


Um algoritmo para gerar eventos raros sintéticos de todos os tipos
Uma aplicação comum do artificial intelligence é atribuir uma probabilidade, ou pontuação, a pessoas ou eventos de interesse. Esse problema de pontuação se aplica a muitas áreas, como detecção de doenças, manutenção preditiva em fábricas, propensão de visitantes on-line a fazer compras ou o risco de perder assinantes. Nessas situações, os eventos de interesse são muito mais numerosos do que o total de data disponível. Esse desequilíbrio torna o treinamento dos modelos de aprendizado de máquina particularmente complexo, pois eles tendem a se concentrar na maioria dos casos e a ignorar ou subestimar os casos raros, o que apresenta vários problemas operacionais se a IA for implantada. Existem alguns algoritmos, mas eles não são adequados para o data categórico e, em geral, não conseguem melhorar a precisão do modelo final.
Para enfrentar esse desafio, Centro de pesquisa do Artefact propôs um novo método de rebalanceamento para o data tabular, levando em conta variáveis numéricas e categóricas. Testado no código aberto data, Como o senhor sabe, essa abordagem mostra melhorias significativas em termos de desempenho, ao mesmo tempo em que mantém a consistência, a plausibilidade e a interpretabilidade do data, um aspecto frequentemente negligenciado pelos métodos existentes. O rebalanceamento do Data exige a criação de exemplos fictícios, que correm o risco de serem implausíveis, como perfis de clientes que não existem. Esse risco tem um impacto direto na adoção do artificial intelligence nos casos em que os analistas precisam validar manualmente os exemplos mais prováveis pré-selecionados pelo modelo. O Artefact resolve esse problema criando apenas data plausível durante o rebalanceamento, facilitando sua adoção pelas empresas.
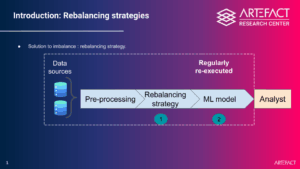
Uma parceria de pesquisa pronta para uso com aplicativos para casos de uso da Societe Generale
Esse trabalho é o resultado de uma parceria tripartite entre a Artefact Research Center, o Laboratório de Probabilidade, Estatística e Modelagem (LPSM) da Universidade de Sorbonne e a Societe Generale. A colaboração permitiu definir um tópico de pesquisa de três anos que estabelece um equilíbrio entre os desafios estatísticos e de TI e os problemas concretos enfrentados pelas equipes de negócios para os quais não há soluções de última geração. De fato, no caso desse aplicativo, vários especialistas em vendas relataram o problema de inconsistência nos perfis bancários gerados pelas abordagens existentes, o que limitou a adoção de uma ferramenta baseada em IA, levantando assim o desafio de manter sugestões plausíveis durante o algoritmo de rebalanceamento.
Por meio dessa parceria, os pesquisadores do Artefact e da Universidade de Sorbonne puderam testar suas abordagens no banco real data, o que validou a precisão estatística do algoritmo proposto. Além disso, um elemento exclusivo para testar o desempenho do método proposto foi a escalonamento até milhões de pontos data para ser processado em um período de tempo razoável, excedendo assim o tamanho dos datasets de código aberto equivalentes. O código é de código aberto e a metodologia é explicada em detalhes no artigo científico, O senhor pode usar a abordagem para outros casos de uso de pontuação, permitindo que o maior número possível de pessoas a utilize.
Etienne GUIBOUT, Diretor de IA do Grupo Societe Generale, explica:
“Essa colaboração dá à Societe Generale acesso a conhecimentos complementares do mundo acadêmico. Ela promove a inovação ao incorporar uma variedade de perspectivas com o objetivo de identificar soluções cada vez mais adaptadas aos nossos problemas. A aceitação em uma conferência de nível A é uma marca de qualidade para as equipes da Societe Generale. Ela demonstra o reconhecimento do impacto do trabalho realizado por colegas e especialistas do setor. A participação em tais eventos nos permite compartilhar nossa pesquisa, permanecendo parte do ecossistema. As equipes de negócios da Societe Generale, especialmente de compliance, estiveram envolvidas no desenvolvimento deste artigo. Sua experiência no setor e seu feedback confirmaram a relevância e a aplicabilidade do conteúdo apresentado. Essa colaboração interdisciplinar garante que o artigo reflita as realidades do mercado e atenda, em primeiro lugar, às nossas necessidades e às de nossos clientes.”
Emmanuel Malherbe, diretor do Artefact Research Center:
“Essa é uma parceria ideal para nosso centro de pesquisa, ilustrando perfeitamente nossa visão de pesquisa aplicada, útil e compartilhada. O aprendizado de máquina é um campo que sempre começa com data e um problema real. Por meio dessa colaboração, conseguimos nos concentrar na questão mal resolvida da pontuação em data tabular desequilibrado, que, no entanto, é um problema recorrente nos negócios e levanta muitas questões estatísticas. A possibilidade de testar e validar a abordagem no data real também foi fundamental para obter um algoritmo rápido, eficiente e preciso.”
Link para o artigo científico e o código do algoritmo:
- Abdoulaye Sakho, Emmanuel Malherbe, Carl-Erik Gauthier e Erwan Scornet.
“Aproveitamento de recursos mistos para superamostragem de desequilíbrio Data: Application to Bank Customers Scoring”.” Em Conferência Europeia Conjunta sobre Aprendizado de Máquina e Descoberta de Conhecimento em Databases (2025) - https://github.com/artefactory/mgs-grf
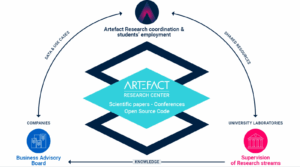
O centro de pesquisa do Artefact como ponte entre a academia e o setor
Somos uma equipe de 20 cientistas pesquisadores que trabalham nas áreas de aprendizado de máquina, ciência da computação e ciência da administração. Dedicamo-nos a aprimorar os modelos de IA, seja tornando-os mais interpretáveis e controláveis ou estudando seu uso nas empresas. Todo o nosso trabalho é de código aberto, com apresentações em conferências internacionais revisadas por pares, publicações científicas, white papers e códigos disponíveis gratuitamente. Trabalhamos em estreita colaboração com professores universitários renomados. Nossa filosofia é fazer a ponte entre o setor e a academia. Nossas áreas de pesquisa são inspiradas em problemas do mundo real encontrados em projetos Artefact com nossos clientes, e estamos continuamente criando parcerias industriais para testar nossas metodologias em casos de uso reais e conjuntos data.
Um exemplo crucial diz respeito à explicabilidade dos modelos estatísticos. A adoção de modelos de aprendizado de máquina é dificultada em muitos casos de uso devido à natureza de “caixa preta” de determinados modelos ou, em outras palavras, à sua falta de transparência e compreensibilidade. Portanto, é necessário propor modelos mais transparentes e, ao mesmo tempo, minimizar a degradação associada ao desempenho preditivo. Por meio das soluções que propõe, o centro de pesquisa está melhorando a adoção da IA, oferecendo as garantias desejadas pelo setor.
