

Autor

GLADS - 5 decisiones que debe tomar antes de empezar a modelar

TL;DR
La previsión de la demanda es siempre un reto, todos lo sabemos. En esta serie de artículos comprenderá los principales retos de desarrollar un modelo de previsión complejo sobre un problema del mundo real. Nuestro modelo tiene que superar a las predicciones de referencia realizadas por los planificadores de la demanda en términos de precisión de las previsiones y ser fácilmente desplegable en otros países. En primer lugar, nos gustaría proporcionarle consejos útiles sobre las decisiones que debe tomar, antes de entrenar su propio modelo.
¿Qué esperar de esta serie?
Nuestro objetivo es proporcionarle ideas y buenas prácticas que vayan más allá de lo que pueda encontrar en las competiciones de Kaggle. El problema de los concursos de previsión en línea es que a menudo omiten limitaciones del mundo real como data corruptos, data no disponibles con antelación, etc.
Cada artículo de esta serie abordará un reto con el que podría encontrarse y para el que no existen respuestas claras en los debates de Kaggle:
El marco GLADS
La previsión de la demanda ha sido una poderosa herramienta para ayudar a las empresas en la toma de decisiones, la optimización logística y el aprendizaje de conocimientos empresariales. Sin embargo, sigue siendo un reto disponer de un modelo de previsión preciso y robusto, los enfoques basados en el aprendizaje automático luchan por aplicarse en el negocio real debido a diferentes limitaciones. El reto puede surgir tanto del lado de la empresa como del lado del data. Para ayudar a los empresarios y a los científicos de data a superar estas dificultades, hemos resumido cinco opciones que debe tomar basándonos en nuestra experiencia. Lo llamamos GLADS, que significa:
En el pasaje explicaremos brevemente qué, por qué y cómo elegimos GLADS.
G: Granularidad de data
¿De qué se trata?
La granularidad de data es lo detallada que será su descripción de ventas. Suele tener dos dimensiones: artículos y tiempo (frecuencia). Por ejemplo, ¿describe sus ventas por SKU / categoría / BU / País? ¿Describe sus ventas por hora / día / semana / mes / año?
¿Por qué es importante?
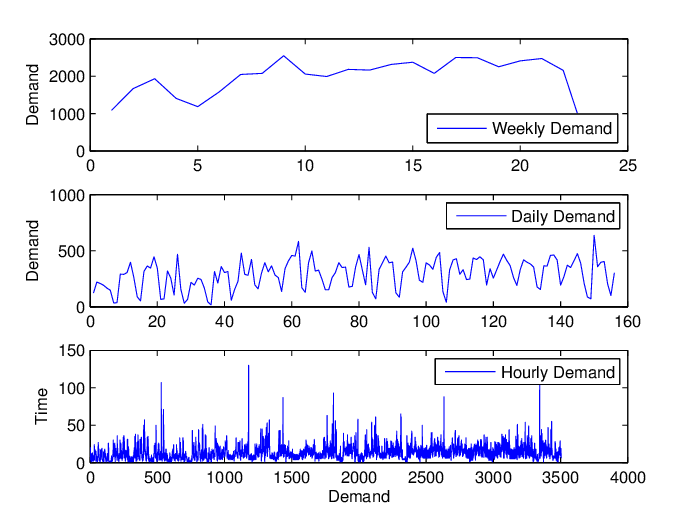
Aunque cuanto más detallada sea la data bruta, más opciones tendrá el científico de la Data para realizar previsiones de ventas, la elección de la granularidad no es tan sencilla. Aparentemente, una mayor granularidad puede guardar más información a la hora de describir las ventas, sin embargo, también puede aportar una gran cantidad de ruido al data. Elegir la granularidad adecuada es un paso necesario para desdenoizar el data y conservar la mayor cantidad de información posible, lo que puede construir una base sólida para los siguientes pasos de modelización.
¿Cómo elegir?
La granularidad debe elegirse teniendo en cuenta dos factores principales: la necesidad empresarial y las propias características del data.
En función de sus necesidades empresariales: La necesidad empresarial es siempre lo primero que debe tenerse en cuenta. En algunos casos, las ventas mensuales serían suficientes, mientras que en otros casos, puede que se le pida que prediga las ventas de cada hora. La necesidad empresarial varía mucho en los distintos sectores, y asegúrese de empezar a construir el modelo después de comprenderla primero.
Basado en las características del data: No se pueden hacer ladrillos sin paja, si la granularidad de la data entra en conflicto con la necesidad empresarial, la primera idea que se le ocurra debe ser recoger la data de otra manera. Aunque algunos algoritmos pueden ayudarle a elevar la granularidad de su data mediante simulación o aprendizaje automático, construir un modelo utilizando pseudo-data le aporta demasiada incertidumbre. Sin embargo, a veces es necesario agregar los data a una granularidad inferior, en estos casos, los data son demasiado inestables con una varianza elevada, la agregación de data puede ser una herramienta útil para estabilizar los data y aumentar el rendimiento de su modelo.
L: Longitud del horizonte
¿De qué se trata?
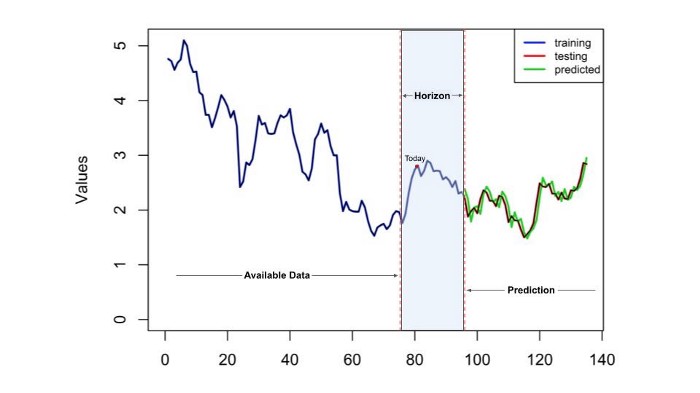
El horizonte temporal de su modelo de previsión es básicamente cuánto tiempo en el futuro debe realizar la predicción. Si preparamos una previsión con un horizonte temporal de dos meses, significa que nuestro modelo daría el resultado previsto a dos meses vista con una granularidad determinada.
¿Por qué es importante?
Aunque la precisión del modelo suele utilizarse como única métrica de rendimiento al evaluar un modelo de previsión, el horizonte temporal puede ser esencial a la hora de aplicar el modelo en el mundo real. Al igual que ocurre con la previsión meteorológica, siempre se puede alcanzar una mayor precisión al predecir la temperatura de las próximas horas que la de una semana después. Es el mismo caso cuando se trata de la previsión de ventas, cuanto más largo sea el horizonte, menor sería la precisión. Sin embargo, para las aplicaciones empresariales, sería lo contrario. Normalmente, no hay necesidad de predecir las ventas del día siguiente, ya que pocas decisiones pueden tomarse y ejecutarse durante la noche, mientras que podría ser muy útil saber qué ocurrirá en las semanas o meses siguientes. No se ciegue sin tener un horizonte temporal en mente y construya un modelo que no pueda aplicarse en el mundo real.
¿Cómo elegir?
La longitud del horizonte temporal dependerá totalmente de las necesidades empresariales. Por ejemplo, si la previsión se va a utilizar con el fin de ayudar a optimizar la programación del almacén,entonces prever las ventas para el día siguiente podría no ser de ayuda. Así pues, el horizonte de previsión debe fijarse en función del tiempo que transcurra desde que se conoce el futuro hasta que se aplica realmente la acción. O para decirlo más francamente: ¿cuánto tiempo debería conocer los números de antemano? Como recordatorio, un horizonte demasiado largo puede disminuir la cantidad de muestras de entrenamiento de que disponga si la cobertura temporal del data no es lo suficientemente larga.
A: Algoritmo de predicción
¿De qué se trata?
Los enfoques de previsión de ventas llevan años evolucionando, de ahí la diversidad de los algoritmos. Aunque las herramientas más populares cuando se habla de previsión de ventas son ARIMA de statsmodel y Prophet, los modelos de regresión basados en árboles también se han aplicado en tareas de previsión de ventas. Mientras tanto, las redes neuronales profundas nunca han estado fuera de la lista de candidatos siempre que se aplica el aprendizaje automático.
¿Por qué es importante?
Puede que el trabajo de un científico Data no sea desarrollar un algoritmo completamente nuevo para una tarea especial, el principal reto para ellos hoy en día consiste en elegir el algoritmo adecuado y el procesamiento data personalizado para el algoritmo. Elegir un algoritmo sin tener en cuenta el data disponible, el contexto empresarial o los requisitos sobre la transparencia del modelo probablemente convertiría el modelo en toneladas de parámetros que se quedarían en el servidor sin una aplicación adecuada.
¿Cómo elegir?
Antes de elegir el mejor algoritmo en su caso, he aquí algunos conceptos generales que deben conocerse para cada rama del algoritmo.
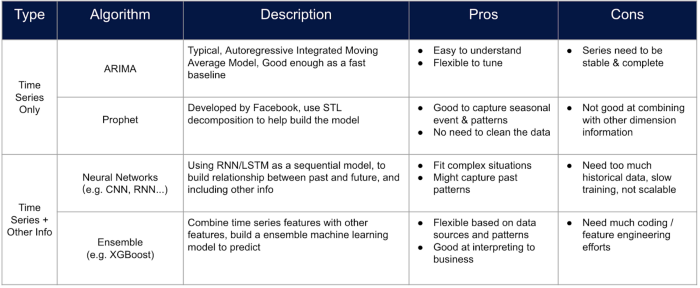
ARIMA: ARIMA se utiliza para construir un modelo para una serie temporal utilizando métodos estadísticos puramente clásicos sin otras características que puedan representar las características de la sku.
Profeta: Prophet es una herramienta de previsión avanzada diseñada por Facebook, que puede personalizar los eventos y los festivales, aunque no se pueden añadir funciones estáticas.
Tanto ARIMA como Prophet no pueden construir un modelo para series temporales múltiples y el error se apilará a medida que aumente el horizonte.
Modelos basados en árboles: Los modelos basados en árboles se utilizan a menudo para problemas de clasificación y regresión, sin embargo, también pueden utilizarse para la previsión de series temporales mediante algunos trucos especiales de procesamiento data. Se puede construir una tabla en la que cada característica represente los valores de la serie en la marca de tiempo específica, y la previsión se puede realizar haciendo rodar el tiempo de predicción con la ventana de tiempo. Los modelos de conjunto basados en árboles son ahora una de las formas más eficientes a la hora de construir un modelo de previsión de ventas, ya que uno puede personalizar más características en el modelo sin demasiado trabajo de ingeniería de características.
Red neuronal: Los métodos de redes neuronales nunca pasan de moda por su rendimiento. Siempre se puede construir una red neuronal como la LSTM con procesos de ingeniería de características similares a los modelos basados en árboles. Sin embargo, la transparencia del modelo, la cantidad de data necesaria y la eficacia del entrenamiento deben estimarse siempre antes de aplicar tales enfoques.
D: Impulsores de las ventas
¿De qué se trata?
Es un conocimiento común en los negocios, que las ventas de un artículo pueden estar enormemente influenciadas por otros factores (vacaciones, eventos, campañas, medios de comunicación, clima, etc.). Si es capaz de detectar estos factores, tendrá más posibilidades de mejorar la previsión con el controlador data, especialmente cuando algunos de los factores pueden conocerse o fijarse antes de la previsión.
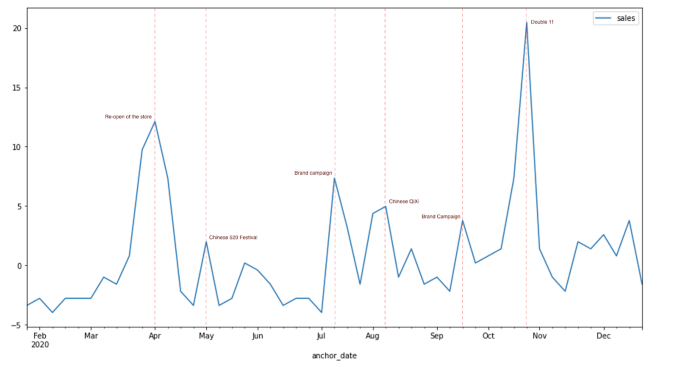
¿Por qué es importante?
Los modelos de previsión de ventas difícilmente pueden lograr un rendimiento satisfactorio si sólo utilizan el historial de ventas porque el comportamiento de los clientes puede verse influido por demasiados factores. Las ventas de un supermercado pueden verse influidas por el tiempo, y las ventas de una marca de cosméticos pueden verse arrastradas por las campañas. Basándonos en nuestra experiencia, el impacto de los diferentes impulsores puede ser tan fuerte que las ventas a veces se duplican durante la temporada festiva y puede causar enormes errores en la predicción del modelo. No obstante, analizar el impacto de los impulsores es siempre un tema interesante tanto para los responsables de marketing como para el departamento de logística, ¿cuáles son los factores clave que dominan las ventas? ¿Cómo cambiarían las ventas si se programara una gran campaña en el futuro? ¿Y cómo optimizar la logística en diferentes escenarios?
¿Cómo elegir?
Transformación a series temporales: Dados los data relacionados con los controladores potenciales, lo primero que tenemos que hacer es transformar estos data en series temporales para poder analizar la correlación entre el controlador y las ventas de un sku. Sin embargo, esto puede ser realmente complicado. La forma más sencilla es codificar un grupo de eventos como una variable binaria que indique si al menos uno de estos eventos se produce durante un determinado periodo de tiempo. A partir de ahí, los eventos también pueden codificarse como una secuencia temporal numérica. Por ejemplo, el número de acontecimientos del mismo día, el número de ciudades en las que se produjeron los acontecimientos ese día, etc. También se pueden añadir algunas transformaciones personalizadas, como utilizar otras formas de ondas en lugar de ondas cuadradas según la experiencia empresarial.
Estudio de correlación: A continuación, debemos estudiar la correlación entre dos series temporales. Sugerimos utilizar la TLCC (Correlación cruzada retardada en el tiempo) ya que el efecto de un acontecimiento puede aparecer antes o después del mismo. Por ejemplo, las campañas suelen surtir efecto varios días después del lanzamiento, mientras que la gente tiende a preparar el regalo una semana antes de la fiesta. Como resultado, el desfase puede ser positivo o negativo, mientras que los valores absolutos deben limitarse en función de la experiencia comercial, ya que de lo contrario sería demasiado difícil explicar por qué las ventas de hoy se ven afectadas por la Navidad de 2018.
S: Conjuntos de SKU
¿De qué se trata?
La mayoría de las veces, las ventas data se recogen por SKU (Stock keeping unit), por lo que una cuestión importante a la hora de construir un modelo de previsión a nivel de SKU es si entrenar un modelo individual para cada SKU o utilizar todas las SKU disponibles para entrenar un modelo. Mientras que el primero se centra en una única SKU y diferencia las características de la misma, el segundo se beneficia del enorme volumen de las data de entrenamiento y ahorra espacio para almacenar los parámetros de los modelos.
¿Por qué es importante?
La razón por la que podemos entrenar el modelo con todas las SKU es que la mayoría de las señales aprendidas por el modelo son similares, por lo tanto, si somos capaces de maximizar la similitud entre las data que utilizamos para el entrenamiento, podremos optimizar el compromiso entre el respeto de la particularidad de cada sku y el volumen de las data de entrenamiento.
¿Cómo elegir?
Basándonos en esa suposición, sugerimos dos métodos diferentes para agrupar las SKU.
Vía empresarial: Dado que las ventas de una categoría pueden ser similares, agrupar las SKU por sus categorías sería una forma práctica de beneficiarse de los patrones comunes entre determinadas SKU. A veces hay incluso subcategorías que puede aprovechar para encontrar el mejor corte de SKU.
Data vía científica: Una forma data científica de agrupar las SKU es aplicar algoritmos de agrupación. En la sección anterior, hemos mencionado el análisis de la correlación entre SKU y conductores, podemos utilizar el mismo método para calcular la correlación a través de las SKU. De hecho, la correlación puede considerarse como una distancia, los algoritmos de agrupación pueden aplicarse así a la matriz de distancias a través de todos los pares de SKU, entonces el modelo puede entrenarse individualmente en cada uno de estos clusters.
Conclusión
A modo de conclusión, he aquí una versión abreviada de “GLADS” para que la tenga en cuenta a la hora de tomar decisiones de previsión:
A fin de cuentas, estas opciones sólo podrían ayudarle a tener una buena ventaja al principio de un proyecto de previsión, o a afinar la metodología por el camino. Pero el diablo está en los detalles, y más adelante publicaremos un post sobre metodología más detallado relacionado con este tema. Al fin y al cabo, en la previsión no hay final, siempre existe la necesidad de hacerlo mejor.
