


Ein Algorithmus zur Erzeugung synthetischer seltener Ereignisse aller Art
Eine häufige Anwendung von artificial intelligence ist die Zuweisung einer Wahrscheinlichkeit oder eines Scores für Personen oder Ereignisse von Interesse. Dieses Scoring-Problem findet in vielen Bereichen Anwendung, z.B. bei der Erkennung von Krankheiten, der vorausschauenden Wartung in Fabriken, der Neigung von Online-Besuchern, Käufe zu tätigen, oder dem Risiko, Abonnenten zu verlieren. In diesen Situationen ist die Zahl der interessanten Ereignisse im Vergleich zur Gesamtzahl der verfügbaren data weitaus größer. Dieses Ungleichgewicht macht das Training von maschinellen Lernmodellen besonders komplex, da sie dazu neigen, sich auf die Mehrheit der Fälle zu konzentrieren und seltene Fälle zu ignorieren oder zu unterschätzen, was beim Einsatz von KI zahlreiche operative Probleme aufwirft. Es gibt zwar einige Algorithmen, aber sie eignen sich nicht für kategorische data und können die Genauigkeit des endgültigen Modells im Allgemeinen nicht verbessern.
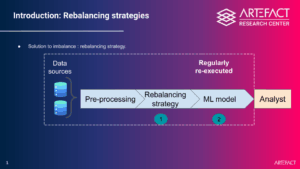
Um diese Herausforderung zu meistern, Das Forschungszentrum von Artefact eine neue Ausgleichsmethode für tabellarische data vorgeschlagen, wobei sowohl numerische als auch kategorische Variablen berücksichtigt werden. Getestet auf Open Source data, Dieser Ansatz zeigt signifikante Verbesserungen in Bezug auf die Leistung, während die Konsistenz, Plausibilität und Interpretierbarkeit der data erhalten bleibt, ein Aspekt, der bei bestehenden Methoden oft übersehen wird. Das Data Rebalancing erfordert die Erstellung von Dummy-Beispielen, bei denen das Risiko besteht, dass sie unplausibel sind, wie z.B. Kundenprofile, die nicht existieren. Dieses Risiko wirkt sich direkt auf die Akzeptanz von artificial intelligence in Fällen aus, in denen Analysten die vom Modell vorausgewählten wahrscheinlichsten Beispiele manuell validieren müssen. Artefact löst dieses Problem, indem es nur plausible data während des Rebalancierens erstellt, was seine Annahme durch die Unternehmen erleichtert.
Eine schlüsselfertige Forschungspartnerschaft mit Anwendungen für Societe Generale-Anwendungsfälle
Diese Arbeit ist das Ergebnis einer dreifachen Partnerschaft zwischen der Artefact Research Center, das Labor für Wahrscheinlichkeit, Statistik und Modellierung der Universität Sorbonne (LPSM) und die Societe Generale. Die Zusammenarbeit ermöglichte es, ein dreijähriges Forschungsthema zu definieren, das ein Gleichgewicht zwischen statistischen und IT-Herausforderungen und den konkreten Problemen von Geschäftsteams herstellt, für die es keine modernen Lösungen gibt. Im Falle dieser Anwendung berichteten verschiedene Vertriebsexperten über das Problem der Inkonsistenz in den Bankprofilen, die von den bestehenden Ansätzen generiert wurden, was die Annahme eines KI-basierten Tools einschränkte und somit die Herausforderung die Beibehaltung plausibler Vorschläge während des Rebalancing-Algorithmus.
Durch diese Partnerschaft konnten die Forscher von Artefact und der Universität Sorbonne ihre Ansätze an der realen Bank data testen, was die statistische Genauigkeit des vorgeschlagenen Algorithmus bestätigte. Ein einzigartiges Element beim Testen der Leistung der vorgeschlagenen Methode war außerdem die Skalierung auf bis zu Millionen von data-Punkten in einer angemessenen Zeitspanne zu verarbeiten und übertrifft damit die Größe entsprechender Open-Source-data-Sets. Der Code ist quelloffen und die Methodik wird in dem wissenschaftlichen Artikel ausführlich erläutert, Damit können so viele Menschen wie möglich den Ansatz für andere Scoring-Anwendungsfälle nutzen.
Etienne GUIBOUT, Group Chief AI Officer bei der Societe Generale, erklärt:
“Diese Zusammenarbeit verschafft Societe Generale Zugang zu ergänzendem Fachwissen aus der akademischen Welt. Sie fördert die Innovation durch die Einbeziehung einer Vielzahl von Perspektiven, die darauf abzielen, Lösungen zu finden, die zunehmend auf unsere Probleme zugeschnitten sind. Die Aufnahme in eine A-Level-Konferenz ist ein Qualitätsmerkmal für die Teams von Societe Generale. Sie zeigt, dass der Einfluss der von Kollegen und Branchenexperten geleisteten Arbeit anerkannt wird. Die Teilnahme an solchen Veranstaltungen ermöglicht es uns, unsere Forschungsergebnisse zu teilen und gleichzeitig Teil des Ökosystems zu bleiben. Die Geschäftsteams der Societe Generale, insbesondere im Bereich Compliance, waren an der Entwicklung dieses Artikels beteiligt. Ihre Branchenkenntnis und ihr Feedback bestätigten die Relevanz und Anwendbarkeit der dargestellten Inhalte. Diese interdisziplinäre Zusammenarbeit gewährleistet, dass der Artikel die Marktrealitäten widerspiegelt und in erster Linie unseren Bedürfnissen und denen unserer Kunden dient.”
Emmanuel Malherbe, Direktor des Artefact Research Center:
“Dies ist eine ideale Partnerschaft für unser Forschungszentrum, die unsere Vision von angewandter, nützlicher und gemeinsamer Forschung perfekt illustriert. Maschinelles Lernen ist ein Bereich, der immer mit data und einem echten Problem beginnt. Durch diese Zusammenarbeit konnten wir uns auf das schlecht gelöste Problem der Auswertung von unausgewogenen tabellarischen data konzentrieren, das jedoch ein immer wiederkehrendes Problem in der Wirtschaft ist und viele statistische Fragen aufwirft. Die Möglichkeit, den Ansatz an echten data zu testen und zu validieren, war ebenfalls der Schlüssel zu einem schnellen, effizienten und genauen Algorithmus.”
Link zum wissenschaftlichen Artikel und zum Code des Algorithmus:
- Abdoulaye Sakho, Emmanuel Malherbe, Carl-Erik Gauthier, und Erwan Scornet.
“Nutzung gemischter Merkmale für Ungleichgewicht Data Oversampling: Anwendung auf das Scoring von Bankkunden”.” Unter Gemeinsame Europäische Konferenz über maschinelles Lernen und Wissensentdeckung in Data-Datenbanken (2025) - https://github.com/artefactory/mgs-grf
Das Forschungszentrum von Artefact als Brücke zwischen Wissenschaft und Industrie
Wir sind ein Team von 20 Wissenschaftlern, die in den Bereichen maschinelles Lernen, Informatik und Managementwissenschaften arbeiten. Wir widmen uns der Verbesserung von KI-Modellen, sei es, indem wir sie besser interpretierbar und kontrollierbar machen, oder indem wir ihren Einsatz in Unternehmen untersuchen. Unsere gesamte Arbeit ist Open Source, mit Präsentationen auf internationalen Konferenzen mit Peer-Review, wissenschaftlichen Veröffentlichungen, Whitepapers und frei verfügbarem Code. Wir arbeiten eng mit renommierten Universitätsprofessoren zusammen. Unsere Philosophie ist es, die Kluft zwischen Industrie und Wissenschaft zu überbrücken. Unsere Forschungsbereiche sind von realen Problemen inspiriert, die in Artefact-Projekten mit unseren Kunden auftreten, und wir bauen kontinuierlich industrielle Partnerschaften auf, um unsere Methoden an realen Anwendungsfällen und data-Sets zu testen.
Ein wichtiges Beispiel ist die Erklärbarkeit von statistischen Modellen. Die Einführung von Modellen des maschinellen Lernens wird in vielen Anwendungsfällen durch die “Blackbox”-Natur bestimmter Modelle behindert, d.h. durch ihre mangelnde Transparenz und Verständlichkeit. Es müssen daher transparentere Modelle vorgeschlagen werden, wobei die damit verbundene Verschlechterung der Vorhersageleistung minimiert werden muss. Durch die von ihm vorgeschlagenen Lösungen verbessert das Forschungszentrum die Akzeptanz von KI, indem es die von der Industrie gewünschten Garantien bietet.
