

Autor


Die Sortimentsoptimierung ist ein wichtiger Prozess im Einzelhandel, der Folgendes umfasst die ideale Mischung von Produkten zusammenstellen die Nachfrage der Verbraucher zu befriedigen und dabei die vielen logistischen Zwänge zu berücksichtigen. Die Einzelhändler müssen sicherstellen, dass sie die richtigen Produkte in der richtigen Menge und zur richtigen Zeit anbieten. Durch die Nutzung von data und Verbraucherinformationen können Einzelhändler fundierte Entscheidungen darüber treffen, welche Artikel sie auf Lager halten, wie sie ihren Bestand verwalten und welche Produkte sie auf der Grundlage von Kundenpräferenzen, saisonalen Trends und Verkaufsmustern priorisieren sollten.
Für Einzelhandelsunternehmen ist die Sortimentsoptimierung unerlässlich, um ein Gleichgewicht zu finden zwischen Sorte und Effizienz. Eine zu geringe Auswahl kann die Kunden vergraulen, während eine zu große Auswahl zu Verwirrung, Überbeständen und niedrigeren Gewinnspannen führen kann. Die Optimierung des Produktsortiments hilft den Unternehmen, die Kundenzufriedenheit zu erhöhen, indem sie sicherstellen, dass beliebte Artikel verfügbar sind und gleichzeitig Produkte mit geringer Leistung, die wertvollen Platz in den Regalen beanspruchen, eliminiert werden.
Modellierung von Auswahlmöglichkeiten ist eine effiziente Methode zur Sortimentsoptimierung, denn sie bietet einen data-driven Rahmen für das Verständnis der Kundenpräferenzen und die Vorhersage, wie sie zwischen verschiedenen Produkten wählen werden. Durch die Analyse verschiedener Faktoren wie Preissensibilität, Produktmerkmale und Markentreue hilft die Wahlmodellierung den Einzelhändlern zu ermitteln, welche Produkte am ehesten der Kundennachfrage entsprechen.
Letztlich ermöglicht die Modellierung der Auswahl dem Einzelhändler, den richtigen Produktmix anzubieten, die Sortimente auf bestimmte Kundensegmente zuzuschneiden und auch die Regalfläche zu optimieren, um die Rentabilität oder sogar die Preisgestaltung der Artikel zu verbessern.
Wenn Sie noch nie von Choice Modeling gehört haben, können Sie lesen unser Artikel in dem die wichtigsten Konzepte anhand von Beispielen vorgestellt werden. In diesem Artikel konzentrieren wir uns hauptsächlich darauf, wie diskrete Auswahlmodelle zur Optimierung eines Produktsortiments verwendet werden können. Wir stellen Codebeispiele zur Verfügung, die auf dem Auswahl-Lernen Bibliothek, die data Wissenschaftlern bei solchen Anwendungsfällen helfen soll.
Der bereitgestellte Code verwendet das Python-Paket choice-learn und befindet sich in einem Notizbuch Hier.
Einrichten: Installation von Python & Choice-Learn
In diesem Artikel finden Sie neben den Erklärungen auch Codeschnipsel. Der Code verwendet die Auswahl-Lernen Bibliothek, die effiziente Tools für die Modellierung von Wahlmöglichkeiten und verschiedene Anwendungen - wie Sortimentsoptimierung oder Preis - bietet. Choice-Learn ist über PyPI verfügbar, Sie erhalten es einfach mit
Das dataset : Verkaufseinnahmen
Wir werden das TaFeng Lebensmittelgeschäft dataset verwenden. Sie können es herunterladen von Kaggle und öffnen Sie es in Ihrer Python-Umgebung mit choice-learn:
print(tafeng_df.head())

Das dataset besteht aus über 800.000 einzelnen Einkäufen in einem chinesischen Lebensmittelgeschäft. Für jeden Einkauf werden verschiedene Details bereitgestellt, darunter der gekaufte Artikel (PRODUCT_ID), der Preis, zu dem er verkauft wurde (SALES_PRICE), und die Altersgruppe des Kunden (AGE_GROUP).
Sie können feststellen, dass viele verschiedene Artikel angeboten werden und einige davon nur selten verkauft werden. Um die Logistik zu rationalisieren, kann der Einzelhändler beschließen, die Anzahl der angebotenen Produkte zu reduzieren. Das Ziel in diesem Fall ist es, die optimale Teilmenge der zu verkaufenden Artikel zu ermitteln.
Um dies zu erreichen, konzentrieren wir uns auf die umsatzstärksten Artikel, da diese mit größerer Wahrscheinlichkeit wieder gekauft werden und eine entscheidende Rolle bei der Gestaltung eines effizienteren und profitableren Sortiments spielen werden. Beachten Sie, dass wir dies vor allem zur Vereinfachung des Beispiels tun und dass alle Elemente beibehalten werden könnten.
tafeng_df = tafeng_df.loc[
tafeng_df.PRODUCT_ID.isin(tafeng_df.PRODUCT_ID.value_counts().index[:20])
].reset_index(drop=Wahr)
tafeng_df = tafeng_df.loc[
tafeng_df.AGE_GROUP.isin([“25-29”, “40-44”, “45-49”, “>65”, “30-34”, “35-39”, “50-54”, “55-59”, “60-64”] )
].reset_index(drop=Wahr)
Lassen Sie uns auch die Alterskategorien mit einem heißen Wert alle zehn Jahre kodieren:
tafeng_df[“Zwanziger”] = tafeng_df.apply(lambda Zeile: 1 wenn Zeile[“AGE_GROUP”] == “25-29” sonst 0, axis=1)
tafeng_df[“Dreißiger”] = tafeng_df.apply(
lambda Zeile: 1 wenn Zeile[“AGE_GROUP”] in ([“30-34”, “35-39”]) sonst 0, axis=1
)
tafeng_df[“Vierziger”] = tafeng_df.apply(
lambda Zeile: 1 wenn Zeile[“AGE_GROUP”] in ([“40-44”, “45-49”]) sonst 0, axis=1
)
tafeng_df[“fünfziger Jahre”] = tafeng_df.apply(
lambda Zeile: 1 wenn Zeile[“AGE_GROUP”] in ([“50-54”, “55-59”]) sonst 0, axis=1
)
tafeng_df[“sixties_and_above”] = tafeng_df.apply(
lambda Zeile: 1 wenn Zeile[“AGE_GROUP”] in ([“60-64”, “>65”]) sonst 0, axis=1
)
Nun, da unser data fertig ist, müssen wir eine AuswahlDataset, wird das data-Handler-Objekt in Auswahl-Lernen. Dabei geht es darum, die Merkmale festzulegen, die den Kontext beschreiben, in dem ein Kauf getätigt wird:
- Kundeneigenschaften (gemeinsame Merkmale): die Alterskategorie
- Eigenschaften des Produkts (Artikelmerkmale): der Artikelpreis
Ein wichtiger Aspekt der Wahlmodellierung ist, dass wir die Eigenschaften der alle verfügbaren Artikel zum Zeitpunkt des Kaufs, und nicht nur das gewählte. So können wir analysieren, wie die Preise der verschiedenen Produkte die Entscheidung des Kunden beeinflussen. Da diese Information im dataset nicht direkt verfügbar ist, gehen wir davon aus, dass bei jedem Kauf die Preise der anderen Artikel die gleichen bleiben wie beim vorherigen Verkauf.
id_to_index =
für i, produkt_id in aufzählen.(np.sort(tafeng_df.PRODUCT_ID.unique())):
id_to_index[product_id] = i
# Initialisieren Sie den Artikelpreis
Preise = [[0] für _ in Reichweite(len(id_to_index))] für k, v in id_to_index.items():
Preise[v][0] = tafeng_df.loc[tafeng_df.PRODUCT_ID == k].SALES_PRICE.to_numpy()[0] # Erstellen Sie die Arrays, die das ChoiceDataset bilden werden
shared_features = [] items_features = [] choices = [] # Für jeden gekauften Artikel, sparen wir:
# - die Altersangabe (one-hot) des Kunden
# - der Preis für alle verkauften Artikel
für i, Zeile in tafeng_df.iterrows():
item_index = id_to_index[row.PRODUCT_ID] preise[artikel_index][0] = row.SALES_PRICE
shared_features.append(
Zeile[["Zwanziger", "Dreißiger", "Vierziger", "fünfziger Jahre", "sixties_and_above"]].to_numpy()
)
items_features.append(preise)
choices.append(item_index)
Jetzt, wo wir alle Informationen haben, können wir erstellen Sie das ChoiceDataset:
dataset = ChoiceDataset(
shared_features_by_choice=shared_features,
shared_features_by_choice_names=[‘Zwanziger Jahre’, ‘dreißigste’, ‘vierziger Jahre’, ‘fünfziger Jahre’.’, ‘sixties_and_above’],
items_features_by_choice=items_features,
items_features_by_choice_names=[“UMSATZPREIS”],
choices=Auswahlen
)
Definition und Schätzung des Auswahlmodells
Wir werden ein Auswahlmodell entwickeln und schätzen, das die Wahrscheinlichkeit vorhersagt, dass ein Kunde einen bestimmten Artikel aus einem ganzen Sortiment ähnlicher Produkte auswählt. Basierend auf dem verfügbaren dataset definieren wir die folgende Nutzenfunktion für einen Artikel i von einem Kunden betrachtet j:
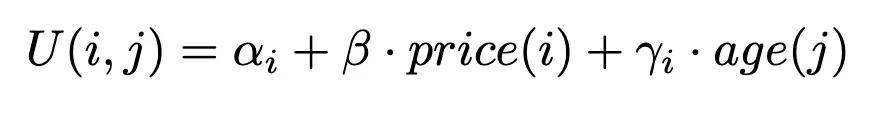
Diese Funktion stellt den Nutzen (oder die Zufriedenheit) dar, den ein Kunde aus der Wahl eines bestimmten Artikels zieht, der sowohl vom Alter des Kunden als auch vom Preis des Artikels beeinflusst wird.
Weitere Einzelheiten zur Formulierung einer Nutzenfunktion finden Sie in unserem ersten Beitrag. Beachten Sie, dass ein anderes logisches - aber der Einfachheit halber nicht vorgestelltes - Modell darin bestehen könnte, eine Preissensitivität pro Alterskategorie zu schätzen.
Hier ist der Code zur Schätzung eines solchen Modells mit choice-learn:
model.add_coefficients(
coefficient_name=alter_kategorie, feature_name=alter_kategorie, items_indexes=Liste(Reichweite(20))
)
koeffizient_name=“Preis”, feature_name=“UMSATZPREIS”, items_indexes=Liste(Reichweite(20))
)
Sie können überprüfen, ob das Modell gut auf das dataset passt:
plt.plot(hist[“train_loss”])
plt.xlabel(“Epoche”)
plt.ylabel(“Negative Log-Wahrscheinlichkeit”)
plt.show(
Finden Sie das optimale Sortiment
Mit den Kaufwahrscheinlichkeiten in der Hand können wir nun den durchschnittlichen Umsatz pro Kunde für ein Sortiment schätzen A unter Verwendung der Formel:
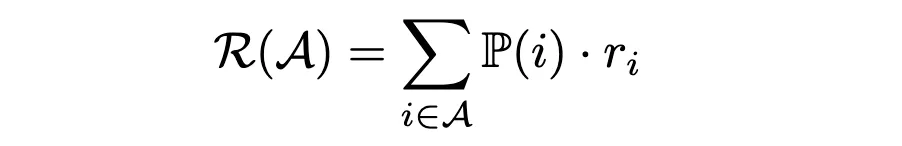
Um das Sortiment zu finden, das den Umsatz maximiert, könnten wir alle möglichen Kombinationen bewerten und diejenige mit dem höchsten Durchschnittsumsatz auswählen. Ein effizienterer Ansatz ist jedoch die Verwendung von Lineare Programmierung (LP). Hier werden wir uns darauf konzentrieren, wie Sie die Auswahl-Lernen Implementierung des Sortimentsoptimierers.
Es ist wichtig, zwischen der Maximierung der Einnahmen und der Maximierung der Gewinnspannen zu unterscheiden. Während der Umsatz wichtig ist, werden bei den Gewinnspannen die mit jedem Produkt verbundenen Kosten berücksichtigt. Je nach Ihrem Ziel sollten Sie eher auf den Gewinn als auf den reinen Umsatz hin optimieren.
Um das Sortiment zu optimieren, müssen wir mehrere wichtige Informationen bereitstellen:
- Die Gewichtung, die wir jeder Alterskategorie geben wollen, geht von ihrem Kundenanteil aus.
- Der Nutzen der einzelnen Artikel (berechnet durch unser Auswahlmodell) für jede Alterskategorie
- Der zu optimierende Wert für jedes Element (in diesem Fall der Umsatz)
- Die Größe des Sortiments (z.B. 12 Artikel)
So funktioniert es mit Auswahl-Lernen:
von choice_learn.toolbox.assortment_optimizer importieren LatentClassAssortmentOptimizer
# Preis für jeden Artikel
future_prices = np.stack([items_features[-1]]*5, axis=0)
age_category = np.eye(5).astype("float32")
# Berechnen Sie den Nutzen eines jeden Artikels angesichts seines Preises und jeder Alterskategorie
predicted_utilities = model.compute_batch_utility(shared_features_by_choice=age_category,
items_features_by_choice=future_prices,
available_items_by_choice=np.ones((5, 20)),
choices=Keine
)
age_category_weights = np.Summe(shared_features, axis=0) / len(shared_features)
opt = LatentClassAssortmentOptimizer(
solver="oder-tools", # Solver zu verwenden, entweder "or-tools" oder "gurobi" (wenn Sie eine Lizenz haben)
class_weights=age_category_weights, # Gewichte der einzelnen Klassen
class_utilities=np.exp(predicted_utilities), # Dienstprogramme in der Form (n_classes, n_items)
itemwise_values=future_prices[0][:, 0], # Zu optimierende Werte für jeden Artikel, hier Preis, der zur Berechnung des Umsatzes verwendet wird
assortment_size=12) # Größe des gewünschten Sortiments
Sortiment, opt_obj = opt.solve()Wenn Sie den Code ausführen, sollten Sie etwas erhalten wie:
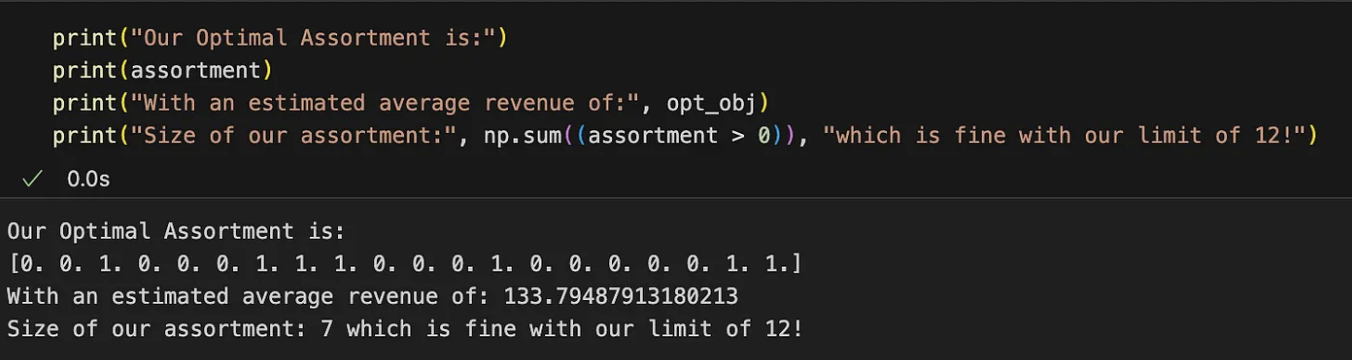
Das optimale Sortiment zur Maximierung des Umsatzes ist mit den Indizes der 1-Werte im Vektor angegeben. Dieses Sortiment führt theoretisch zu einem durchschnittlichen Umsatz pro Kunde von 134 Yuan. Sie können auch andere Kombinationen ausprobieren, aber sie werden alle zu einem niedrigeren Durchschnittserlös führen.
Ein anderes Ziel könnte sein, die Anzahl der Verkäufe zu maximieren. In diesem Szenario wird der artikelweise Wert für die Optimierung für alle Artikel auf 1 gesetzt, was zu einem anderen optimalen Sortiment führt.
Die Effizienz dieser Methode wird deutlich, wenn zusätzliche Beschränkungen eingeführt werden. Zum Beispiel müssen Sie vielleicht die begrenzte Regalfläche in Ihrem Geschäft berücksichtigen. In diesem Fall können Sie für ein Sortiment optimieren, dessen Gesamtgröße die verfügbare Regalfläche nicht überschreitet. Diese zusätzliche Einschränkung wird zusammen mit anderen, wie z.B. Preisstrategien, demonstriert Hier.
Fazit
Wenn Sie an der Sortimentsoptimierung oder Preisgestaltung arbeiten, ist die Wahlmodellierung ein großartiges Werkzeug, das Sie sich unbedingt ansehen sollten. Choice-Learn bietet viele tolle Beispiele auf seiner GitHub. Schauen Sie es sich an und hinterlassen Sie einen Stern, wenn Sie es nützlich finden!
