

Auteur


Assortimentoptimalisatie is een cruciaal proces in de detailhandel waarbij het gaat om de ideale mix van producten samenstellen om aan de vraag van de consument te voldoen, rekening houdend met de vele logistieke beperkingen. De retailers moeten ervoor zorgen dat ze de juiste producten in de juiste hoeveelheden op het juiste moment aanbieden. Door gebruik te maken van data en consumenteninzichten kunnen retailers weloverwogen beslissingen nemen over welke artikelen ze in voorraad moeten nemen, hoe ze de voorraad moeten beheren en welke producten ze prioriteit moeten geven op basis van klantvoorkeuren, seizoensgebonden trends en verkooppatronen.
Voor detailhandelsbedrijven is assortimentsoptimalisatie essentieel om een evenwicht te vinden tussen variëteit en efficiëntie. Het aanbieden van te weinig keuzes kan klanten wegjagen, terwijl het aanbieden van te veel keuzes kan leiden tot verwarring, overtollige voorraad en lagere winstmarges. Het optimaliseren van het productassortiment helpt bedrijven om de klanttevredenheid te verhogen door ervoor te zorgen dat populaire artikelen beschikbaar zijn, terwijl slecht presterende producten die kostbare schapruimte in beslag nemen, verwijderd worden.
Keuzemodellen is een efficiënte manier om assortimentoptimalisatie te benaderen, omdat het een data-driven raamwerk biedt om de voorkeuren van klanten te begrijpen en te voorspellen hoe zij tussen verschillende producten zullen kiezen. Door verschillende factoren te analyseren, zoals prijsgevoeligheid, productkenmerken en merkentrouw, helpt keuzemodellering retailers om te bepalen welke producten het meest waarschijnlijk aan de vraag van de klant zullen voldoen.
Uiteindelijk stelt keuzemodellering retailers in staat om de juiste mix van producten aan te bieden, assortimenten af te stemmen op specifieke klantsegmenten en schapruimte te optimaliseren om de winstgevendheid of zelfs de prijs van artikelen te verhogen.
Als u nog nooit van keuzemodellering hebt gehoord, kunt u het volgende lezen ons artikel waarin de belangrijkste concepten met voorbeelden worden uitgelegd. In dit artikel zullen we ons voornamelijk richten op hoe discrete keuzemodellen gebruikt kunnen worden om een assortiment producten te optimaliseren. We geven codevoorbeelden gebaseerd op de keuze-leren bibliotheek, die ontworpen is om data wetenschappers te helpen bij dergelijke gebruikssituaties.
De meegeleverde code maakt gebruik van het choice-learn Python-pakket en kan worden gevonden in een notitieblok hier.
Opzetten: Python & Choice-Learn installeren
In dit artikel geven we stukjes code bij de uitleg. De code gebruikt de Keuze-leren bibliotheek, die efficiënte hulpmiddelen biedt voor keuzemodellering en verschillende toepassingen - zoals assortimentsoptimalisatie of prijs. Choice-Learn is beschikbaar via PyPI, u kunt het eenvoudig verkrijgen met
De dataset : kassabonnen
We zullen de TaFeng kruidenierswinkel dataset gebruiken. U kunt deze downloaden van Kaggle en open het in uw Python-omgeving met choice-learn:
print(tafeng_df.head())

De dataset bestaat uit meer dan 800.000 individuele aankopen in een Chinese kruidenierswinkel. Voor elke aankoop worden verschillende details gegeven, waaronder het gekochte artikel (PRODUCT_ID), de prijs waarvoor het verkocht werd (SALES_PRICE) en de leeftijdsgroep van de klant (AGE_GROUP).
U kunt zien dat er veel verschillende artikelen worden aangeboden en dat sommige daarvan zelden worden verkocht. Om de logistiek te stroomlijnen, kan de detailhandelaar ervoor kiezen om het aantal producten dat hij aanbiedt te verminderen. Het doel in dit geval is om de optimale subset van te verkopen artikelen te identificeren.
Om dit te bereiken, richten we ons op de best verkopende artikelen, omdat de kans groter is dat deze opnieuw worden gekocht en een cruciale rol zullen spelen bij het vormgeven van een efficiënter en winstgevender assortiment. Merk op dat we dit vooral doen om het voorbeeld te vereenvoudigen en dat alle items behouden zouden kunnen worden.
tafeng_df = tafeng_df.loc[
tafeng_df.PRODUCT_ID.isin(tafeng_df.PRODUCT_ID.value_counts().index[:20])
].reset_index(drop=Echt)
tafeng_df = tafeng_df.loc[
tafeng_df.LEEFTIJD_GROEP.isin([“25-29”, “40-44”, “45-49”, “>65”, “30-34”, “35-39”, “50-54”, “55-59”, “60-64”] )
].reset_index(drop=Echt)
Laten we ook de leeftijdscategorieën coderen met één hete waarde per tien jaar:
tafeng_df[“twintiger jaren”] = tafeng_df.apply(lambda rij: 1 als rij[“LEEFTIJD_GROEP”.”] == “25-29” anders 0, axis=1)
tafeng_df[“jaren dertig”] = tafeng_df.apply(
lambda rij: 1 als rij[“LEEFTIJD_GROEP”.”] in ([“30-34”, “35-39”]) anders 0, axis=1
)
tafeng_df[“jaren veertig”] = tafeng_df.apply(
lambda rij: 1 als rij[“LEEFTIJD_GROEP”.”] in ([“40-44”, “45-49”]) anders 0, axis=1
)
tafeng_df[“vijftiger jaren”] = tafeng_df.apply(
lambda rij: 1 als rij[“LEEFTIJD_GROEP”.”] in ([“50-54”, “55-59”]) anders 0, axis=1
)
tafeng_df[“sixties_en_boven”] = tafeng_df.apply(
lambda rij: 1 als rij[“LEEFTIJD_GROEP”.”] in ([“60-64”, “>65”]) anders 0, axis=1
)
Nu onze data klaar is, moeten we een KeuzeDataset, het data handler-object in keuze-leren. Hierbij worden de kenmerken gespecificeerd die de context beschrijven waarin een aankoop wordt gedaan:
- Kenmerken van de klant (gedeelde kenmerken): de leeftijdscategorie
- Productkenmerken (artikelkenmerken): de artikelprijs
Een belangrijk aspect van keuzemodellering is dat we de kenmerken van alle beschikbare items op het moment van aankoop, en niet alleen het gekozen product. Hierdoor kunnen we analyseren hoe de prijzen van verschillende producten de beslissing van de klant beïnvloeden. Omdat deze informatie niet direct beschikbaar is in de dataset, nemen we aan dat voor elke aankoop de prijzen van de andere artikelen hetzelfde blijven als in de vorige verkoop.
id_naar_index =
voor i, product_id in opsommen(np.sort(tafeng_df.PRODUCT_ID.unique()):
id_to_index[product_id] = i
# De artikelprijs initialiseren
prijzen = [[0] voor _ in bereik(len(id_to_index)) voor k, v in id_to_index.items():
prijzen[v][0] = tafeng_df.loc[tafeng_df.PRODUCT_ID == k].SALES_PRICE.to_numpy()[0] # Maak de matrices die de KeuzeDataset zullen vormen
gedeelde_kenmerken = [] items_features = [] keuzes = [] # Voor elk gekocht artikel sparen wij:
# - de leeftijdsvertegenwoordiging (one-hot) van de klant
# - de prijs van alle verkochte artikelen
voor i, rij in tafeng_df.iterrows():
item_index = id_to_index[row.PRODUCT_ID] prijzen[item_index][0] = rij.SALES_PRIJS
gedeelde_kenmerken.toevoegen(
rij[["twintiger jaren", "jaren dertig", "jaren veertig", "vijftiger jaren", "sixties_en_boven"]].to_numpy()
)
items_features.append(prijzen)
keuzes.append(item_index)
Nu we al onze informatie hebben, kunnen we de KeuzeDataset maken:
dataset = KeuzeDataset(
shared_features_by_choice=gedeelde_kenmerken,
shared_features_by_choice_names=[‘twintiger jaren’, ‘jaren dertig’, ‘jaren veertig’, ‘vijftiger jaren’, ‘zestiger_en_ouder’],
items_features_by_choice=items_features,
items_features_by_choice_names=[“VERKOOPPRIJS”.”],
choices=keuzes
)
Het keuzemodel definiëren en schatten
We zullen een keuzemodel ontwikkelen en schatten dat voorspelt hoe waarschijnlijk het is dat een klant een specifiek artikel kiest uit een heel assortiment van vergelijkbare producten. Op basis van de beschikbare dataset definiëren we de volgende nutsfunctie voor een artikel i overwogen door een klant j:
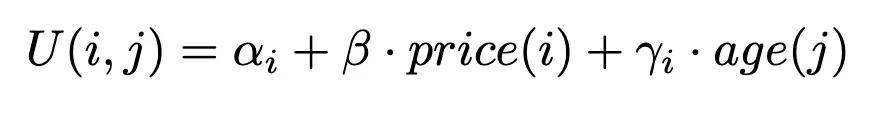
Deze functie vertegenwoordigt het nut (of de tevredenheid) die een klant haalt uit het kiezen van een bepaald artikel, beïnvloed door zowel de leeftijd van de klant als de prijs van het artikel.
Voor meer details over hoe we een nutsfunctie formuleren, verwijzen we naar onze eerste post. Merk op dat een ander logisch - maar niet gepresenteerd om het eenvoudig te houden - model zou kunnen zijn om één prijsgevoeligheid per leeftijdscategorie te schatten.
Hier is de code om een dergelijk model met choice-learn te schatten:
model.add_coëfficiënten(
coëfficiënt_naam=leeftijd_categorie, kenmerk_naam=leeftijd_categorie, items_indexen=lijst(bereik(20))
)
coëfficiënt_naam=“prijs”, feature_name=“VERKOOPPRIJS”.”, items_indexes=lijst(bereik(20))
)
U kunt controleren of het model goed op de dataset past:
plt.plot(hist[“trein_verlies”])
plt.xlabel(“Epoch”)
plt.ylabel(“Negatieve log waarschijnlijkheid”.”)
plt.show(
Het optimale assortiment vinden
Met de aankoopkansen in de hand kunnen we nu de gemiddelde opbrengst per klant van een assortiment schatten A met de formule:
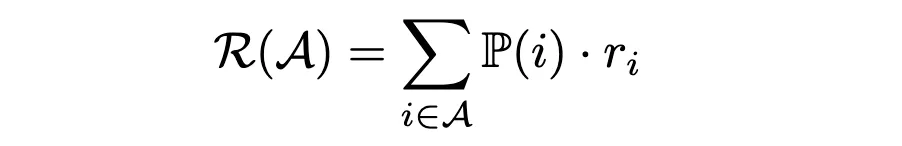
Om het assortiment te vinden dat de opbrengst maximaliseert, zouden we alle mogelijke combinaties kunnen evalueren en degene met de hoogste gemiddelde opbrengst kunnen selecteren. Een efficiëntere aanpak is echter om Lineair programmeren (LP). Hier zullen we ons concentreren op het gebruik van de keuze-leren implementatie van de assortimentsoptimalisator.
Het is belangrijk om onderscheid te maken tussen het maximaliseren van inkomsten en het maximaliseren van winstmarges. Hoewel inkomsten belangrijk zijn, houden winstmarges rekening met de kosten van elk product. Afhankelijk van uw doel wilt u misschien optimaliseren voor winst in plaats van pure inkomsten.
Om het assortiment te optimaliseren, hebben we een aantal belangrijke inputs nodig:
- Het gewicht dat we aan elke leeftijdscategorie willen geven, laten we uitgaan van hun klantenaandeel
- Het nut van elk item (berekend door ons keuzemodel) voor elke leeftijdscategorie
- De waarde die voor elk item moet worden geoptimaliseerd (in dit geval opbrengst)
- De grootte van het assortiment (bijvoorbeeld 12 artikelen)
Hier ziet u hoe het werkt met keuze-leren:
van keuze_leren.gereedschapskist.assortiment_optimaliseerder importeer LatentClassAssortmentOptimizer
# Prijs van elk item
toekomstige_prijzen = np.stack([items_features[-1]]*5, axis=0)
leeftijd_categorie = np.eye(5).astype("float32")
# Bereken het nut van elk artikel op basis van de prijs en elke leeftijdscategorie
voorspelde_utilities = model.compute_batch_utility(shared_features_by_choice=leeftijd_categorie,
items_features_by_choice=toekomstige_prijzen,
beschikbare_items_bij_keuze=np.ones(5, 20)),
keuzes=Geen
)
leeftijd_categorie_gewichten = np.som(gedeelde_kenmerken, as=0) / len(gedeelde_kenmerken)
opt = LatentClassAssortmentOptimizer(
oplosser="of-tools", # Solver om te gebruiken, ofwel "or-tools" of "gurobi" (als u een licentie hebt)
class_weights=leeftijd_categorie_gewichten, # Gewichten van elke klasse
klasse_utilities=np.exp(voorspelde_utilities), # hulpprogramma's in de vorm (n_klassen, n_items)
itemwise_values=toekomstige_prijzen[0][:, 0], # Waarden om te optimaliseren voor elk item, hier prijs die wordt gebruikt om de omzet te berekenen
assortiment_grootte=12) # Grootte van het assortiment dat we willen
assortiment, opt_obj = opt.solve()Als u de code uitvoert, zou u iets als:
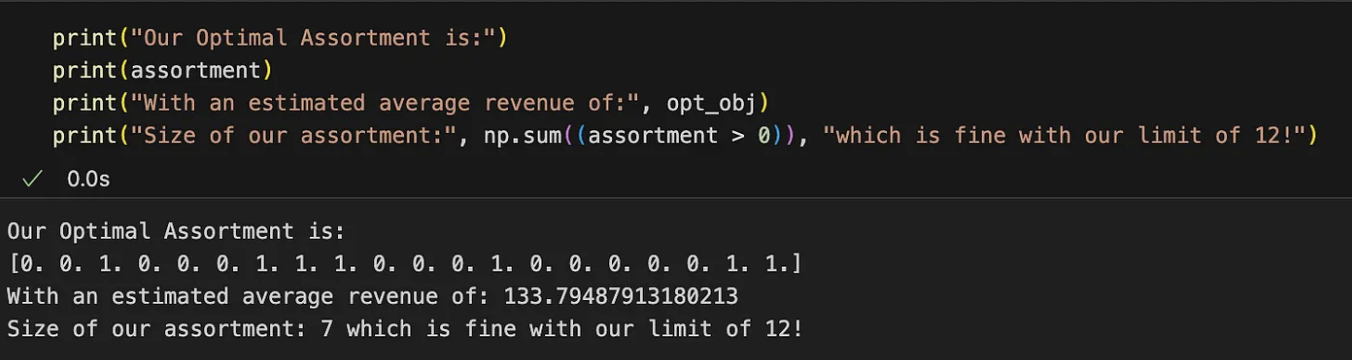
Het optimale assortiment voor het maximaliseren van de opbrengst wordt aangegeven met de indexen van de 1 waarden in de vector. Dit assortiment levert theoretisch een gemiddelde opbrengst per klant op van 134 yuan. U kunt andere combinaties onderzoeken, maar deze zullen allemaal resulteren in een lagere gemiddelde opbrengst.
Een andere doelstelling zou het maximaliseren van het aantal verkopen kunnen zijn. In dit scenario wordt de waarde per item voor optimalisatie ingesteld op 1 voor alle items, wat leidt tot een ander optimaal assortiment.
De efficiëntie van deze methode wordt duidelijk wanneer er extra beperkingen worden ingevoerd. U moet bijvoorbeeld rekening houden met schapruimtebeperkingen in uw winkel. In dat geval kunt u optimaliseren voor een assortiment waarvan de totale artikelgrootte niet groter is dan de beschikbare schapruimte. Deze extra beperking, samen met andere zoals prijsstrategieën, wordt gedemonstreerd hier.
Conclusie
Als u werkt aan assortimentsoptimalisatie of prijsstelling, is keuzemodellering een geweldig hulpmiddel. Choice-Learn biedt veel leuke voorbeelden op de website GitHub. Ga het bekijken en laat een ster achter als u het nuttig vindt!
