

Autor

GLADS - 5 Entscheidungen, die Sie treffen müssen, bevor Sie mit dem Modeln beginnen

TL;DR
Nachfrageprognosen sind immer eine Herausforderung, das wissen wir alle. In dieser Artikelserie werden Sie die wichtigsten Herausforderungen bei der Entwicklung eines komplexen Prognosemodells für ein reales Problem verstehen. Unser Modell muss die Basisprognosen der Nachfrageplaner in Bezug auf die Prognosegenauigkeit übertreffen und problemlos in anderen Ländern eingesetzt werden können. Zunächst möchten wir Ihnen nützliche Tipps zu den Entscheidungen geben, die Sie treffen sollten, bevor Sie Ihr eigenes Modell trainieren.
Was ist von dieser Serie zu erwarten?
Wir möchten Ihnen Einblicke und bewährte Verfahren bieten, die über das hinausgehen, was Sie bei Kaggle-Wettbewerben finden können. Das Problem mit Online-Prognosewettbewerben ist, dass sie oft reale Einschränkungen wie beschädigte data, data, die nicht im Voraus verfügbar sind, usw. auslassen.
Jeder Artikel in dieser Serie wird sich mit einer Herausforderung befassen, auf die Sie stoßen könnten und für die es in den Kaggle-Diskussionen keine klaren Antworten gibt:
Der GLADS-Rahmen
Die Nachfrageprognose ist ein leistungsfähiges Instrument, das Unternehmen bei der Entscheidungsfindung, der logistischen Optimierung und der Gewinnung von Geschäftserkenntnissen hilft. Es ist jedoch nach wie vor eine Herausforderung, ein genaues und robustes Prognosemodell zu erstellen. Auf maschinellem Lernen basierende Ansätze lassen sich aufgrund verschiedener Einschränkungen nur schwer auf reale Unternehmen anwenden. Die Herausforderung kann sowohl von der Unternehmensseite als auch von der data-Seite ausgehen. Um Unternehmern und data-Wissenschaftlern bei der Überwindung dieser Schwierigkeiten zu helfen, haben wir auf der Grundlage unserer Erfahrungen fünf Entscheidungen zusammengefasst, die Sie treffen müssen. Wir nennen sie GLADS, das steht für:
In diesem Abschnitt werden wir kurz erklären, was, warum und wie wir uns für GLADS entschieden haben.
G: Granularität von data
Was ist das?
Die Granularität von data gibt an, wie detailliert Ihre Verkaufsbeschreibung sein wird. Sie umfasst normalerweise zwei Dimensionen: Artikel und Zeit (Häufigkeit). Beschreiben Sie zum Beispiel Ihre Verkäufe nach SKU / Kategorie / BU / Land? Erfassen Sie Ihre Verkäufe nach Stunde / Tag / Woche / Monat / Jahr?
Warum ist das wichtig?
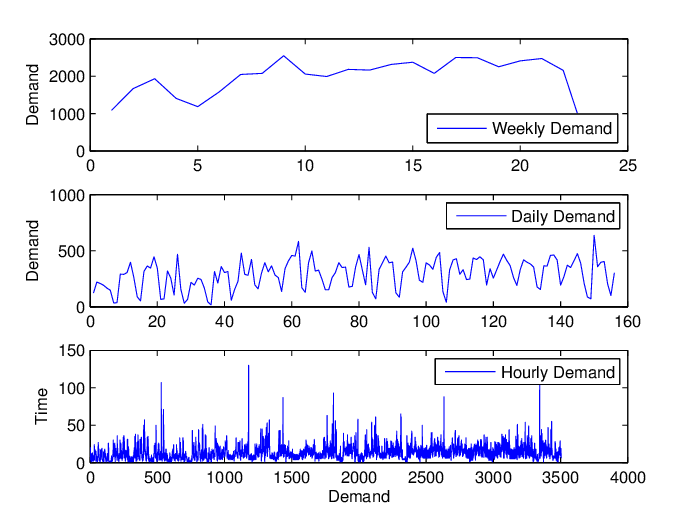
Je detaillierter die data-Rohdaten sind, desto mehr Optionen stehen dem Data-Wissenschaftler für die Absatzprognose zur Verfügung, aber die Wahl der Granularität ist nicht so einfach. Offensichtlich kann eine höhere Granularität mehr Informationen bei der Beschreibung der Verkäufe enthalten, sie kann aber auch eine große Menge an Rauschen in die data bringen. Die Wahl der richtigen Granularität ist ein notwendiger Schritt, um das data zu entrauschen und so viele Informationen wie möglich zu erhalten, die eine solide Grundlage für die nächsten Modellierungsschritte bilden können.
Wie wählen Sie?
Bei der Wahl der Granularität sollten Sie zwei Hauptfaktoren berücksichtigen: den Geschäftsbedarf und die data-Merkmale selbst.
Basierend auf Ihrem Geschäftsbedarf: Der geschäftliche Bedarf ist immer der erste Punkt, der berücksichtigt werden sollte. In manchen Fällen reichen monatliche Umsätze aus, während Sie in anderen Fällen vielleicht gebeten werden, die Umsätze für jede einzelne Stunde vorherzusagen. Die geschäftlichen Erfordernisse sind in den verschiedenen Branchen sehr unterschiedlich, und bitte stellen Sie sicher, dass Sie mit der Erstellung des Modells erst beginnen, wenn Sie diese verstanden haben.
Basierend auf den Eigenschaften des data: Wenn die Granularität des data nicht mit den geschäftlichen Anforderungen übereinstimmt, sollte die erste Idee, die Ihnen in den Sinn kommt, darin bestehen, das data auf andere Weise zu sammeln. Obwohl einige Algorithmen Ihnen helfen können, die Granularität Ihrer data durch Simulation oder maschinelles Lernen zu erhöhen, bringt die Erstellung eines Modells mit Pseudo-data zu viel Unsicherheit mit sich. Dennoch ist es manchmal notwendig, die data auf eine niedrigere Granularität zu aggregieren. In diesen Fällen sind die data zu instabil und weisen eine hohe Varianz auf, so dass die data-Aggregation ein nützliches Instrument sein kann, um die data zu stabilisieren und die Leistung Ihres Modells zu erhöhen.
L: Länge des Horizonts
Was ist das?
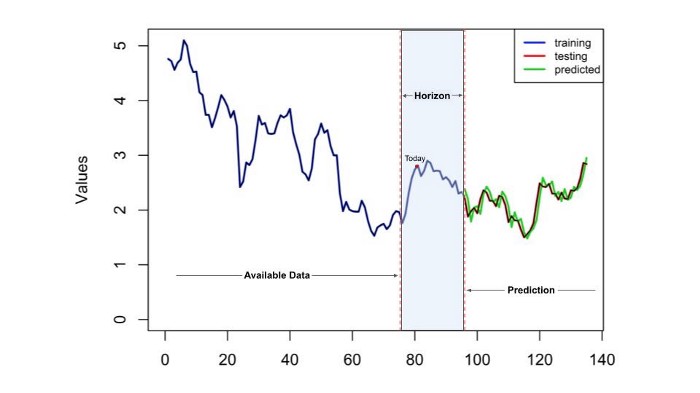
Der Zeithorizont Ihres Prognosemodells gibt im Grunde an, wie lange in der Zukunft die Vorhersage erfolgen soll. Wenn wir eine Prognose mit einem Zeithorizont von zwei Monaten erstellen, dann bedeutet dies, dass unser Modell das vorhergesagte Ergebnis zwei Monate nach dem aktuellen Zeitpunkt mit einer bestimmten Granularität liefern würde.
Warum ist das wichtig?
Während die Genauigkeit des Modells bei der Bewertung eines Prognosemodells oft als einziger Leistungsmaßstab herangezogen wird, kann der Zeithorizont bei der Anwendung des Modells in der realen Welt entscheidend sein. Genau wie bei der Wettervorhersage kann man immer eine bessere Genauigkeit erreichen, wenn man die Temperatur in den nächsten Stunden vorhersagt, als die in einer Woche danach. Das Gleiche gilt für Umsatzprognosen: Je länger der Zeithorizont ist, desto geringer ist die Genauigkeit. Bei Geschäftsanwendungen ist es jedoch genau umgekehrt. Normalerweise ist es nicht nötig, die Umsätze des nächsten Tages vorherzusagen, da nur wenige Entscheidungen in der Nacht getroffen und ausgeführt werden können, während es sehr hilfreich sein kann zu wissen, was in den nächsten Wochen oder Monaten passieren wird. Seien Sie nicht blind, ohne einen Zeithorizont im Kopf zu haben, und bauen Sie ein Modell, das in der realen Welt nicht anwendbar ist.
Wie soll ich wählen?
Die Länge des Zeithorizonts hängt ganz von den geschäftlichen Anforderungen ab. Wenn die Prognose z.B. dazu dienen soll, die Lagerplanung zu optimieren, dann ist die Vorhersage der Verkäufe für den nächsten Tag möglicherweise nicht hilfreich. Der Prognosehorizont sollte also danach festgelegt werden, wie lange es dauert, bis die Zukunft bekannt ist und die Maßnahme tatsächlich umgesetzt wird. Oder um es offener zu sagen: Wie weit sollten Sie die Zahlen im Voraus kennen? Zur Erinnerung: Ein zu langer Prognosehorizont kann dazu führen, dass Sie weniger Trainingsmuster haben, wenn die Zeitabdeckung des data nicht lang genug ist.
A: Algorithmus für die Vorhersage
Was ist das?
Die Ansätze zur Absatzprognose haben sich seit Jahren weiterentwickelt, daher auch die Vielfalt der Algorithmen. Die beliebtesten Tools für die Absatzprognose sind ARIMA von Statsmodel und Prophet, aber auch baumbasierte Regressionsmodelle werden für Absatzprognosen verwendet. In der Zwischenzeit sind tiefe neuronale Netze nie aus der Liste der Kandidaten gestrichen worden, wenn es um maschinelles Lernen geht.
Warum ist das wichtig?
Es mag nicht die Aufgabe eines Data-Wissenschaftlers sein, einen brandneuen Algorithmus für eine spezielle Aufgabe zu entwickeln. Die größte Herausforderung für sie besteht heutzutage darin, den richtigen Algorithmus und die maßgeschneiderte data-Verarbeitung für den Algorithmus auszuwählen. Die Wahl eines Algorithmus ohne Berücksichtigung der verfügbaren data, des geschäftlichen Kontextes oder der Anforderungen an die Transparenz des Modells würde das Modell wahrscheinlich in eine Unmenge von Parametern verwandeln, die auf dem Server verbleiben, ohne dass sie richtig angewendet werden.
Wie wählen Sie?
Bevor Sie den besten Algorithmus für Ihren Fall auswählen, sollten Sie einige allgemeine Konzepte für jeden Zweig des Algorithmus kennen.
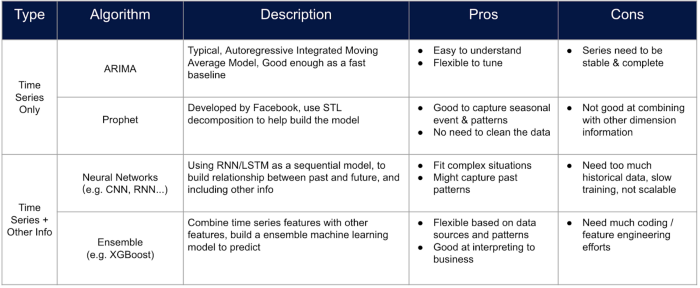
ARIMA: ARIMA wird verwendet, um ein Modell für eine Zeitreihe mit rein klassischen statistischen Methoden zu erstellen, ohne andere Merkmale, die die Eigenschaften der Sku darstellen können.
Prophet: Prophet ist ein fortschrittliches, von Facebook entwickeltes Prognosetool, das die Ereignisse und Festivals anpassen kann, allerdings können keine statischen Funktionen hinzugefügt werden.
Sowohl ARIMA als auch Prophet können kein Modell für mehrere Zeitreihen erstellen und der Fehler wird mit zunehmendem Zeithorizont immer größer.
Baumbasierte Modelle: Baumbasierte Modelle werden häufig für Klassifizierungs- und Regressionsprobleme verwendet, können aber durch einige spezielle data-Verarbeitungstricks auch für Zeitreihenprognosen eingesetzt werden. Man kann eine Tabelle erstellen, in der jedes Merkmal die Werte der Serie zu einem bestimmten Zeitstempel darstellt, und die Vorhersage kann durch Rollieren des Zeitpunkts der Vorhersage mit dem Zeitfenster erfolgen. Baumbasierte Ensemble-Modelle sind heute einer der effizientesten Wege, um ein Modell für die Absatzprognose zu erstellen, da man mehr Merkmale in das Modell einbauen kann, ohne zu viel Arbeit in die Merkmalstechnik investieren zu müssen.
Neuronales Netzwerk: Die Methoden neuronaler Netze sind aufgrund ihrer Leistungsfähigkeit nie aus der Mode gekommen. Man kann immer ein neuronales Netzwerk wie LSTM mit ähnlichen Feature-Engineering-Prozessen mit baumbasierten Modellen erstellen. Allerdings sollten die Transparenz des Modells, die benötigte Menge an data und die Trainingseffizienz immer abgeschätzt werden, bevor solche Ansätze angewendet werden.
D: Umsatztreiber
Was ist das?
In der Wirtschaft ist es allgemein bekannt, dass der Absatz eines Artikels durch andere Faktoren (Feiertage, Veranstaltungen, Kampagnen, Medien, Wetter usw.) stark beeinflusst werden kann. Wenn Sie in der Lage sind, diese Einflussfaktoren zu erkennen, haben Sie eine bessere Chance, die Prognosen mit dem Treiber data zu verbessern, insbesondere dann, wenn einige der Einflussfaktoren bereits vor der Prognose bekannt oder festgelegt sind.
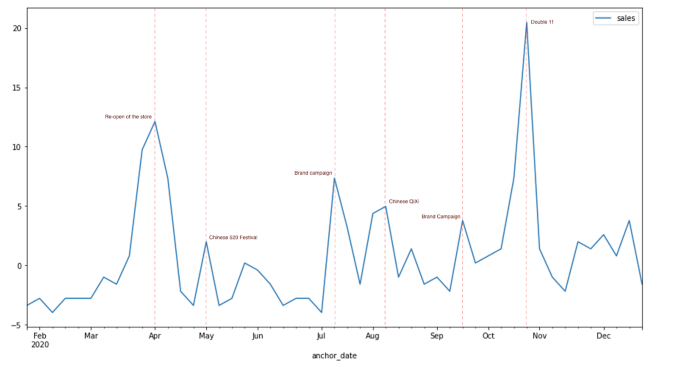
Warum ist das wichtig?
Umsatzprognosemodelle können kaum eine zufriedenstellende Leistung erzielen, wenn sie nur historische Umsätze verwenden, da das Verhalten der Kunden von zu vielen Faktoren beeinflusst werden kann. Der Umsatz eines Supermarktes kann durch das Wetter beeinflusst werden, und der Umsatz einer Kosmetikmarke kann durch die Kampagnen angezogen werden. Unsere Erfahrung hat gezeigt, dass der Einfluss verschiedener Faktoren so stark sein kann, dass sich die Umsätze in der Weihnachtszeit manchmal verdoppeln, was zu großen Fehlern bei der Modellvorhersage führen kann. Nichtsdestotrotz ist die Analyse des Einflusses der Treiber immer ein interessantes Thema, sowohl für die Vermarkter als auch für die Logistikabteilung: Welches sind die Schlüsselfaktoren, die den Umsatz beeinflussen? Wie würde sich der Umsatz verändern, wenn in der Zukunft eine große Kampagne geplant ist? Und wie lässt sich die Logistik unter verschiedenen Szenarien optimieren?
Wie wählen Sie?
Umwandlung in Zeitreihen: Angesichts der data, die sich auf potenzielle Treiber beziehen, müssen wir diese data zunächst in Zeitreihen umwandeln, damit wir den Zusammenhang zwischen dem Treiber und den Verkäufen einer Sku analysieren können. Dies kann jedoch sehr schwierig sein. Am einfachsten ist es, eine Gruppe von Ereignissen als binäre Variable zu kodieren, die angibt, ob mindestens eines dieser Ereignisse während eines bestimmten Zeitraums eintritt. Auf dieser Grundlage können die Ereignisse auch als numerische Zeitfolge kodiert werden. Zum Beispiel die Anzahl der Ereignisse am selben Tag, die Anzahl der Städte, in denen die Ereignisse an diesem Tag stattfanden, usw. Es können auch einige kundenspezifische Transformationen hinzugefügt werden, z.B. die Verwendung anderer Wellenformen anstelle von Rechteckwellen, je nach Geschäftserfahrung.
Studie zur Korrelation: Als nächstes müssen wir die Korrelation zwischen zwei Zeitreihen untersuchen. Wir empfehlen die Verwendung von TLCC (Time Lagged Cross Correlation), da die Wirkung eines Ereignisses vor oder nach dem Ereignis auftreten kann. So wirken sich beispielsweise Kampagnen in der Regel einige Tage nach dem Start aus, während die Menschen dazu neigen, das Geschenk eine Woche vor dem Fest vorzubereiten. Infolgedessen kann der Offset positiv oder negativ sein, während die absoluten Werte auf der Grundlage von Geschäftserfahrungen begrenzt werden müssen. Andernfalls wäre es zu schwierig zu erklären, warum die heutigen Verkäufe durch das Weihnachtsfest 2018 beeinträchtigt werden.
S: Sätze von SKUs
Was ist das?
Meistens werden die Verkäufe data nach SKU (Stock keeping unit) erfasst. Eine wichtige Frage beim Aufbau eines Prognosemodells auf SKU-Ebene ist daher, ob für jede SKU ein eigenes Modell trainiert werden soll oder ob alle verfügbaren SKUs für das Training eines Modells verwendet werden sollen. Während Ersteres sich auf eine einzelne SKU konzentriert und deren Merkmale differenziert, profitiert Letzteres von dem riesigen Volumen der trainierten data und spart Platz für die Lagerung der Parameter der Modelle.
Warum ist das wichtig?
Der Grund, warum wir das Modell mit allen SKUs trainieren können, ist, dass die meisten der vom Modell gelernten Signale ähnlich sind. Wenn wir also in der Lage sind, die Ähnlichkeit zwischen den data, die wir für das Training verwenden, zu maximieren, können wir den Kompromiss zwischen der Beachtung der Besonderheit jeder SKU und dem Volumen der Trainings-data optimieren.
Wie wählen Sie?
Auf der Grundlage dieser Annahme schlagen wir zwei verschiedene Methoden zur Gruppierung der SKUs vor.
Geschäftsweg: Da die Verkäufe einer Kategorie ähnlich sein können, wäre eine Gruppierung der SKUs nach ihren Kategorien ein praktischer Weg, um von den gemeinsamen Mustern unter bestimmten SKUs zu profitieren. Manchmal gibt es sogar Unterkategorien, die Sie nutzen können, um den besten Schnitt der SKU zu finden.
Data Wissenschaftlicher Weg: Eine data wissenschaftliche Methode zur Gruppierung der SKUs ist die Anwendung von Clustering-Algorithmen. Im vorherigen Abschnitt haben wir die Analyse der Korrelation zwischen SKUs und Fahrern erwähnt. Wir können dieselbe Methode verwenden, um die Korrelation zwischen den SKUs zu berechnen. Die Korrelation kann nämlich als Abstand betrachtet werden. Clustering-Algorithmen können also auf die Abstandsmatrix aller Paare von SKUs angewandt werden, und dann kann das Modell individuell auf jedem dieser Cluster trainiert werden.
Fazit
Abschließend finden Sie hier eine Kurzfassung von “GLADS”, die Sie bei Ihren Prognoseentscheidungen im Hinterkopf behalten sollten:
Letztendlich können diese Auswahlmöglichkeiten Ihnen nur dabei helfen, zu Beginn eines Prognoseprojekts einen guten Start hinzulegen oder die Methodik auf dem Weg dorthin zu verfeinern. Aber der Teufel steckt im Detail, und wir werden zu einem späteren Zeitpunkt einen Beitrag über eine detailliertere Methodik zu diesem Thema veröffentlichen. Schließlich gibt es kein Endspiel bei der Vorhersage, sondern es besteht immer die Notwendigkeit, besser zu werden..
