

Autor


La optimización del surtido es un proceso crítico en el comercio minorista que implica curar la mezcla ideal de productos para satisfacer la demanda de los consumidores, teniendo en cuenta al mismo tiempo las numerosas limitaciones logísticas existentes. Los minoristas tienen que asegurarse de ofrecer los productos adecuados, en las cantidades adecuadas y en el momento oportuno. Aprovechando el data y los conocimientos de los consumidores, los minoristas pueden tomar decisiones informadas sobre qué artículos almacenar, cómo gestionar el inventario y qué productos priorizar en función de las preferencias de los clientes, las tendencias estacionales y los patrones de venta.
Para las empresas minoristas, la optimización del surtido es esencial para lograr un equilibrio entre variedad y eficacia. Ofrecer muy pocas opciones puede ahuyentar a los clientes, mientras que ofrecer demasiadas puede generar confusión, exceso de inventario y menores márgenes de beneficio. Optimizar el surtido de productos ayuda a las empresas a mejorar la satisfacción del cliente garantizando la disponibilidad de los artículos más populares y eliminando al mismo tiempo los productos de bajo rendimiento que ocupan un valioso espacio en las estanterías.
Modelo de elección es una forma eficaz de abordar la optimización del surtido porque proporciona un marco data-driven para comprender las preferencias de los clientes y predecir cómo elegirán entre distintos productos. Mediante el análisis de diversos factores como la sensibilidad al precio, las características del producto y la fidelidad a la marca, el modelado de la elección ayuda a los minoristas a identificar qué productos tienen más probabilidades de satisfacer la demanda de los clientes.
En última instancia, el modelado de la elección permite a los minoristas ofrecer la combinación adecuada de productos, adaptar los surtidos a segmentos específicos de clientes, y también puede optimizar el espacio en los estantes para impulsar la rentabilidad o incluso el precio de los artículos.
Si nunca ha oído hablar del modelado de elección, puede leer nuestro artículo que introduce los conceptos clave con ejemplos. En este artículo, nos centraremos principalmente en cómo pueden utilizarse los modelos de elección discreta para optimizar un surtido de productos. Proporcionamos ejemplos de código basados en el elija-aprenda que está diseñada para ayudar a los científicos data en estos casos de uso.
El código proporcionado utiliza el paquete choice-learn de Python y se puede encontrar en un cuaderno aquí.
Configurar: Instalación de Python y Choice-Learn
En este artículo, proporcionamos fragmentos de código para acompañar las explicaciones. El código utiliza el Elegir-Aprender que proporciona herramientas eficaces para el modelado de la elección y varias aplicaciones, como la optimización del surtido o el precio. Choice-Learn está disponible a través de PyPI, puede obtenerla simplemente con
El dataset : recibos de caja
Utilizaremos el alimentador TaFeng dataset. Puede descargarlo de Kaggle y ábralo en su entorno Python con choice-learn:
print(tafeng_df.head())

El conjunto data consiste en más de 800.000 compras individuales en una tienda de comestibles china. Para cada compra se proporcionan diversos detalles, como el artículo adquirido (PRODUCT_ID), el precio al que se vendió (SALES_PRICE) y el grupo de edad del cliente (AGE_GROUP).
Puede observar que se ofrecen muchos artículos diferentes y que algunos de ellos se venden raramente. Para racionalizar la logística, el minorista puede optar por reducir el número de productos que ofrece. El objetivo en este caso es identificar el subconjunto óptimo de artículos a vender.
Para lograrlo, nos centramos en los artículos más vendidos, ya que es más probable que se vuelvan a comprar y desempeñarán un papel crucial en la configuración de un surtido más eficaz y rentable. Tenga en cuenta que hacemos esto principalmente para simplificar el ejemplo y que todos los elementos podrían conservarse.
tafeng_df = tafeng_df.loc[
tafeng_df.PRODUCT_ID.isin(tafeng_df.PRODUCT_ID.value_counts().index[:20])
].reset_index(drop=Verdadero)
tafeng_df = tafeng_df.loc[
tafeng_df.AGE_GROUP.isin([“25-29”, “40-44”, “45-49”, “>65”, “30-34”, “35-39”, “50-54”, “55-59”, “60-64”] )
].reset_index(drop=Verdadero)
Codifiquemos también las categorías de edad con un valor caliente cada diez años:
tafeng_df[“veinteañeros”] = tafeng_df.apply(lambda fila: 1 si fila[“AGE_GROUP”] == “25-29” si no 0, eje=1)
tafeng_df[“treintañeros”] = tafeng_df.apply(
lambda fila: 1 si fila[“AGE_GROUP”] en ([“30-34”, “35-39”]) si no 0, eje=1
)
tafeng_df[“cuarentones”] = tafeng_df.apply(
lambda fila: 1 si fila[“AGE_GROUP”] en ([“40-44”, “45-49”]) si no 0, eje=1
)
tafeng_df[“cincuentones”] = tafeng_df.apply(
lambda fila: 1 si fila[“AGE_GROUP”] en ([“50-54”, “55-59”]) si no 0, eje=1
)
tafeng_df[“sesenta_y_más”] = tafeng_df.apply(
lambda fila: 1 si fila[“AGE_GROUP”] en ([“60-64”, “>65”]) si no 0, eje=1
)
Ahora que nuestro data está listo, necesitamos crear un Juego Choice1TP42, el objeto manipulador data en elija-aprenda. Se trata de especificar las características que describen el contexto en el que se realiza una compra:
- Características de los clientes (características compartidas): la categoría de edad
- Características del producto (características del artículo): el precio del artículo
Un aspecto clave de la modelización de la elección es que requerimos las características de todos los artículos disponibles en el momento de una compra, y no sólo el elegido. Esto nos permite analizar cómo influyen los precios de los distintos productos en la decisión del cliente. Dado que esta información no está disponible directamente en el dataset, partimos del supuesto de que, para cada compra, los precios de los demás artículos siguen siendo los mismos que en la venta anterior.
id_to_index =
para i, product_id en enumerar(np.sort(tafeng_df.PRODUCT_ID.unique())):
id_to_index[product_id] = i
# Inicializar el precio de los artículos
precios = [[0] para _ en gama(len(id_a_índice))] para k, v en id_to_index.items():
precios[v][0] = tafeng_df.loc[tafeng_df.PRODUCT_ID == k].SALES_PRICE.to_numpy()[0] # Cree las matrices que constituirán el conjunto ChoiceData
características_compartidas = [] items_features = [] opciones = [] # Por cada artículo comprado, ahorramos:
# - la representación de la edad (one-hot) del cliente
# - el precio de todos los artículos vendidos
para i, fila en tafeng_df.iterrows():
item_index = id_to_index[fila.PRODUCT_ID] precios[item_index][0] = fila.PRECIO_VENTA
shared_features.append(
fila[["veinteañeros", "treintañeros", "cuarentones", "cincuentones", "sesenta_y_más"]].to_numpy()
)
items_features.append(precios)
choices.append(item_index)
Ahora que tenemos toda nuestra información, podemos crear el conjunto ChoiceData:
1TP41Conjunto = Elección1TP42Conjunto(
shared_features_by_choice=características_compartidas,
shared_features_by_choice_names=[‘veinteañeros’, ‘treintañeros’, ‘cuarenta’, ‘cincuentones’, ‘sesenta_y_más’],
items_features_by_choice=características_de_los_artículos,
items_features_by_choice_names=[“PRECIO_VENTA”],
opciones=elecciones
)
Definición y estimación del modelo de elección
Desarrollaremos y estimaremos un modelo de elección que prediga la probabilidad de que un cliente seleccione un artículo específico de entre todo un surtido de productos similares. Basándonos en el conjunto data disponible, definimos la siguiente función de utilidad para un artículo i considerado por un cliente j:
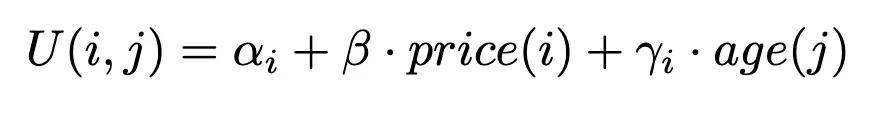
Esta función representa la utilidad (o satisfacción) que un cliente obtiene al elegir un artículo concreto, influida tanto por la edad del cliente como por el precio del artículo.
Para más detalles sobre cómo formulamos una función de utilidad, consulte nuestro primer escriba a. Tenga en cuenta que otro modelo lógico -pero no presentado para simplificar- podría ser estimar una sensibilidad al precio por categoría de edad.
He aquí el código para estimar un modelo de este tipo con choice-learn:
modelo.añadir_coeficientes(
coeficiente_nombre=edad_categoría, rasgo_nombre=edad_categoría, ítems_índices=lista(gama(20))
)
nombre_coeficiente=“precio”, feature_name=“PRECIO_VENTA”, items_indexes=lista(gama(20))
)
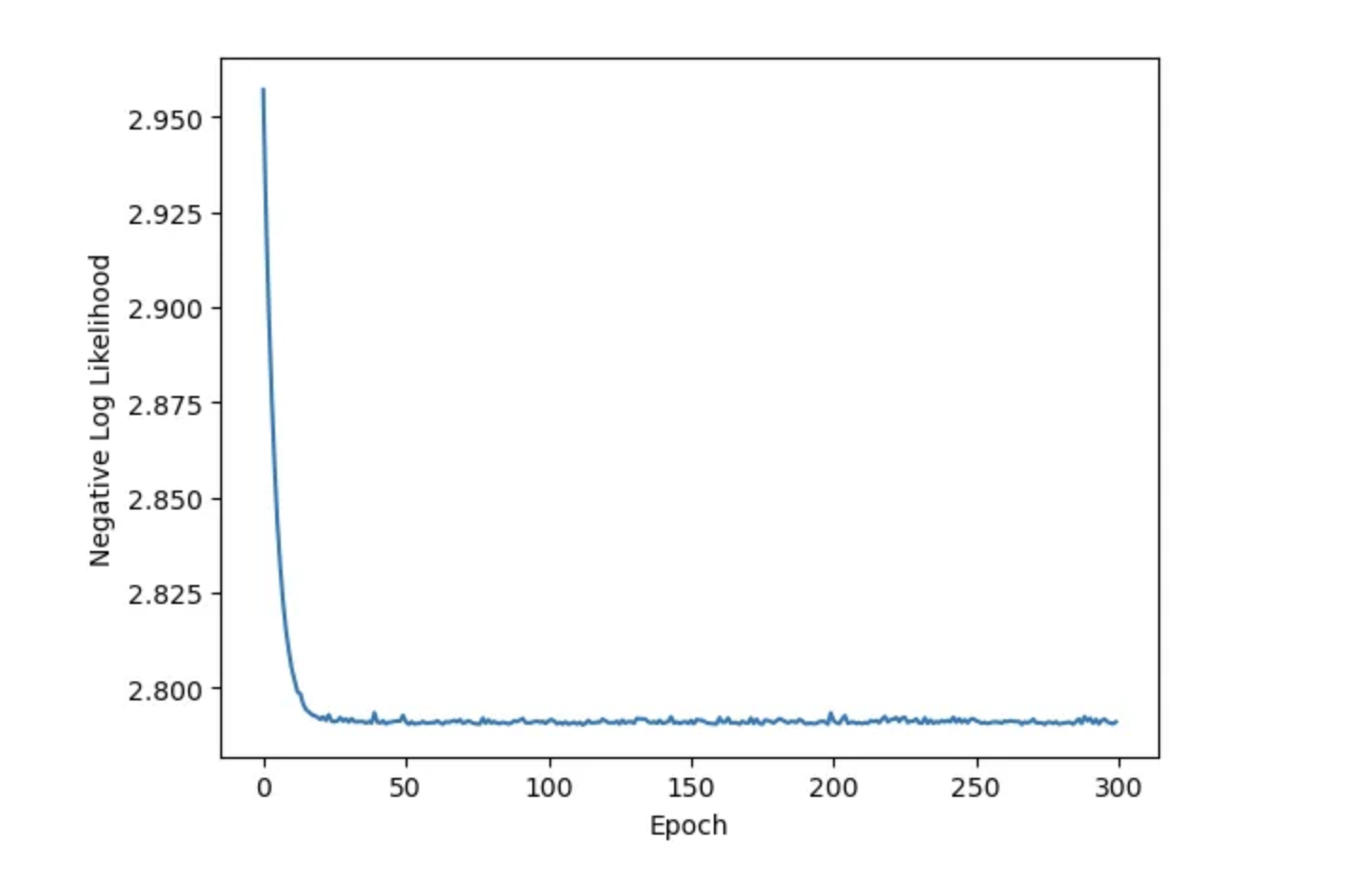
Puede comprobar que el modelo se ajusta bien al dataset:
plt.plot(hist[“tren_pérdida”])
plt.xlabel(“Época”)
plt.ylabel(“Probabilidad logarítmica negativa”)
plt.show(
Encontrar el surtido óptimo
Con las probabilidades de compra en la mano, ahora podemos estimar los ingresos medios por cliente de un surtido A utilizando la fórmula:
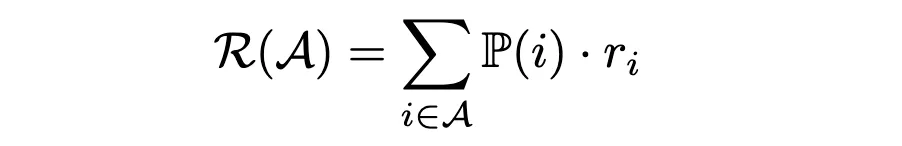
Para encontrar el surtido que maximice los ingresos, podríamos evaluar todas las combinaciones posibles y seleccionar la que tenga los ingresos medios más elevados. Sin embargo, un enfoque más eficiente es utilizar Programación lineal (PL). Aquí nos centraremos en cómo utilizar el elija-aprenda implementación del optimizador de surtido.
Es importante distinguir entre maximizar los ingresos y maximizar los márgenes de beneficio. Mientras que los ingresos son importantes, los márgenes de beneficio tienen en cuenta los costes asociados a cada producto. Dependiendo de su objetivo, es posible que desee optimizar los beneficios en lugar de los ingresos puros.
Para optimizar el surtido, necesitamos varios datos clave:
- El peso que queremos dar a cada categoría de edad, vamos con su cuota de clientes
- La utilidad de cada artículo (calculada por nuestro modelo de elección) para cada categoría de edad
- El valor a optimizar para cada elemento (en este caso, los ingresos)
- El tamaño del surtido (por ejemplo, 12 artículos)
Así es como funciona utilizando elija-aprenda:
de elección_aprendizaje.caja_herramientas.optimizador_surtido importar LatentClassAssortmentOptimizer
# Precio de cada artículo
precios_futuros = np.stack([artículos_características[-1]]*5, eje=0)
categoría_edad = np.eye(5).astype("float32")
# Calcule la utilidad de cada artículo dado su precio y cada categoría de edad
utilidades_predecidas = model.compute_batch_utility(shared_features_by_choice=categoría_edad,
items_features_by_choice=precios_futuros,
artículos_disponibles_por_elección=np.ones((5, 20)),
opciones=Ninguno
)
pesos_categoria_edad = np.suma(características_compartidas, eje=0) / len(características_compartidas)
opt = LatentClassAssortmentOptimizer(
solucionador="o-herramientas", # Solver a utilizar, ya sea "or-tools" o "gurobi" (si dispone de licencia)
class_weights=pesos_categoría_edad, # Pesos de cada clase
utilidades_clase=np.exp(utilidades_predecidas), Utilidades # en la forma (n_clases, n_artículos)
itemwise_values=precios_futuros[0][:, 0], # Valores a optimizar para cada artículo, aquí precio que se utiliza para calcular el volumen de negocios
tamaño_surtido=12) # Tamaño del surtido que deseamos
surtido, opt_obj = opt.resolver()Ejecutando el código debería tener algo como
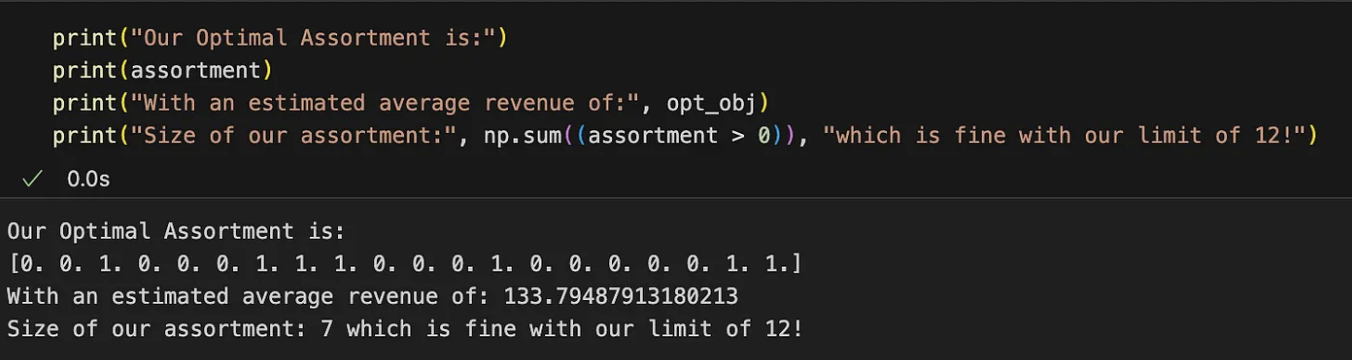
El surtido óptimo para maximizar los ingresos se indica con los índices de los valores 1 del vector. Este surtido produce teóricamente un ingreso medio por cliente de 134 yuanes. Puede explorar otras combinaciones, pero todas darán como resultado unos ingresos medios inferiores.
Otro objetivo podría ser maximizar el número de ventas. En este escenario, el valor por artículo para la optimización se fija en 1 para todos los artículos, lo que conduce a un surtido óptimo diferente.
La eficacia de este método se hace evidente cuando se introducen restricciones adicionales. Por ejemplo, puede que necesite tener en cuenta las limitaciones de espacio en las estanterías de su tienda. En este caso, puede optimizar un surtido cuyo tamaño total de artículos no supere el espacio disponible en las estanterías. Esta restricción adicional, junto con otras como las estrategias de precios, se demuestra aquí.
Conclusión
Si está trabajando en la optimización del surtido o en la fijación de precios, el modelado de elección es una gran herramienta, asegúrese de echarle un vistazo. Choice-Learn proporciona muchos ejemplos geniales en su GitHub. Compruébelo y deje una estrella si le resulta útil.
