

Auteur


L'optimisation de l'assortiment est un processus critique dans le commerce de détail qui implique la sélection d'un mélange idéal de produits pour répondre à la demande des consommateurs tout en tenant compte des nombreuses contraintes logistiques. Les détaillants doivent s'assurer qu'ils proposent les bons produits, dans les bonnes quantités et au bon moment. En tirant parti de data et de la connaissance des consommateurs, les détaillants peuvent prendre des décisions éclairées sur les articles à stocker, sur la manière de gérer les stocks et sur les produits à privilégier en fonction des préférences des clients, des tendances saisonnières et des modèles de vente.
Pour les commerces de détail, l'optimisation de l'assortiment est essentielle pour trouver un équilibre entre variété et l'efficacité. Offrir trop peu de choix risque de faire fuir les clients, tandis qu'en offrir trop peut entraîner une certaine confusion, des stocks excédentaires et une baisse des marges bénéficiaires. L'optimisation de l'assortiment des produits permet aux entreprises d'améliorer la satisfaction des clients en veillant à ce que les articles les plus populaires soient disponibles et en éliminant les produits peu performants qui occupent un espace précieux dans les rayons.
Modélisation des choix La modélisation des choix est un moyen efficace d'aborder l'optimisation de l'assortiment car elle fournit un cadre data-driven pour comprendre les préférences des clients et prédire la manière dont ils choisiront entre différents produits. En analysant divers facteurs tels que la sensibilité au prix, les caractéristiques du produit et la fidélité à la marque, la modélisation des choix aide les détaillants à identifier les produits les plus susceptibles de répondre à la demande des clients.
En fin de compte, la modélisation des choix permet aux détaillants d'offrir la bonne combinaison de produits, d'adapter les assortiments à des segments de clientèle spécifiques et d'optimiser l'espace en rayon pour accroître la rentabilité ou même la tarification des articles.
Si vous n'avez jamais entendu parler de la modélisation des choix, vous pouvez lire notre article qui présente les concepts clés à l'aide d'exemples. Dans cet article, nous nous concentrerons principalement sur la manière dont les modèles de choix discrets peuvent être utilisés pour optimiser un assortiment de produits. Nous fournissons des exemples de code basés sur le choix-apprentissage qui est conçue pour aider les scientifiques de data dans de tels cas d'utilisation.
Le code fourni utilise le paquetage Python choice-learn et peut être trouvé dans un notebook. ici.
Mise en place : Installation de Python et Choice-Learn
Dans cet article, nous fournissons des extraits de code pour accompagner les explications. Le code utilise la méthode Apprendre à choisir qui fournit des outils efficaces pour la modélisation des choix et plusieurs applications - telles que l'optimisation des assortiments ou des prix. Choice-Learn est disponible via PyPI, vous pouvez l'obtenir simplement avec
Le dataset : tickets de caisse
Nous utiliserons l'épicerie TaFeng dataset. Vous pouvez le télécharger à partir de Kaggle et ouvrez-le dans votre environnement Python avec choice-learn :
print(tafeng_df.head())

L'ensemble dataset comprend plus de 800 000 achats individuels dans une épicerie chinoise. Pour chaque achat, divers détails sont fournis, notamment l'article acheté (PRODUCT_ID), le prix auquel il a été vendu (SALES_PRICE) et le groupe d'âge du client (AGE_GROUP).
Vous pouvez observer que de nombreux articles différents sont proposés et que certains d'entre eux sont rarement vendus. Afin de rationaliser la logistique, le détaillant peut choisir de réduire le nombre de produits qu'il propose. Dans ce cas, l'objectif est d'identifier le sous-ensemble optimal d'articles à vendre.
Pour ce faire, nous nous concentrons sur les articles les plus vendus, car ils sont plus susceptibles d'être achetés à nouveau et joueront un rôle crucial dans l'élaboration d'un assortiment plus efficace et plus rentable. Notez que nous procédons ainsi principalement pour simplifier l'exemple et que tous les éléments peuvent être conservés.
tafeng_df = tafeng_df.loc[
tafeng_df.PRODUCT_ID.isin(tafeng_df.PRODUCT_ID.value_counts().index[ :20])
].reset_index(drop=Vrai)
tafeng_df = tafeng_df.loc[
tafeng_df.AGE_GROUP.isin([“25-29”, “40-44”, “45-49”, “>65”, “30-34”, “35-39”, “50-54”, “55-59”, “60-64”] )
].reset_index(drop=Vrai)
Codons également les catégories d'âge avec une valeur chaude tous les dix ans :
tafeng_df[“vingts”] = tafeng_df.apply(lambda rangée : 1 si rangée[“AGE_GROUP”] == “25-29” autre 0, axis=1)
tafeng_df[“Trente ans”] = tafeng_df.apply(
lambda rangée : 1 si rangée[“AGE_GROUP”] en ([“30-34”, “35-39”]) autre 0, axis=1
)
tafeng_df[“quarantaine”] = tafeng_df.apply(
lambda rangée : 1 si rangée[“AGE_GROUP”] en ([“40-44”, “45-49”]) autre 0, axis=1
)
tafeng_df[“années 50”] = tafeng_df.apply(
lambda rangée : 1 si rangée[“AGE_GROUP”] en ([“50-54”, “55-59”]) autre 0, axis=1
)
tafeng_df[“sixties_and_above”] = tafeng_df.apply(
lambda rangée : 1 si rangée[“AGE_GROUP”] en ([“60-64”, “>65”]) autre 0, axis=1
)
Maintenant que notre data est prêt, nous devons créer un fichier ChoixDataset, l'objet gestionnaire data en choix-apprentissage. Il s'agit de spécifier les caractéristiques qui décrivent le contexte dans lequel un achat est effectué :
- Caractéristiques des clients (caractéristiques communes) : la catégorie d'âge
- Caractéristiques du produit (caractéristiques de l'article) : le prix de l'article
L'un des aspects essentiels de la modélisation des choix est que nous avons besoin des caractéristiques des tous les articles disponibles au moment de l'achat, et pas seulement celui qui a été choisi. Cela nous permet d'analyser comment les prix des différents produits influencent la décision du client. Comme cette information n'est pas directement disponible dans l'ensemble 1TP41, nous faisons l'hypothèse que pour chaque achat, les prix des autres articles restent identiques à ceux de la vente précédente.
id_to_index =
pour i, product_id en énumérer(np.sort(tafeng_df.PRODUCT_ID.unique())) :
id_to_index[product_id] = i
# Initialiser le prix des articles
prix = [[0] pour _ en gamme(len(id_to_index))] pour k, v en id_to_index.items() :
prix[v][0] = tafeng_df.loc[tafeng_df.PRODUCT_ID == k].SALES_PRICE.to_numpy()[0] # Créez les tableaux qui constitueront l'ensemble de choixDataset
caractéristiques_partagées = [] items_features = [] choices = [] # Pour chaque article acheté, nous économisons :
# - la représentation de l'âge (one-hot) du client
# - le prix de tous les articles vendus
pour i, rangée en tafeng_df.iterrows() :
item_index = id_to_index[row.PRODUCT_ID] prix[item_index][0] = row.SALES_PRICE
caractéristiques_partagées.append(
rangée[["vingtième", "Trente ans", "quarantaine", "années 50", "sixties_and_above"]].to_numpy()
)
items_features.append(prices)
choices.append(item_index)
Maintenant que nous disposons de toutes les informations, nous pouvons créer l'ensemble Choix1TP42:
dataset = ChoixDataset(
shared_features_by_choice=caractéristiques_partagées,
shared_features_by_choice_names=[‘Vingt ans’, ‘Trente ans’, ‘Quarantième année’, ‘Les années 50’, ‘sixties_and_above’ (années 60 et plus)’],
items_features_by_choice=items_features,
items_features_by_choice_names=[“PRIX_VENTE”],
choices=choix
)
Définition et estimation du modèle de choix
Nous allons développer et estimer un modèle de choix qui prédit la probabilité qu'un client choisisse un article spécifique parmi un assortiment complet de produits similaires. Sur la base de l'ensemble dataset disponible, nous définissons la fonction d'utilité suivante pour un article i considérée par un client j :
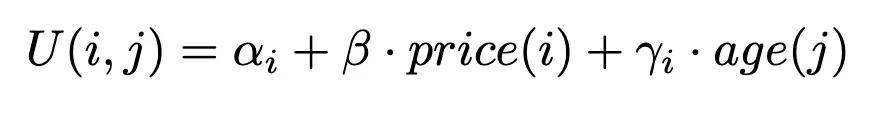
Cette fonction représente l'utilité (ou la satisfaction) qu'un client retire du choix d'un article particulier, influencée à la fois par l'âge du client et par le prix de l'article.
Pour plus de détails sur la façon dont nous formulons une fonction d'utilité, reportez-vous à notre premier article sur la fonction d'utilité. poste. Notez qu'un autre modèle logique - mais non présenté pour rester simple - pourrait consister à estimer une sensibilité au prix par catégorie d'âge.
Voici le code permettant d'estimer un tel modèle avec l'apprentissage par choix :
modèle.add_coefficients(
nom_du_coefficient=catégorie_d'âge, nom_de_la_caractéristique=catégorie_d'âge, index_des_éléments=.liste(gamme(20))
)
nom_du_coefficient=“prix”, feature_name=“PRIX_VENTE”, items_indexes=liste(gamme(20))
)
Vous pouvez vérifier que le modèle s'adapte bien au dataset :
plt.plot(hist[“perte_de_train”])
plt.xlabel(“Époque”)
plt.ylabel(“Vraisemblance logarithmique négative”)
plt.show(
Trouver l'assortiment optimal
Avec les probabilités d'achat en main, nous pouvons maintenant estimer le revenu moyen par client d'un assortiment A à l'aide de la formule :
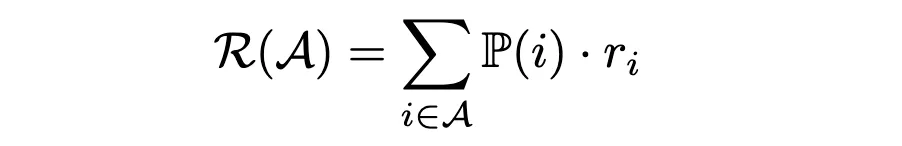
Pour trouver l'assortiment qui maximise les recettes, nous pourrions évaluer toutes les combinaisons possibles et sélectionner celle dont les recettes moyennes sont les plus élevées. Cependant, une approche plus efficace consiste à utiliser Programmation linéaire (LP). Ici, nous nous concentrerons sur l'utilisation de la fonction choix-apprentissage la mise en œuvre de l'optimiseur d'assortiment.
Il est important de faire la distinction entre la maximisation des recettes et la maximisation des marges bénéficiaires. Si les recettes sont importantes, les marges bénéficiaires tiennent compte des coûts associés à chaque produit. En fonction de votre objectif, vous souhaiterez peut-être optimiser les bénéfices plutôt que le chiffre d'affaires.
Pour optimiser l'assortiment, nous devons fournir plusieurs données clés :
- Le poids que nous voulons donner à chaque catégorie d'âge, allons-y avec leur part de clientèle.
- L'utilité de chaque article (calculée par notre modèle de choix) pour chaque catégorie d'âge
- La valeur à optimiser pour chaque élément (dans ce cas, le revenu)
- La taille de l'assortiment (par exemple, 12 articles)
Voici comment cela fonctionne en utilisant choix-apprentissage:
de choice_learn.toolbox.assortment_optimizer l'importation LatentClassAssortmentOptimizer
# Prix de chaque article
prix_futurs = np.stack([items_features[-1]]*5, axis=0)
age_category = np.eye(5).astype("float32")
# Calculer l'utilité de chaque article en fonction de son prix et de chaque catégorie d'âge
predicted_utilities = model.compute_batch_utility(shared_features_by_choice=age_category,
items_features_by_choice=future_prices,
articles_disponibles_par_choix=np.ones((5, 20)),
choix=Aucun
)
poids_catégorie_âge = np.somme(caractéristiques_partagées, axis=0) / len(caractéristiques_partagées)
opt = LatentClassAssortmentOptimizer(
solveur="ou-outils", # Solveur à utiliser, soit "or-tools" ou "gurobi" (si vous avez une licence)
poids_de_la_classe=poids_de_la_catégorie_de_l'âge, # Poids de chaque classe
class_utilities=np.exp(predicted_utilities), # utilités dans la forme (n_classes, n_éléments)
itemwise_values=future_prices[0][:, 0], # Valeurs à optimiser pour chaque article, ici le prix utilisé pour calculer le chiffre d'affaires
taille_assortiment=12) # Taille de l'assortiment souhaité
assortiment, opt_obj = opt.solve()En exécutant le code, vous devriez obtenir quelque chose comme :
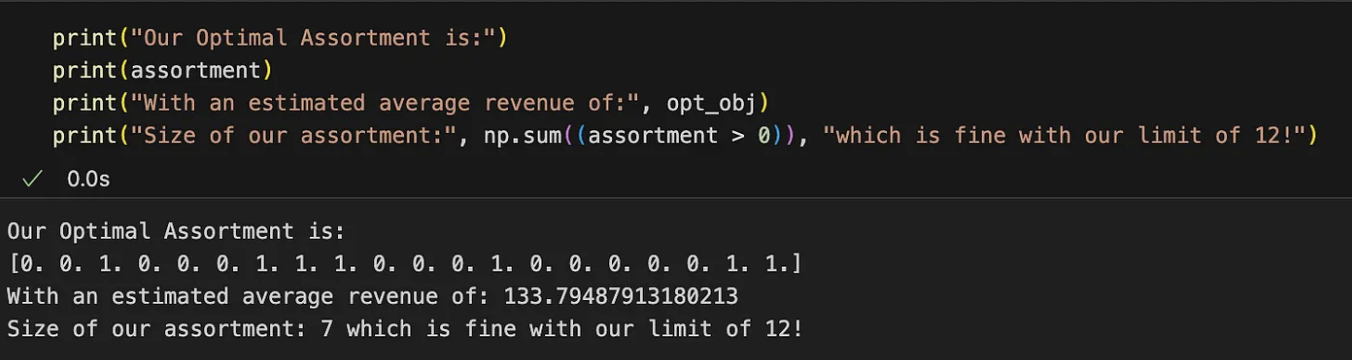
L'assortiment optimal pour maximiser le revenu est indiqué par les indices des valeurs 1 dans le vecteur. Cet assortiment permet théoriquement d'obtenir une recette moyenne par client de 134 yuans. Vous pouvez explorer d'autres combinaisons, mais elles se traduiront toutes par une recette moyenne inférieure.
Un autre objectif pourrait être de maximiser le nombre de ventes. Dans ce scénario, la valeur de l'optimisation par article est fixée à 1 pour tous les articles, ce qui conduit à un assortiment optimal différent.
L'efficacité de cette méthode devient évidente lorsque des contraintes supplémentaires sont introduites. Par exemple, il se peut que vous deviez tenir compte des limites de l'espace en rayon dans votre magasin. Dans ce cas, vous pouvez optimiser un assortiment dont la taille totale des articles n'excède pas l'espace disponible en rayon. Cette contrainte supplémentaire, ainsi que d'autres telles que les stratégies de prix, est démontrée. ici.
Pour conclure
Si vous travaillez sur l'optimisation de l'assortiment ou la tarification, la modélisation des choix est un outil formidable, ne manquez pas de vous y intéresser. Choice-Learn fournit de nombreux exemples intéressants sur son site Web. GitHub. Allez y jeter un coup d'oeil et laissez une étoile si vous l'avez trouvé utile !
