

Auteur

GLADS - 5 keuzes die u moet maken voordat u met modellenwerk begint

TL;DR
Vraagvoorspelling is altijd een uitdaging, dat weten we allemaal. In deze serie artikelen zult u begrijpen wat de belangrijkste uitdagingen zijn bij het ontwikkelen van een complex voorspellingsmodel voor een probleem uit de echte wereld. Ons model moet de basisvoorspellingen van vraagplanners overtreffen wat betreft de nauwkeurigheid van de voorspelling en moet gemakkelijk kunnen worden ingezet in andere landen. Eerst willen we u nuttige tips geven over de keuzes die u moet maken voordat u uw eigen model gaat trainen.
Wat kunt u van deze serie verwachten?
Wij streven ernaar om u inzichten en goede praktijken te bieden die verder gaan dan wat u in Kaggle-wedstrijden kunt vinden. Het probleem met online voorspellingswedstrijden is dat ze vaak beperkingen uit de echte wereld weglaten, zoals corrupte data, data die niet van tevoren beschikbaar is, enz.
Elk artikel in deze serie behandelt een uitdaging die u kunt tegenkomen en waarvoor geen duidelijke antwoorden op Kaggle-discussies te vinden zijn:
Het GLADS-kader
Vraagvoorspelling is een krachtig hulpmiddel geweest om bedrijven te helpen bij het nemen van beslissingen, logistieke optimalisatie en het leren van bedrijfsinzichten. Het blijft echter een uitdaging om een nauwkeurig en robuust voorspellingsmodel te hebben, op machine learning gebaseerde benaderingen hebben moeite om op echte bedrijven toegepast te worden vanwege verschillende beperkingen. De uitdaging kan zowel van de kant van het bedrijf als van de kant van data komen. Om bedrijfseigenaren en data wetenschappers te helpen deze moeilijkheden te overwinnen, hebben we vijf keuzes samengevat die u moet maken op basis van onze ervaring. Wij noemen het GLADS, wat staat voor:
In de passage zullen we kort uitleggen wat, waarom en hoe we voor GLADS hebben gekozen.
G: Korrelgrootte van data
Wat is het?
De granulariteit van data is hoe gedetailleerd uw verkoopbeschrijving zal zijn. Deze bestaat meestal uit twee dimensies: artikelen en tijd (frequentie). Beschrijft u bijvoorbeeld uw verkopen per SKU / categorie / BU / Land? Registreert u uw verkopen per uur / dag / week / maand / jaar?
Waarom is het belangrijk?
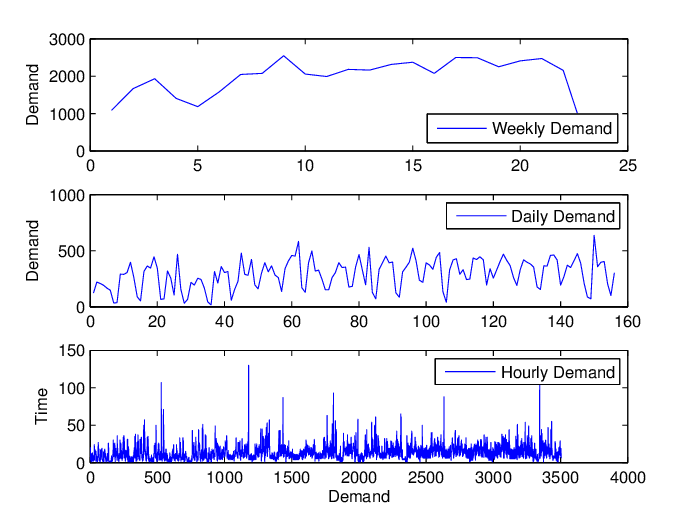
Hoewel hoe gedetailleerder de ruwe data zijn, hoe meer opties de Data wetenschapper kan gebruiken voor verkoopprognoses, is de keuze van de granulariteit niet zo eenvoudig. Blijkbaar kan een hogere granulariteit meer informatie bevatten bij het beschrijven van de verkoop, maar het kan ook een grote hoeveelheid ruis in de data veroorzaken. Het kiezen van de juiste granulariteit is een noodzakelijke stap om de data te denatureren en zoveel mogelijk informatie te behouden, die een solide basis kan vormen voor de volgende modelleerstappen.
Hoe kiezen?
De granulariteit moet worden gekozen op basis van twee belangrijke factoren: de bedrijfsbehoefte en de data kenmerken zelf.
Gebaseerd op uw bedrijfsbehoeften: De bedrijfsbehoefte is altijd het eerste waar rekening mee moet worden gehouden. In sommige gevallen is een maandelijkse verkoop voldoende, terwijl u in andere gevallen gevraagd kunt worden om de verkoop per uur te voorspellen. De bedrijfsbehoeften verschillen sterk per branche, en zorg ervoor dat u het model begint te bouwen nadat u deze eerst hebt begrepen.
Gebaseerd op data kenmerken: Bakstenen kunnen niet gemaakt worden zonder stro, als de granulariteit van de data in strijd is met de bedrijfsbehoefte, moet het eerste idee dat u in uw hoofd opkomt het verzamelen van de data op een andere manier zijn. Hoewel sommige algoritmen u kunnen helpen om de granulariteit van uw data te verhogen door simulatie of machine learning, brengt het bouwen van een model op basis van pseudo-data u te veel onzekerheid. Toch is het soms nodig om de data naar een lagere granulariteit te aggregeren. In deze gevallen zijn de data te instabiel met een hoge variantie, dan kan aggregatie van data een nuttig hulpmiddel zijn om de data te stabiliseren en de prestaties van uw model te verhogen.
L: Lengte van de horizon
Wat is het?
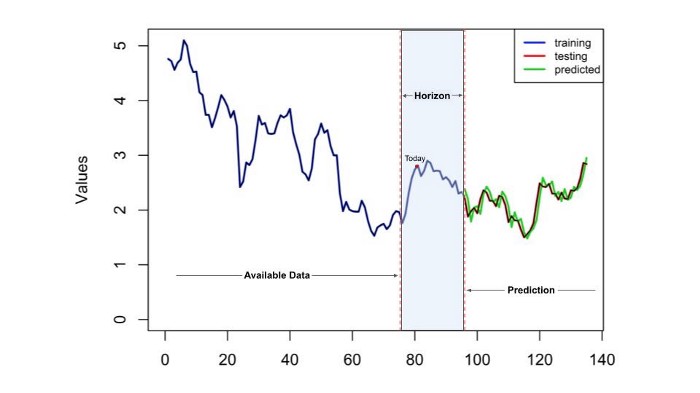
De tijdshorizon van uw voorspellingsmodel is in feite hoe lang in de toekomst de voorspelling zou moeten presteren. Als we een voorspelling opstellen met een tijdshorizon van twee maanden, dan betekent dit dat ons model het voorspelde resultaat twee maanden vanaf de huidige tijd zou geven met een bepaalde granulariteit.
Waarom is het belangrijk?
Hoewel de nauwkeurigheid van het model vaak als enige prestatiemaatstaf wordt gebruikt bij het evalueren van een voorspellingsmodel, kan de tijdshorizon essentieel zijn bij het toepassen van het model in de echte wereld. Net als bij weersvoorspellingen kan men altijd een betere nauwkeurigheid bereiken bij het voorspellen van de temperatuur in de komende paar uur dan een week later. Hetzelfde geldt voor het voorspellen van de verkoop: hoe langer de horizon, hoe lager de nauwkeurigheid. Voor zakelijke toepassingen zou het echter omgekeerd zijn. Normaal gesproken is het niet nodig om de verkoop van de volgende dag te voorspellen, omdat er 's nachts weinig beslissingen kunnen worden genomen en uitgevoerd, terwijl het heel nuttig kan zijn om te weten wat er de komende weken of maanden gaat gebeuren. Wees niet blind zonder een tijdshorizon in gedachten te hebben en bouw een model dat niet in de echte wereld kan worden toegepast.
Hoe kiezen?
De lengte van de tijdshorizon hangt volledig af van de bedrijfsbehoeften. Als de voorspelling bijvoorbeeld gebruikt gaat worden om de magazijnplanning te optimaliseren, dan is het voorspellen van de verkoop voor de volgende dag misschien niet zo nuttig. De prognosehorizon moet dus worden ingesteld op basis van hoe lang het duurt om de toekomst te kennen en de actie daadwerkelijk uit te voeren. Of eerlijker gezegd: hoeveel moet u getallen van tevoren weten? Ter herinnering: een te lange horizon kan de hoeveelheid trainingssamples die u hebt verminderen als de tijdsdekking van de data niet lang genoeg is.
A: Algoritme voor voorspelling
Wat is het?
Verkoopvoorspellingsbenaderingen evolueren al jaren, wat de diversiteit van de algoritmen verklaart. Hoewel de populairste tools als het gaat om verkoopprognoses ARIMA van statsmodel en Prophet zijn, zijn op bomen gebaseerde regressiemodellen ook toegepast op verkoopvoorspellingstaken. Ondertussen zijn diepe neurale netwerken nooit uit de lijst van kandidaten verdwenen wanneer machine learning wordt toegepast.
Waarom is het belangrijk?
Het is misschien niet de taak van een Data wetenschapper om een gloednieuw algoritme te ontwikkelen voor een speciale taak, de grootste uitdaging voor hen is tegenwoordig het kiezen van het juiste algoritme en de aangepaste data verwerking voor het algoritme. Het kiezen van een algoritme zonder rekening te houden met de beschikbare data, de bedrijfscontext of de eisen aan de transparantie van het model, zou het model waarschijnlijk veranderen in tonnen parameters die op de server blijven staan zonder goede toepassing.
Hoe kiezen?
Voordat u het beste algoritme voor uw geval kiest, zijn hier enkele algemene concepten die u voor elke tak van het algoritme moet kennen.
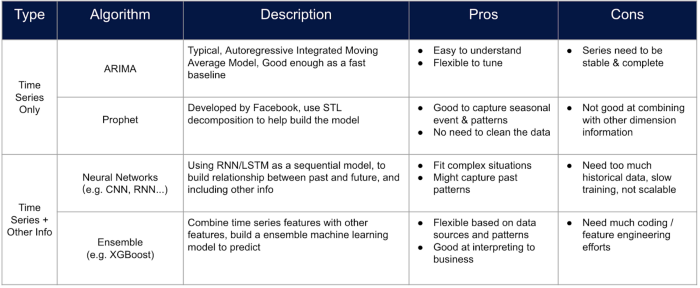
ARIMA: ARIMA wordt gebruikt om een model voor een tijdreeks te bouwen met puur klassieke statistische methoden zonder andere kenmerken die de kenmerken van de sku kunnen weergeven.
Profeet: Prophet is een geavanceerde voorspellingstool ontworpen door Facebook, die de gebeurtenissen en festivals kan aanpassen, maar er kunnen geen statische functies worden toegevoegd.
Zowel ARIMA als Prophet kunnen geen model bouwen voor meerdere tijdreeksen en de fout zal zich opstapelen naarmate de horizon toeneemt.
Boomgebaseerde modellen: Boomgebaseerde modellen worden vaak gebruikt voor classificatie- en regressieproblemen, maar kunnen ook gebruikt worden voor het voorspellen van tijdreeksen met behulp van enkele speciale data verwerkingstrucs. Men kan een tabel maken waarin elk kenmerk de waarden van de serie op het specifieke tijdstempel vertegenwoordigt, en de voorspelling kan worden gedaan door het tijdstip van voorspelling te laten rollen met het tijdvenster. Boomgebaseerde ensemblemodellen zijn nu een van de meest efficiënte manieren om een verkoopvoorspellingsmodel te bouwen, omdat men meer kenmerken in het model kan aanpassen zonder al te veel werk aan feature engineering.
Neuraal netwerk: Neurale netwerkmethoden zijn nooit ouderwets vanwege hun prestaties. Men kan altijd een neuraal netwerk zoals LSTM bouwen met vergelijkbare feature engineering processen met boomgebaseerde modellen. De transparantie van het model, de benodigde hoeveelheid data en de trainingsefficiëntie moeten echter altijd worden ingeschat voordat dergelijke benaderingen worden toegepast.
D: Aanjagers van verkoop
Wat is het?
Het is algemeen bekend in de zakenwereld dat de verkoop van een artikel enorm beïnvloed kan worden door andere factoren (vakanties, evenementen, campagnes, media, weer, etc.). Als u in staat bent om deze factoren te achterhalen, hebt u een betere kans om de prognose met de driver data te verbeteren, vooral als sommige factoren al bekend zijn of ingesteld zijn voordat de prognose wordt gemaakt.
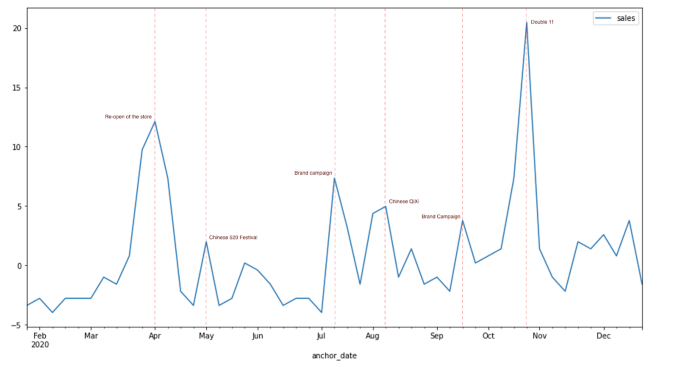
Waarom is het belangrijk?
Verkoopprognosemodellen kunnen nauwelijks bevredigende prestaties leveren als ze alleen gebruik maken van historische verkoopcijfers, omdat het gedrag van klanten door te veel factoren beïnvloed kan worden. De verkoop van een supermarkt kan beïnvloed worden door het weer, en de verkoop van een cosmeticamerk kan getrokken worden door de campagnes. Uit onze ervaring blijkt dat de invloed van verschillende factoren zo groot kan zijn dat de verkoop tijdens het feestseizoen soms verdubbeld wordt, wat enorme fouten in de voorspelling van het model kan veroorzaken. Toch is het analyseren van de impact van drivers altijd een interessant onderwerp voor zowel marketeers als de logistieke afdeling: wat zijn de belangrijkste factoren die de verkoop bepalen? Hoe zou de verkoop veranderen als er in de toekomst een grote campagne wordt gepland? En hoe kan de logistiek in verschillende scenario's worden geoptimaliseerd?
Hoe kiezen?
Transformatie naar tijdreeksen: Gegeven de data met betrekking tot potentiële bestuurders, is het eerste wat we moeten doen deze data omzetten in tijdreeksen, zodat we de correlatie tussen de bestuurder en de verkoop van één sku kunnen analyseren. Dit kan echter erg lastig zijn. De eenvoudigste manier is om een groep gebeurtenissen te coderen als een binaire variabele die aangeeft of ten minste één van deze gebeurtenissen plaatsvindt gedurende een bepaalde tijdsperiode. Op basis daarvan kunnen de gebeurtenissen ook worden gecodeerd als een numerieke tijdreeks. Bijvoorbeeld het aantal gebeurtenissen op dezelfde dag, het aantal steden waar de gebeurtenissen op die dag plaatsvonden, enz. Er kan ook een aangepaste transformatie worden toegevoegd, zoals het gebruik van andere vormen van golven in plaats van vierkante golven, afhankelijk van de bedrijfservaring.
Studie van correlatie: Vervolgens moeten we de correlatie tussen twee tijdreeksen bestuderen. We stellen voor om TLCC (Time Lagged Cross Correlation) te gebruiken, omdat het effect van een gebeurtenis voor of na de gebeurtenis kan optreden. Campagnes hebben bijvoorbeeld meestal enkele dagen na de lancering effect, terwijl mensen geneigd zijn om het cadeau een week voor het festival voor te bereiden. Als gevolg hiervan kan de compensatie positief of negatief zijn, terwijl de absolute waarden beperkt moeten worden op basis van bedrijfservaring, anders zou het te moeilijk zijn om te verklaren waarom de verkoop van vandaag beïnvloed wordt door de kerst van 2018.
S: Reeksen SKU's
Wat is het?
Meestal wordt de verkoop data verzameld per SKU (Stock keeping unit), dus een belangrijke vraag bij het bouwen van een voorspellingsmodel op SKU-niveau is of er een individueel model voor elke SKU moet worden getraind of dat alle beschikbare SKU's moeten worden gebruikt om één model te trainen. Terwijl het eerste model zich richt op één SKU en de kenmerken ervan differentieert, profiteert het tweede model van het enorme volume van de trainings data en bespaart het ruimte voor het opslaan van de parameters van modellen.
Waarom is het belangrijk?
De reden waarom we het model met alle SKU's kunnen trainen, is dat de meeste door het model geleerde signalen vergelijkbaar zijn. Als we dus de overeenkomst tussen de data die we voor de training gebruiken kunnen maximaliseren, kunnen we de afweging tussen het respect voor de bijzonderheid van elke SKU en het volume van de getrainde data optimaliseren.
Hoe kiezen?
Op basis van die veronderstelling stellen wij twee verschillende methoden voor om de SKU's te groeperen.
Zakelijke manier: Aangezien de verkoop van een categorie vergelijkbaar kan zijn, is het groeperen van SKU's op basis van hun categorie een praktische manier om te profiteren van de gemeenschappelijke patronen onder bepaalde SKU. Soms zijn er zelfs subcategorieën die u kunt gebruiken om de beste SKU-verkopen te vinden.
Data wetenschapsmanier: Een data wetenschappelijke manier om de SKU's te groeperen is door clusteralgoritmen toe te passen. In het vorige hoofdstuk hebben we het gehad over de analyse van de correlatie tussen SKU's en chauffeurs, we kunnen dezelfde methode gebruiken om de correlatie tussen de SKU's te berekenen. In feite kan de correlatie worden beschouwd als afstand, zodat clusteralgoritmen kunnen worden toegepast op de afstandsmatrix van alle SKU-paren, waarna het model afzonderlijk op elk van deze clusters kan worden getraind.
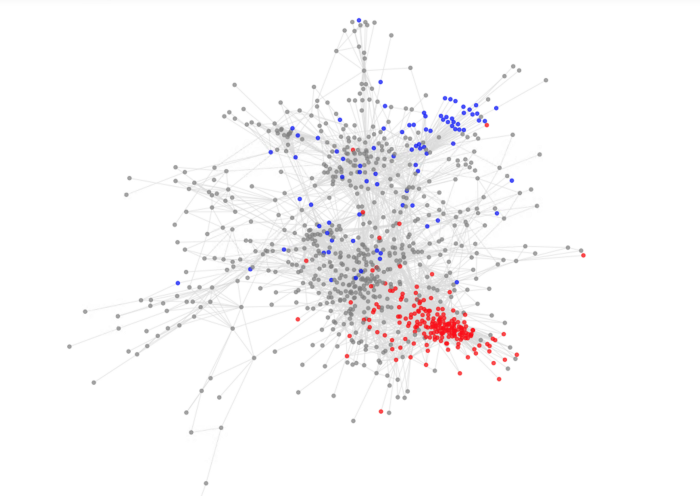
Conclusie
Ter afsluiting volgt hier een korte versie van “GLADS” om in gedachten te houden wanneer u voorspellingskeuzes maakt:
Uiteindelijk kunnen deze keuzes u alleen helpen om een goede start te maken aan het begin van een prognoseproject, of om de methodologie gaandeweg te verfijnen. Maar de duivel zit in de details, en we zullen later meer gedetailleerde methodologieën met betrekking tot dit onderwerp bespreken. Er is immers geen eindspel in voorspellen, het moet altijd beter.
