

Autor


A otimização do sortimento é um processo crítico no varejo que envolve selecionar o mix ideal de produtos para atender à demanda do consumidor e, ao mesmo tempo, levar em conta as diversas restrições logísticas envolvidas. Os varejistas precisam se certificar de que oferecem os produtos certos, nas quantidades certas e no momento certo. Ao aproveitar o data e as percepções do consumidor, os varejistas podem tomar decisões informadas sobre quais itens estocar, como gerenciar o estoque e quais produtos priorizar com base nas preferências do cliente, tendências sazonais e padrões de vendas.
Para as empresas de varejo, a otimização do sortimento é essencial para atingir um equilíbrio entre variedade e eficiência. Oferecer poucas opções pode afastar os clientes, enquanto oferecer muitas pode gerar confusão, excesso de estoque e margens de lucro menores. A otimização do sortimento de produtos ajuda as empresas a aumentar a satisfação do cliente, garantindo a disponibilidade de itens populares e eliminando produtos de baixo desempenho que ocupam um espaço valioso nas prateleiras.
Modelo de escolha A modelagem de escolha é uma maneira eficiente de abordar a otimização do sortimento porque fornece uma estrutura data-driven para entender as preferências dos clientes e prever como eles escolherão entre diferentes produtos. Ao analisar vários fatores, como sensibilidade ao preço, características do produto e fidelidade à marca, a modelagem de escolha ajuda os varejistas a identificar quais produtos têm maior probabilidade de atender à demanda dos clientes.
Em última análise, a modelagem de escolhas permite que os varejistas ofereçam o mix certo de produtos, personalizem sortimentos para segmentos específicos de clientes e também otimizem o espaço nas prateleiras para aumentar a lucratividade ou até mesmo o preço dos itens.
Se o senhor nunca ouviu falar de modelagem de escolha, pode ler nosso artigo que apresenta os principais conceitos com exemplos. Neste artigo, vamos nos concentrar principalmente em como os modelos de escolha discreta podem ser usados para otimizar uma variedade de produtos. Fornecemos exemplos de código com base no escolha-aprendizagem que foi projetada para ajudar os cientistas do data nesses casos de uso.
O código fornecido usa o pacote Python choice-learn e pode ser encontrado em um notebook aqui.
Configurar: Instalação do Python e do Choice-Learn
Neste artigo, fornecemos trechos de código para acompanhar as explicações. O código usa o Escolha-Aprenda que fornece ferramentas eficientes para modelagem de escolhas e várias aplicações, como otimização de sortimento ou preço. A Choice-Learn está disponível por meio do PyPI, e o senhor pode obtê-la simplesmente com
O dataset: recibos de vendas
Usaremos o TaFeng grocery dataset. O senhor pode fazer o download em Kaggle e abra-o em seu ambiente Python com choice-learn:
print(tafeng_df.head())

O dataset consiste em mais de 800.000 compras individuais em uma mercearia chinesa. Para cada compra, são fornecidos vários detalhes, inclusive o item comprado (PRODUCT_ID), o preço pelo qual foi vendido (SALES_PRICE) e a faixa etária do cliente (AGE_GROUP).
O senhor pode observar que muitos itens diferentes são fornecidos e alguns deles raramente são vendidos. Para otimizar a logística, o varejista pode optar por reduzir o número de produtos que oferece. Nesse caso, a meta é identificar o subconjunto ideal de itens a serem vendidos.
Para isso, concentramo-nos nos itens mais vendidos, pois eles têm maior probabilidade de serem comprados novamente e desempenharão um papel crucial na formação de um sortimento mais eficiente e lucrativo. Observe que fazemos isso principalmente para simplificar o exemplo e que todos os itens podem ser mantidos.
tafeng_df = tafeng_df.loc[
tafeng_df.PRODUCT_ID.isin(tafeng_df.PRODUCT_ID.value_counts().index[:20])
].reset_index(drop=Verdadeiro)
tafeng_df = tafeng_df.loc[
tafeng_df.AGE_GROUP.isin([“25-29”, “40-44”, “45-49”, “>65”, “30-34”, “35-39”, “50-54”, “55-59”, “60-64”] )
].reset_index(drop=Verdadeiro)
Vamos também codificar as categorias de idade com um valor quente a cada dez anos:
tafeng_df[“twenties” (vinte anos)”] = tafeng_df.apply(lambda fila: 1 se linha[“AGE_GROUP”] == “25-29” mais 0, axis=1)
tafeng_df[“trinta anos”] = tafeng_df.apply(
lambda fila: 1 se linha[“AGE_GROUP”] em ([“30-34”, “35-39”]) mais 0, axis=1
)
tafeng_df[“quarenta”] = tafeng_df.apply(
lambda fila: 1 se linha[“AGE_GROUP”] em ([“40-44”, “45-49”]) mais 0, axis=1
)
tafeng_df[“cinquenta”] = tafeng_df.apply(
lambda fila: 1 se linha[“AGE_GROUP”] em ([“50-54”, “55-59”]) mais 0, axis=1
)
tafeng_df[“sixties_and_above”] = tafeng_df.apply(
lambda fila: 1 se linha[“AGE_GROUP”] em ([“60-64”, “>65”]) mais 0, axis=1
)
Agora que nosso data está pronto, precisamos criar um ChoiceDataset, o objeto manipulador data em escolha-aprendizagem. Isso envolve a especificação dos recursos que descrevem o contexto em que uma compra é feita:
- Características do cliente (recursos compartilhados): a categoria de idade
- Características do produto (características do item): o preço do item
Um aspecto fundamental da modelagem de escolha é que exigimos as características de todos os itens disponíveis no momento da compra, e não apenas o escolhido. Isso nos permite analisar como os preços de diferentes produtos influenciam a decisão do cliente. Como essas informações não estão diretamente disponíveis no dataset, presumimos que, para cada compra, os preços dos outros itens permanecem os mesmos da venda anterior.
id_to_index =
para i, product_id em enumerar(np.sort(tafeng_df.PRODUCT_ID.unique())):
id_to_index[product_id] = i
# Inicializar o preço dos itens
preços = [[0] para _ em alcance(len(id_to_index))]. para k, v em id_to_index.items():
preços[v][0] = tafeng_df.loc[tafeng_df.PRODUCT_ID == k].SALES_PRICE.to_numpy()[0] # Crie as matrizes que constituirão o ChoiceDataset
shared_features = [] items_features = [] choices = [] # Para cada item comprado, economizamos:
# - a representação da idade (one-hot) do cliente
# - o preço de todos os itens vendidos
para i, linha em tafeng_df.iterrows():
item_index = id_to_index[row.PRODUCT_ID] preços[item_index][0] = row.SALES_PRICE
shared_features.append(
linha[["twenties" (vinte anos)", "trinta anos", "quarenta", "cinquenta", "sixties_and_above"]].to_numpy()
)
items_features.append(prices)
choices.append(item_index)
Agora que temos todas as nossas informações, podemos criar o ChoiceDataset:
dataset = ChoiceDataset(
shared_features_by_choice=shared_features,
shared_features_by_choice_names=[‘vinte anos’, ‘trinta anos’, ‘quarenta’, ‘anos cinquenta’, ‘sixties_and_above’ (anos 60 e acima)’],
items_features_by_choice=itens_features,
items_features_by_choice_names=[“SALES_PRICE”],
choices=escolhas
)
Definição e estimativa do modelo de escolha
Desenvolveremos e estimaremos um modelo de escolha que prevê a probabilidade de um cliente selecionar um item específico de um sortimento completo de produtos semelhantes. Com base no dataset disponível, definimos a seguinte função de utilidade para um item i considerado por um cliente j:
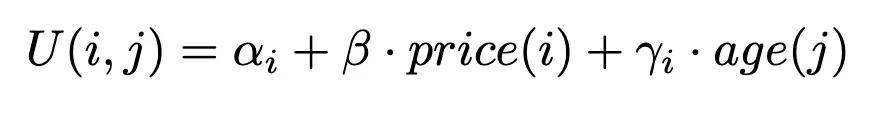
Essa função representa a utilidade (ou satisfação) que um cliente obtém ao escolher um determinado item, influenciada tanto pela idade do cliente quanto pelo preço do item.
Para obter mais detalhes sobre como formulamos uma função de utilidade, consulte nosso primeiro post. Observe que outro modelo lógico - mas não apresentado para simplificar - poderia ser estimar uma sensibilidade de preço por categoria de idade.
Aqui está o código para estimar esse modelo com choice-learn:
model.add_coefficients(
coefficient_name=age_category, feature_name=age_category, items_indexes=lista(alcance(20))
)
coefficient_name=“price” (preço)”, feature_name=“SALES_PRICE”, items_indexes=lista(alcance(20))
)
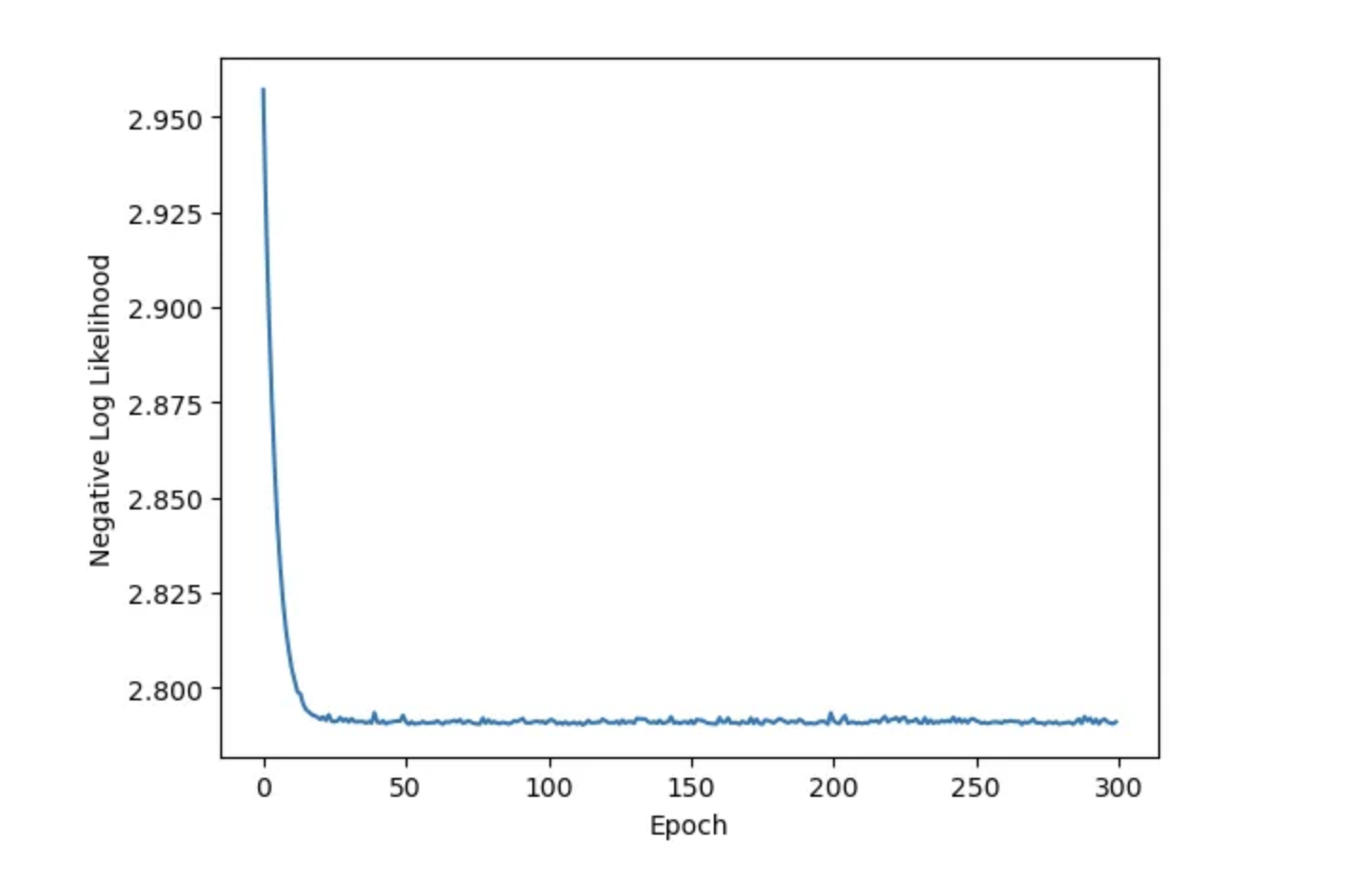
O senhor pode verificar se o modelo se encaixa bem no dataset:
plt.plot(hist[“train_loss” (perda de trem)”])
plt.xlabel(“Epoch” (Época)”)
plt.ylabel(“Negative Log Likelihood” (Probabilidade de log negativo)”)
plt.show(
Encontrar o sortimento ideal
Com as probabilidades de compra em mãos, podemos agora estimar a receita média por cliente de um sortimento A usando a fórmula:
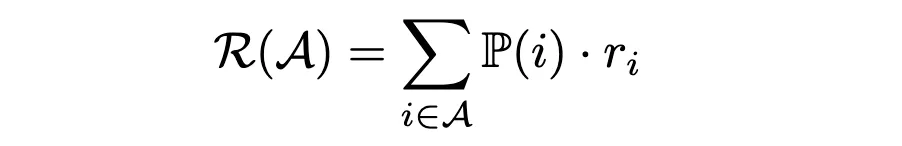
Para encontrar o sortimento que maximiza a receita, poderíamos avaliar todas as combinações possíveis e selecionar aquela com a maior receita média. No entanto, uma abordagem mais eficiente é usar Programação Linear (LP). Aqui, vamos nos concentrar em como usar o escolha-aprendizagem implementação do otimizador de sortimento.
É importante distinguir entre maximizar a receita e maximizar as margens de lucro. Embora a receita seja importante, as margens de lucro levam em conta os custos associados a cada produto. Dependendo de sua meta, o senhor pode querer otimizar o lucro em vez da receita pura.
Para otimizar o sortimento, precisamos fornecer vários insumos importantes:
- O peso que queremos dar a cada categoria de idade, vamos usar a participação dos clientes
- A utilidade de cada item (calculada por nosso modelo de escolha) para cada categoria de idade
- O valor a ser otimizado para cada item (neste caso, receita)
- O tamanho do sortimento (por exemplo, 12 itens)
Veja como funciona usando escolha-aprendizagem:
de choice_learn.toolbox.assortment_optimizer importação LatentClassAssortmentOptimizer
# Preço de cada item
future_prices = np.stack([items_features[-1]]*5, axis=0)
age_category = np.eye(5).astype("float32")
# Calcular a utilidade de cada item, considerando seu preço e cada categoria de idade
predicted_utilities = model.compute_batch_utility(shared_features_by_choice=age_category,
items_features_by_choice=future_prices,
available_items_by_choice=np.ones((5, 20)),
escolhas=Nenhum
)
age_category_weights = np.soma(shared_features, axis=0) / len(shared_features)
opt = LatentClassAssortmentOptimizer(
solver="or-tools" (ferramentas)", # Solver a ser usado, seja "or-tools" ou "gurobi" (se o senhor tiver uma licença)
class_weights=age_category_weights, # Pesos de cada classe
class_utilities=np.exp(predicted_utilities), Utilitários # na forma (n_classes, n_items)
itemwise_values=future_prices[0][:, 0], # Valores a serem otimizados para cada item, aqui o preço que é usado para calcular o faturamento
assortment_size=12) # Tamanho do sortimento que desejamos
sortimento, opt_obj = opt.solve()Ao executar o código, o senhor deve ter algo como:
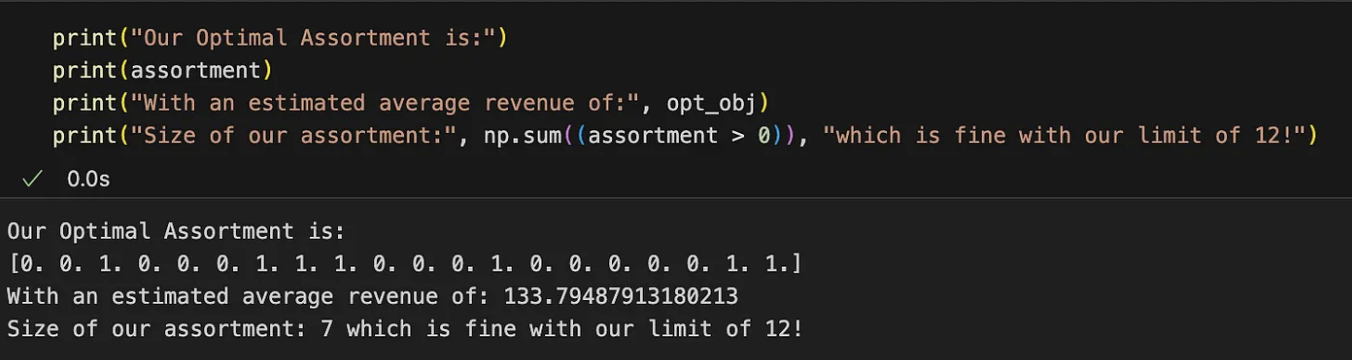
O sortimento ideal para maximizar a receita é indicado com os índices dos valores 1 no vetor. Teoricamente, esse sortimento gera uma receita média por cliente de 134 yuans. O senhor pode explorar outras combinações, mas todas elas resultarão em uma receita média menor.
Outro objetivo poderia ser maximizar o número de vendas. Nesse cenário, o valor por item para otimização é definido como 1 para todos os itens, o que leva a um sortimento ideal diferente.
A eficiência desse método fica evidente quando são introduzidas restrições adicionais. Por exemplo, talvez o senhor precise levar em conta as limitações de espaço nas prateleiras da loja. Nesse caso, o senhor pode otimizar um sortimento cujo tamanho total do item não exceda o espaço disponível nas prateleiras. Essa restrição adicional, juntamente com outras, como estratégias de preços, é demonstrada aqui.
Conclusão
Se estiver trabalhando com otimização de sortimento ou preços, a modelagem de escolha é uma ótima ferramenta. O Choice-Learn fornece muitos exemplos interessantes em seu site GitHub. Dê uma olhada e deixe uma estrela se o senhor achar útil!
