


Un algorithme pour générer des événements rares synthétiques de tous types
Une application courante de artificial intelligence consiste à attribuer une probabilité, ou un score, à des personnes ou à des événements intéressants. Ce problème de notation s'applique à de nombreux domaines, tels que la détection des maladies, la maintenance prédictive dans les usines, la propension des visiteurs en ligne à effectuer des achats ou le risque de perdre des abonnés. Dans ces situations, les événements intéressants sont beaucoup plus nombreux que le total des data disponibles. Ce déséquilibre rend l'apprentissage des modèles d'apprentissage automatique particulièrement complexe, car ils ont tendance à se concentrer sur la majorité des cas et à ignorer ou sous-estimer les cas rares, ce qui pose de multiples problèmes opérationnels en cas de déploiement de l'IA. Des algorithmes existent, mais ils ne sont pas adaptés à la data catégorielle et ne permettent généralement pas d'améliorer la précision du modèle final.
Pour relever ce défi, Le centre de recherche de Artefact a proposé une nouvelle méthode de rééquilibrage pour le tableau data, L'étude a été réalisée en tenant compte des variables numériques et catégorielles. Testé sur le logiciel libre data, Cette approche montre des améliorations significatives en termes de performance, tout en maintenant la cohérence, la plausibilité et l'interprétabilité du data, un aspect souvent négligé par les méthodes existantes. Le rééquilibrage du Data nécessite la création d'exemples fictifs, qui risquent d'être peu plausibles, tels que des profils de clients qui n'existent pas. Ce risque a un impact direct sur l'adoption de artificial intelligence dans les cas où les analystes doivent valider manuellement les exemples les plus probables présélectionnés par le modèle. Artefact résout ce problème en ne créant que des data plausibles lors du rééquilibrage, ce qui facilite son adoption par les entreprises.
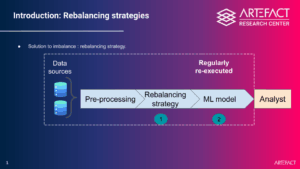
Un partenariat de recherche clé en main avec des applications pour les cas d'utilisation de la Société Générale
Ce travail est le résultat d'un partenariat tripartite entre l'Agence européenne pour la sécurité et la santé au travail (ESA) et la Commission européenne. Artefact Research Center, le Laboratoire de probabilités, statistiques et modélisation (LPSM) de l'Université de la Sorbonne et Société Générale. Cette collaboration a permis de définir un sujet de recherche sur trois ans qui trouve un équilibre entre les défis statistiques et informatiques et les problèmes concrets rencontrés par les équipes commerciales pour lesquels il n'existe pas de solutions à l'état de l'art. En effet, dans le cas de cette application, différents experts commerciaux avaient signalé le problème de l'incohérence des profils bancaires générés par les approches existantes, ce qui limitait leur adoption d'un outil basé sur l'IA. maintenir des suggestions plausibles pendant l'algorithme de rééquilibrage.
Grâce à ce partenariat, les chercheurs de Artefact et de Sorbonne Université ont pu tester leurs approches sur la banque réelle data, ce qui a permis de valider la précision statistique de l'algorithme proposé. En outre, un élément unique dans le test de la performance de la méthode proposée a été le fait que la banque data a été testée sur la base des données de la banque data. mise à l'échelle jusqu'à des millions de points data à traiter dans un délai raisonnable, dépassant ainsi la taille des ensembles datasets équivalents en source ouverte. Le code est libre et la méthodologie est expliquée en détail dans l'article scientifique., Le but est de permettre au plus grand nombre de personnes possible d'utiliser l'approche pour d'autres cas d'utilisation de la notation.
Etienne GUIBOUT, Group Chief AI Officer à la Société Générale, explique :
“Cette collaboration permet à Société Générale d'accéder à des expertises complémentaires issues du monde académique. Elle favorise l'innovation en intégrant une variété de perspectives visant à identifier des solutions toujours plus adaptées à nos problématiques. L'acceptation à une conférence de niveau A est un gage de qualité pour les équipes de Société Générale. Elle témoigne de la reconnaissance de l'impact du travail effectué par des pairs et des experts de l'industrie. Participer à de tels événements nous permet de partager nos recherches, tout en faisant partie de l'écosystème. Les équipes métiers de Société Générale, en particulier la conformité, ont été impliquées dans l'élaboration de cet article. Leur expertise sectorielle et leur retour d'expérience ont permis de confirmer la pertinence et l'applicabilité du contenu présenté. Cette collaboration interdisciplinaire garantit que l'article reflète les réalités du marché et répond avant tout à nos besoins et à ceux de nos clients”.”
Emmanuel Malherbe, directeur du Artefact Research Center :
“Il s'agit d'un partenariat idéal pour notre centre de recherche, qui illustre parfaitement notre vision de la recherche appliquée, utile et partagée. L'apprentissage automatique est un domaine qui commence toujours par data et un problème réel. Grâce à cette collaboration, nous avons pu nous concentrer sur la question mal résolue du scoring sur des tableaux data déséquilibrés, qui est pourtant un problème récurrent en entreprise et qui soulève de nombreuses questions statistiques. Le fait de pouvoir tester et valider l'approche sur des data réels a également été déterminant pour obtenir un algorithme rapide, efficace et précis”.”
Lien vers l'article scientifique et le code de l'algorithme :
- Abdoulaye Sakho, Emmanuel Malherbe, Carl-Erik Gauthier et Erwan Scornet.
“Harnessing Mixed Features for Imbalance Data Oversampling : Application to Bank Customers Scoring”.” En Conférence européenne conjointe sur l'apprentissage automatique et la découverte de connaissances dans les bases de données Data (2025) - https://github.com/artefactory/mgs-grf
Le centre de recherche du Artefact, un pont entre le monde universitaire et l'industrie
Nous sommes une équipe de 20 chercheurs scientifiques travaillant dans les domaines de l'apprentissage automatique, de l'informatique et des sciences de gestion. Nous nous consacrons à l'amélioration des modèles d'IA, que ce soit en les rendant plus interprétables et contrôlables ou en étudiant leur utilisation au sein des entreprises. Tous nos travaux sont en open source, avec des présentations lors de conférences internationales évaluées par les pairs, des publications scientifiques, des livres blancs et du code en libre accès. Nous collaborons étroitement avec des professeurs d'université renommés. Notre philosophie est de combler le fossé entre l'industrie et le monde universitaire. Nos domaines de recherche s'inspirent de problèmes réels rencontrés dans des projets Artefact avec nos clients, et nous construisons continuellement des partenariats industriels pour tester nos méthodologies sur des cas d'utilisation réels et des ensembles data.
Un exemple crucial concerne l'explicabilité des modèles statistiques. L'adoption de modèles d'apprentissage automatique est entravée dans de nombreux cas d'utilisation en raison de la nature de “boîte noire” de certains modèles, ou en d'autres termes, de leur manque de transparence et d'intelligibilité. Il faut donc proposer des modèles plus transparents, tout en minimisant la dégradation de la performance prédictive associée. Par les solutions qu'il propose, le centre de recherche améliore l'adoption de l'IA en apportant les garanties souhaitées par l'industrie.
