

Autor

GLADS - 5 escolhas que o senhor precisa fazer antes de começar a modelar

TL;DR
A previsão de demanda é sempre desafiadora, todos nós sabemos disso. Nesta série de artigos, o senhor entenderá os principais desafios do desenvolvimento de um modelo de previsão complexo em um problema do mundo real. Nosso modelo deve superar as previsões de linha de base feitas pelos planejadores de demanda em termos de precisão de previsão e ser facilmente implantado em outros países. Primeiramente, gostaríamos de fornecer dicas úteis sobre as escolhas que o senhor deve fazer antes de treinar seu próprio modelo.
O que esperar dessa série?
Nosso objetivo é fornecer insights e boas práticas que vão além do que o senhor pode encontrar nas competições da Kaggle. O problema das competições de previsão on-line é que elas geralmente omitem restrições do mundo real, como data corrompido, data não disponível com antecedência etc.
Cada artigo desta série abordará um desafio que o senhor pode encontrar e para o qual não há respostas claras nas discussões da Kaggle:
A estrutura GLADS
A previsão de demanda tem sido uma ferramenta poderosa para ajudar as empresas na tomada de decisões, na otimização logística e no aprendizado de insights comerciais. No entanto, ainda é um desafio ter um modelo de previsão preciso e robusto, e as abordagens baseadas em aprendizado de máquina têm dificuldade de ser aplicadas em negócios reais devido a diferentes restrições. O desafio pode surgir tanto do lado da empresa quanto do lado do data. Para ajudar os proprietários de empresas e os cientistas do data a superar essas dificuldades, resumimos cinco escolhas que os senhores precisam fazer com base em nossa experiência. Chamamos isso de GLADS, que significa:
No trecho, explicaremos brevemente o que, por que e como escolhemos o GLADS.
G: Granularidade do data
O que é isso?
A granularidade do data é o grau de detalhamento de sua descrição de vendas. Geralmente, ela vem em duas dimensões: itens e tempo (frequência). Por exemplo, o senhor descreve suas vendas por SKU / categoria / BU / país? O senhor registra suas vendas por hora / dia / semana / mês / ano?
Por que isso é importante?
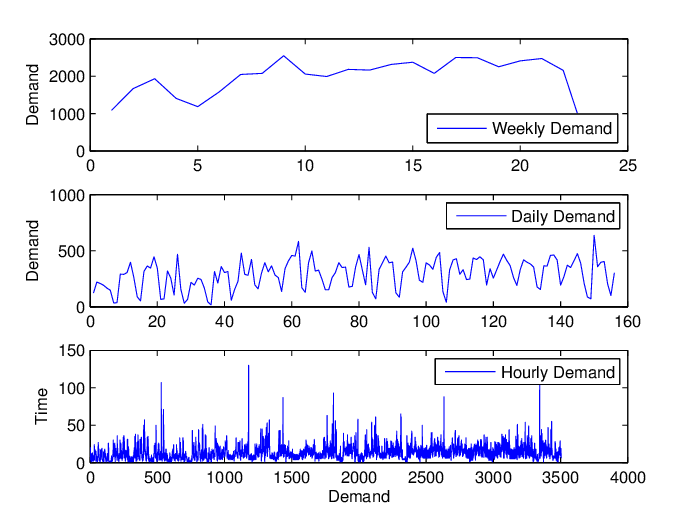
Embora quanto mais detalhado for o data bruto, mais opções o cientista do Data poderá utilizar para a previsão de vendas, a escolha da granularidade não é tão simples. Aparentemente, uma granularidade maior pode manter mais informações ao descrever as vendas, mas também pode gerar uma grande quantidade de ruído no data. A escolha da granularidade correta é uma etapa necessária para eliminar o ruído do data e manter o máximo de informações possível, o que pode criar uma base sólida para as próximas etapas de modelagem.
Como escolher?
A granularidade deve ser escolhida levando-se em conta dois fatores principais: a necessidade comercial e as próprias características do data.
Com base em suas necessidades comerciais: A necessidade do negócio é sempre a primeira coisa que deve ser levada em consideração. Em alguns casos, as vendas mensais seriam suficientes, enquanto em outros casos, o senhor pode ser solicitado a prever as vendas para cada hora. A necessidade comercial varia muito em diferentes setores e o senhor deve começar a criar o modelo depois de entendê-la primeiro.
Baseado nas características do data: Se a granularidade do data entrar em conflito com a necessidade comercial, a primeira ideia que o senhor tiver em mente deverá ser coletar o data de outra forma. Embora alguns algoritmos possam ajudá-lo a elevar a granularidade do seu data por meio de simulação ou aprendizado de máquina, a criação de um modelo usando pseudo-data traz muita incerteza. No entanto, agregar o data a uma granularidade menor às vezes é necessário. Nesses casos, o data é muito instável, com alta variação. A agregação do data pode ser uma ferramenta útil para estabilizar o data e aumentar o desempenho do seu modelo.
L: Comprimento do horizonte
O que é isso?
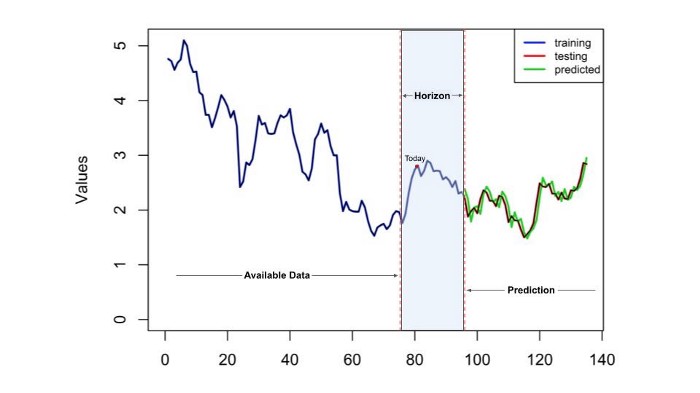
O horizonte de tempo de seu modelo de previsão é basicamente quanto tempo no futuro a previsão deve ser realizada. Se prepararmos uma previsão com o horizonte de tempo de dois meses, isso significa que nosso modelo forneceria o resultado previsto dois meses a partir do momento atual com uma determinada granularidade.
Por que isso é importante?
Embora a precisão do modelo seja frequentemente usada como a única métrica de desempenho na avaliação de um modelo de previsão, o horizonte de tempo pode ser essencial na aplicação do modelo no mundo real. Assim como na previsão do tempo, sempre é possível obter uma precisão melhor ao prever a temperatura nas próximas horas do que uma semana depois. É o mesmo caso quando se trata de previsão de vendas: quanto mais longo for o horizonte, menor será a precisão. No entanto, para aplicativos comerciais, seria o contrário. Normalmente, não há necessidade de prever as vendas do dia seguinte, pois poucas decisões podem ser tomadas e executadas durante a noite, mas pode ser muito útil saber o que acontecerá nas semanas ou meses seguintes. Não seja cego sem ter um horizonte de tempo em mente e crie um modelo que não possa ser aplicado no mundo real.
Como escolher?
A duração do horizonte de tempo dependerá totalmente das necessidades do negócio. Por exemplo, se a previsão for usada para ajudar a otimizar a programação do depósito, a previsão de vendas para o dia seguinte pode não ser útil. Portanto, o horizonte de previsão deve ser definido com base no tempo que leva desde o conhecimento do futuro até a aplicação efetiva da ação. Ou, para ser mais franco: quanto o senhor deve conhecer os números com antecedência? Como lembrete, um horizonte muito longo pode diminuir a quantidade de amostras de treinamento que o senhor tem se a cobertura de tempo do data não for suficientemente longa.
A: Algoritmo para previsão
O que é isso?
As abordagens de previsão de vendas vêm evoluindo há anos, o que explica a diversidade dos algoritmos. Embora as ferramentas mais populares quando se fala em previsão de vendas sejam o ARIMA do statsmodel e o Prophet, os modelos de regressão baseados em árvores também têm sido aplicados em tarefas de previsão de vendas. Enquanto isso, as redes neurais profundas nunca estiveram fora da lista de candidatos sempre que o aprendizado de máquina é aplicado.
Por que isso é importante?
Talvez não seja tarefa de um cientista de Data desenvolver um algoritmo totalmente novo para uma tarefa especial; o principal desafio para eles hoje em dia é escolher o algoritmo certo e o processamento data personalizado para o algoritmo. A escolha de um algoritmo sem levar em conta o data disponível, o contexto comercial ou os requisitos de transparência do modelo provavelmente transformaria o modelo em toneladas de parâmetros que ficam no servidor sem nenhuma aplicação adequada.
Como escolher?
Antes de escolher o melhor algoritmo para o seu caso, aqui estão alguns conceitos gerais que devem ser conhecidos para cada ramo do algoritmo.
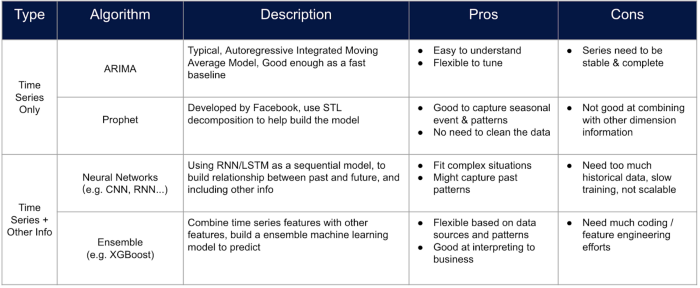
ARIMA: O ARIMA é usado para criar um modelo para uma série temporal usando métodos estatísticos puramente clássicos, sem outros recursos que possam representar as características do sku.
Profeta: O Prophet é uma ferramenta de previsão avançada projetada pelo Facebook, que pode personalizar os eventos e os festivais; no entanto, nenhum recurso estático pode ser adicionado.
Tanto o ARIMA quanto o Prophet não podem criar um modelo para várias séries temporais e o erro será acumulado à medida que o horizonte aumentar.
Modelos baseados em árvores: Os modelos baseados em árvores são geralmente usados para problemas de classificação e regressão, mas também podem ser usados para previsão de séries temporais por meio de alguns truques especiais de processamento data. É possível criar uma tabela em que cada recurso representa os valores da série em um registro de data e hora específico, e a previsão pode ser feita rolando o tempo de previsão com a janela de tempo. Os modelos de conjunto baseados em árvore são agora uma das maneiras mais eficientes de criar um modelo de previsão de vendas, pois é possível personalizar mais recursos no modelo sem muito trabalho na engenharia de recursos.
Rede neural: Os métodos de rede neural nunca estão fora de moda devido ao seu desempenho. Sempre é possível criar uma rede neural como a LSTM com processos semelhantes de engenharia de recursos com modelos baseados em árvores. No entanto, a transparência do modelo, a quantidade de data necessária e a eficiência do treinamento devem sempre ser estimadas antes da aplicação dessas abordagens.
D: Impulsionadores de vendas
O que é isso?
É de conhecimento comum nos negócios que as vendas de um item podem ser extremamente influenciadas por outros fatores (feriados, eventos, campanhas, mídia, clima etc.). Quando o senhor consegue detectar esses fatores, pode ter uma chance melhor de melhorar a previsão com o driver data, especialmente quando alguns dos fatores podem ser conhecidos ou definidos antes da previsão.
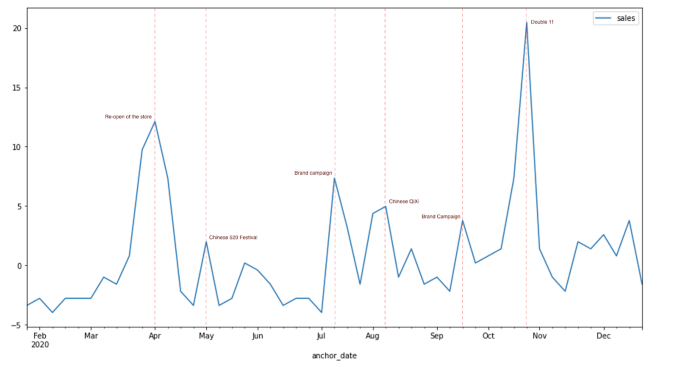
Por que isso é importante?
Os modelos de previsão de vendas dificilmente podem alcançar um desempenho satisfatório se usarem apenas o histórico de vendas, pois o comportamento dos clientes pode ser influenciado por muitos fatores. As vendas de um supermercado podem ser influenciadas pelo clima, e as vendas de uma marca de cosméticos podem ser puxadas pelas campanhas. Com base em nossa experiência, o impacto de diferentes fatores pode ser tão forte que as vendas às vezes dobram durante a temporada de festas, o que pode causar erros enormes na previsão do modelo. No entanto, analisar o impacto dos drivers é sempre um tópico interessante para os profissionais de marketing e para o departamento de logística. Como as vendas mudariam se uma grande campanha fosse programada no futuro? E como otimizar a logística em diferentes cenários?
Como escolher?
Transformação em séries temporais: Dado o data relacionado a possíveis drivers, a primeira coisa que precisamos fazer é transformar esses data em séries temporais para que possamos analisar a correlação entre o driver e as vendas de uma sku. No entanto, isso pode ser realmente complicado. A maneira mais fácil é codificar um grupo de eventos como uma variável binária que indica se pelo menos um desses eventos ocorre durante um determinado período de tempo. Com base nisso, os eventos também podem ser codificados como uma sequência numérica de tempo. Por exemplo, o número de eventos no mesmo dia, o número de cidades onde os eventos ocorreram naquele dia etc. Algumas transformações personalizadas também podem ser adicionadas, como o uso de outras formas de ondas em vez de ondas quadradas, de acordo com a experiência comercial.
Estudo de correlação: Em seguida, precisamos estudar a correlação entre duas séries temporais. Sugerimos o uso de TLCC (Time Lagged Cross Correlation, correlação cruzada defasada no tempo), pois o efeito de um evento pode aparecer antes ou depois do evento. Por exemplo, as campanhas geralmente entram em vigor vários dias após o lançamento, enquanto as pessoas tendem a preparar o presente uma semana antes do festival. Como resultado, a compensação pode ser positiva ou negativa, enquanto os valores absolutos precisam ser limitados com base na experiência comercial, caso contrário, seria muito difícil explicar por que as vendas de hoje são afetadas pelo Natal de 2018.
S: Conjuntos de SKUs
O que é isso?
Na maioria das vezes, as vendas data são reunidas por SKU (Stock keeping unit), portanto, uma questão importante ao criar um modelo de previsão no nível de SKU é se o senhor deve treinar um modelo individual para cada SKU ou usar todas as SKUs disponíveis para treinar um modelo. Enquanto o primeiro se concentra em uma única SKU e diferencia suas características, o segundo se beneficia do enorme volume do data de treinamento e economiza espaço para armazenar os parâmetros dos modelos.
Por que isso é importante?
O motivo pelo qual podemos treinar o modelo com todas as SKUs é que a maioria dos sinais aprendidos pelo modelo é semelhante; portanto, se conseguirmos maximizar a semelhança entre os data que usamos para treinamento, poderemos otimizar a compensação entre o respeito à particularidade de cada sku e o volume do data de treinamento.
Como escolher?
Com base nessa suposição, sugerimos dois métodos diferentes para agrupar as SKUs.
Forma de negócio: Como as vendas de uma categoria podem ser semelhantes, agrupar as SKUs por suas categorias seria uma maneira prática de se beneficiar dos padrões comuns entre determinadas SKUs. Às vezes, há até subcategorias que o senhor pode aproveitar para encontrar o melhor corte de SKU.
Data science way: Uma maneira científica de agrupar as SKUs é aplicar algoritmos de agrupamento. Na seção anterior, mencionamos a análise da correlação entre SKUs e motoristas, e podemos utilizar o mesmo método para calcular a correlação entre as SKUs. Na verdade, a correlação pode ser considerada como distância, e os algoritmos de agrupamento podem ser aplicados à matriz de distância em todos os pares de SKUs e, em seguida, o modelo pode ser treinado individualmente em cada um desses agrupamentos.
Conclusão
Para concluir, aqui está uma versão resumida do “GLADS” que o senhor deve ter em mente ao fazer escolhas de previsão:
No final das contas, essas opções só poderiam ajudar o senhor a ter uma boa vantagem no início de um projeto de previsão ou ajudar a ajustar a metodologia ao longo do caminho. Mas o diabo está nos detalhes, e postaremos mais tarde sobre uma metodologia mais detalhada relacionada a esse tópico. Afinal de contas, não há um fim para a previsão, sempre há a necessidade de melhorar.
