
Inleiding
Mlflow is een veelgebruikt hulpmiddel in de data wetenschap/ML-gemeenschap om experimenten bij te houden en modellen voor machinaal leren in verschillende stadia te beheren. Met behulp hiervan kunnen we metriek, modellen en artefacten opslaan om de prestaties van modellen gemakkelijk te vergelijken en hun levenscycli te beheren. Daarnaast biedt Mlflow een module om modellen als API-eindpunt aan te bieden, wat de integratie met elk product of webapp vergemakkelijkt.
Dat gezegd hebbende, het gebruik van machine learning in online producten is cool, maar afhankelijk van de grootte van het model, de aard (ML, deep learning, ... ) en de belasting (aanvragen van gebruikers) kan het een uitdaging zijn om de benodigde bronnen te dimensioneren en een redelijke responstijd te garanderen. Daarom is het gebruik van een schaalbare infrastructuur zoals Kubernetes-clusters essentieel om de beschikbaarheid en prestaties van de service in de inferentiefase te handhaven.
In deze context publiceren we een serie van drie artikelen waarin we de volgende vragen beantwoorden:
Laten we dit eerste artikel dus beginnen met een introductie van Kubernetes en de componenten ervan, en de implementatie van een volginstantie naar logboekmodellen doorlopen.
Overzicht op Kubernetes
Kubernetes is een open-source project dat in 2014 door Google werd uitgebracht. Het is een containerbesturings- en orkestratiesysteem waarmee applicaties automatisch kunnen worden ingezet, geschaald en gepland. Het heeft de volgende architectuur:
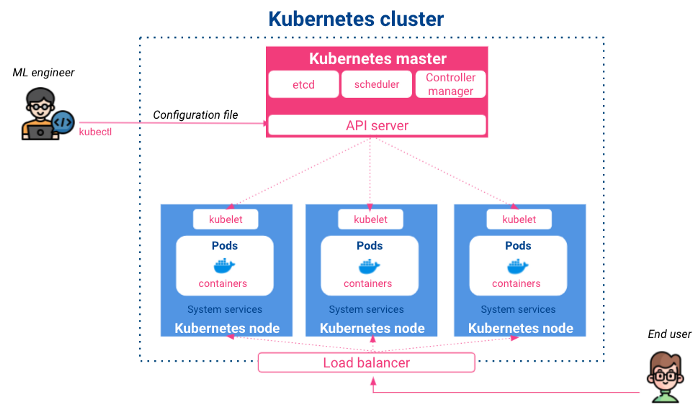
Master: Het handelt invoerconfiguraties af, plant gecontaineriseerde apps op de verschillende nodes en bewaakt hun status. De master bestaat uit:
Knooppunten: Dit zijn de uitvoerende knooppunten waarin de ingezette containers leven. Hun belangrijkste onderdelen zijn:
Het is de keuze bij uitstek wanneer een applicatie meerdere services heeft die met elkaar communiceren, omdat het ervoor zorgt dat elke service zijn eigen gecontaineriseerde omgeving heeft met een set regels om met anderen te communiceren. Daarnaast biedt het de interessante mogelijkheid om een applicatie op te schalen zonder dat u zich zorgen hoeft te maken over het beheren of synchroniseren van nieuwe services en om resources tussen verschillende machines in balans te brengen.
Op hoog niveau zullen wij, als data wetenschappers of ML-ingenieurs, communiceren met Kubernetes via de server-API met behulp van CLI-commando's of YAML-configuratiebestanden om apps te implementeren en bloot te stellen, of om onze resources-status op te vragen.
Praktische vereisten
Voor deze hands-on zullen we GCP gebruiken als een cloud provider. Eerst moeten we :
1. Creëer de infrastructurele elementen
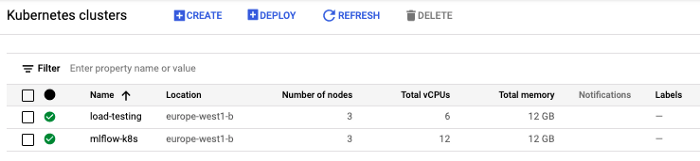
2. Configureer het lokale werkstation
3. Kloon de hands-on projectrepository om de code te krijgen
Uitrol van Mlflow Tracking instantie
1. De clusteromgeving instellen

2. De uitrol van de server volgen
Zodra het image naar het image-register is gepushed, kunnen we het via helm op het cluster implementeren met behulp van de onderstaande commando's.
roer repo toevoegen mlflow-tracking https://artefactory-global.github.io/mlflow-tracking-server/roer mlf-ts mlflow-tracking/mlflow-tracking-server installeren --set env.mlflowArtifactPath=$ -set env.mlflowDBAddr=mlf-db-postgresql -set env.mlflowUser=postgres -set env.mlflowPass=mlflow -set env.mlflowDBName=mlflow_db -set env.mlflowDBPort=5432 -set service.type=LoadBalancer -set image.repository=$/mlflow-tracking-server --set image.tag=v1
Nu zou Mlflow moeten werken en de UI zou toegankelijk moeten zijn via het loadbalancer IP. We kunnen het toegewezen IP controleren met kubectl get diensten.AOok kunnen we de implementatie debuggen door toegang te krijgen tot de logboeken via kubectl pods beschrijven.
Tot nu toe ziet onze huidige architectuur er als volgt uit:
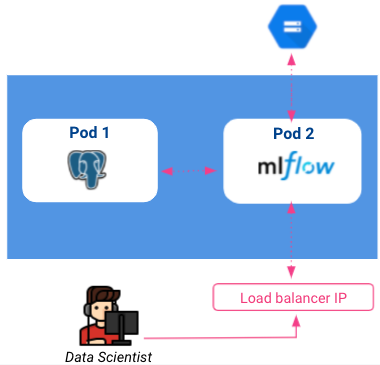
Houd er rekening mee dat loadbalancers toegankelijk zijn voor iedereen op het internet, dus het is essentieel om na te denken over het beveiligen van onze volginstantie door een authenticatielaag toe te voegen. Dit kan gedaan worden met de identiteitsbewuste proxy op GCP, maar wordt niet behandeld in dit artikel.
3. Basismodel maken
Nu onze infrastructuur en Mlflow-instantie klaar zijn, kunnen we proberen om een eenvoudig ML-model uit te voeren en dit in het modelregister op te slaan voor later gebruik.
We zullen de dataset voor wijnkwaliteit gebruiken, die bestaat uit ongeveer 4900 monsters en 11 kenmerken die wijnkenmerken weergeven. Het label loopt van 3 tot 9 en kan worden gezien als een beoordeling.
Dit is een klassiek voorbeeld, waarin we een Xgboost regressiemodel trainen en samen met de parameters en metriek opslaan. De volledige code vindt u in deze notebook.
U hebt misschien gemerkt dat de integratie met Mlflow eenvoudig is en kan worden samengevat in het onderstaande codefragment dat het volgende aanroept mlflow.start_run(), mlflow.log_param(), mlflow.log_metric() en mlflow.xgboost.log_model()om respectievelijk een nieuw experiment aan te maken, de trainingsparameters, de evaluatiemetriek en het getrainde model zelf op te slaan.
Door het meegeleverde notitieboek uit te voeren, wordt er een nieuwe rij toegevoegd aan de tracking instance interface die overeenkomt met het nieuwe experiment.
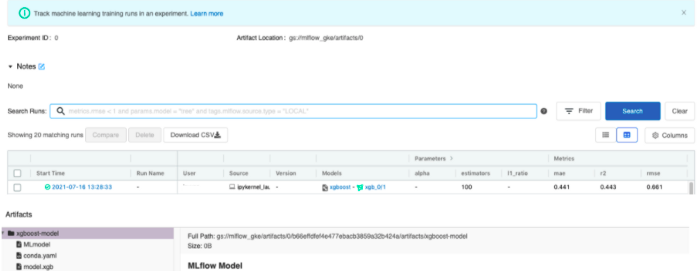
Als we ten slotte tevreden zijn met de prestaties van het model, kunnen we het laden vanuit de volginstantie en gebruiken voor inferentie in python. Dit kan ook gedaan worden met het eerder gedeelde notebook. Merk op dat we in dit voorbeeld het model hebben geladen met behulp van de run-ID, maar vergeet niet dat Mlflow ook andere interessante manieren biedt om modellen te identificeren aan de hand van tags, versies of stadia. Raadpleeg voor meer details de documentatie over het modelregister hier.
Conclusie
In dit artikel zijn we erin geslaagd om Mlflow tracking instance te implementeren om onze data wetenschapsexperimenten af te handelen en hebben we een snel voorbeeld gegeven om te laten zien hoe we een model kunnen loggen en opslaan voor toekomstige inferentie op python. In het volgende artikel van deze serie zullen we leren hoe we dit model als API kunnen aanbieden. Dit is van groot belang omdat het de interactie met het model en de integratie ervan in een product of applicatie vergemakkelijkt. Bovendien zorgt Kubernetes ervoor dat het gemakkelijk schaalbaar blijft en verschillende belastingsniveaus aankan.
