

Auteur

GLADS - 5 choix à faire avant de se lancer dans le mannequinat

TL;DR
La prévision de la demande est toujours un défi, nous le savons tous. Dans cette série d'articles, vous comprendrez les principaux défis posés par le développement d'un modèle de prévision complexe sur un problème réel. Notre modèle doit surpasser les prévisions de base faites par les planificateurs de la demande en termes de précision et être facilement déployé dans d'autres pays. Tout d'abord, nous aimerions vous donner des conseils utiles concernant les choix que vous devez faire avant de former votre propre modèle.
Que peut-on attendre de cette série ?
Notre objectif est de vous fournir des informations et des bonnes pratiques qui vont au-delà de ce que vous pouvez trouver dans les concours Kaggle. Le problème des concours de prévision en ligne est qu'ils omettent souvent les contraintes du monde réel telles que data corrompu, data non disponible à l'avance, etc.
Chaque article de cette série abordera un défi que vous pourriez rencontrer et pour lequel il n'y a pas de réponses claires dans les discussions Kaggle :
Le cadre GLADS
La prévision de la demande est un outil puissant qui aide les entreprises à prendre des décisions, à optimiser leur logistique et à acquérir des connaissances. Cependant, il reste difficile de disposer d'un modèle de prévision précis et robuste, et les approches basées sur l'apprentissage automatique peinent à être appliquées aux entreprises réelles en raison de différentes contraintes. Le défi peut venir à la fois du côté de l'entreprise et du côté de data. Pour aider les chefs d'entreprise et les scientifiques de data à surmonter ces difficultés, nous avons résumé cinq choix que vous devez faire sur la base de notre expérience. Nous les appelons GLADS, ce qui signifie :
Dans le passage, nous expliquerons brièvement ce que, pourquoi et comment nous avons choisi GLADS.
G : Granularité de data
Qu'est-ce que c'est ?
La granularité de data est le degré de détail de votre dénomination de vente. Elle se décline généralement en deux dimensions : les articles et le temps (fréquence). Par exemple, décrivez-vous vos ventes par SKU / catégorie / BU / pays ? Enregistrez-vous vos ventes par heure / jour / semaine / mois / année ?
Pourquoi est-ce important ?
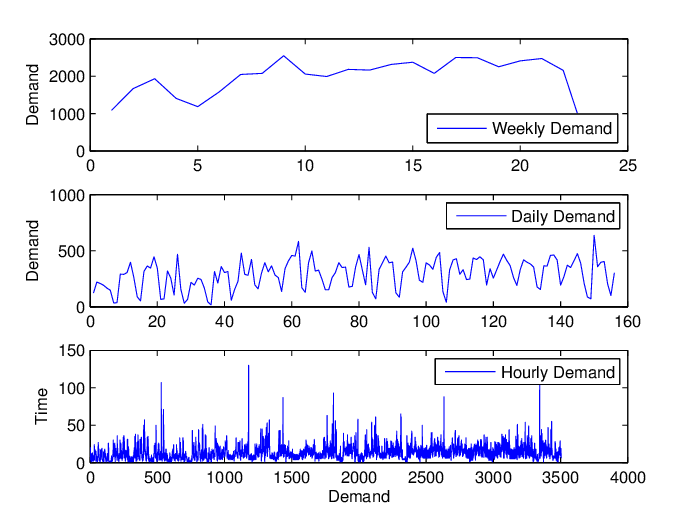
Si plus les données brutes data sont détaillées, plus le scientifique Data dispose d'options pour la prévision des ventes, le choix de la granularité n'est pas si simple. Apparemment, une granularité plus élevée permet de conserver davantage d'informations lors de la description des ventes, mais elle peut également entraîner une grande quantité de bruit dans les data. Le choix de la bonne granularité est une étape nécessaire pour débruiter le data et conserver autant d'informations que possible, ce qui peut constituer une base solide pour les étapes de modélisation suivantes.
Comment choisir ?
La granularité doit être choisie en tenant compte de deux facteurs principaux : les besoins de l'entreprise et les caractéristiques de la data elle-même.
En fonction des besoins de votre entreprise: Les besoins de l'entreprise sont toujours la première chose à prendre en considération. Dans certains cas, les ventes mensuelles suffisent, alors que dans d'autres, on vous demandera de prédire les ventes pour chaque heure. Les besoins de l'entreprise varient beaucoup d'un secteur à l'autre, et veillez à commencer à construire le modèle après l'avoir compris.
Basé sur les caractéristiques du data: Les briques ne peuvent être fabriquées sans paille, si la granularité du data est en conflit avec les besoins de l'entreprise, la première idée qui vous vient à l'esprit devrait être de collecter le data d'une autre manière. Bien que certains algorithmes puissent vous aider à élever la granularité de votre data par la simulation ou l'apprentissage automatique, la construction d'un modèle utilisant le pseudo-data vous apporte trop d'incertitude. Néanmoins, l'agrégation des data à une granularité inférieure est parfois nécessaire, dans ces cas, les data sont trop instables avec une variance élevée, l'agrégation des data peut être un outil utile pour stabiliser les data et augmenter la performance de votre modèle.
L : Longueur de l'horizon
Qu'est-ce que c'est ?
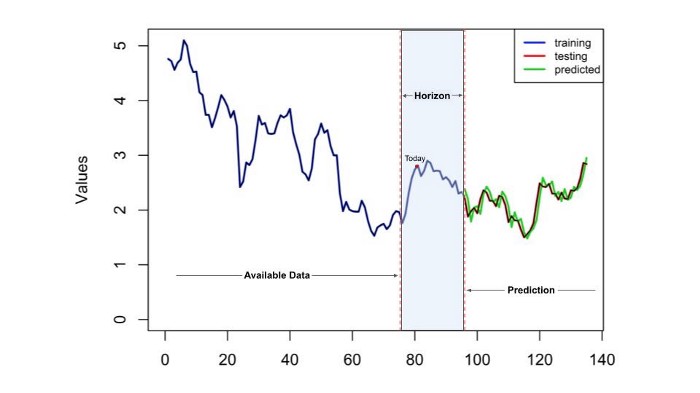
L'horizon temporel de votre modèle de prévision correspond essentiellement à la durée de la prédiction. Si nous préparons une prévision avec un horizon temporel de deux mois, cela signifie que notre modèle donnera le résultat prévu deux mois plus tard, avec une certaine granularité.
Pourquoi est-ce important ?
Alors que la précision du modèle est souvent utilisée comme seule mesure de performance lors de l'évaluation d'un modèle de prévision, l'horizon temporel peut être essentiel lors de l'application du modèle dans le monde réel. À l'instar des prévisions météorologiques, il est toujours possible d'obtenir une meilleure précision en prédisant la température des prochaines heures que celle d'une semaine plus tard. Il en va de même pour les prévisions de ventes : plus l'horizon est long, plus la précision est faible. Cependant, pour les applications commerciales, c'est l'inverse. Normalement, il n'est pas nécessaire de prévoir les ventes du lendemain, car peu de décisions peuvent être prises et exécutées pendant la nuit, alors qu'il peut être très utile de savoir ce qui se passera au cours des semaines ou des mois suivants. Ne soyez pas aveugle sans avoir un horizon temporel à l'esprit et ne construisez pas un modèle qui ne peut pas être appliqué dans le monde réel.
Comment choisir ?
La durée de l'horizon temporel dépend entièrement des besoins de l'entreprise. Par exemple, si les prévisions doivent être utilisées pour optimiser la planification des entrepôts, il n'est pas forcément utile de prévoir les ventes pour le lendemain. L'horizon prévisionnel doit donc être fixé en fonction du temps qui s'écoule entre la connaissance de l'avenir et la mise en œuvre effective de l'action. Ou, pour dire les choses plus franchement : dans quelle mesure devez-vous connaître les chiffres à l'avance ? Pour rappel, un horizon trop long peut réduire la quantité d'échantillons d'entraînement dont vous disposez si la couverture temporelle du data n'est pas assez longue.
A : Algorithme de prédiction
Qu'est-ce que c'est ?
Les méthodes de prévision des ventes évoluent depuis des années, d'où la diversité des algorithmes. Si les outils les plus populaires en matière de prévision des ventes sont ARIMA de statsmodel et Prophet, les modèles de régression à base d'arbres ont également été appliqués aux tâches de prévision des ventes. Par ailleurs, les réseaux neuronaux profonds n'ont jamais été écartés de la liste des candidats lorsqu'il s'agit d'appliquer l'apprentissage automatique.
Pourquoi est-ce important ?
Le scientifique Data n'a peut-être pas pour mission de développer un tout nouvel algorithme pour une tâche particulière, mais le principal défi consiste aujourd'hui à choisir le bon algorithme et le traitement data personnalisé pour l'algorithme. Choisir un algorithme sans tenir compte du data disponible, du contexte commercial ou des exigences en matière de transparence du modèle transformera probablement le modèle en une multitude de paramètres qui resteront sur le serveur sans application appropriée.
Comment choisir ?
Avant de choisir l'algorithme le mieux adapté à votre cas, voici quelques notions générales à connaître pour chaque branche de l'algorithme.
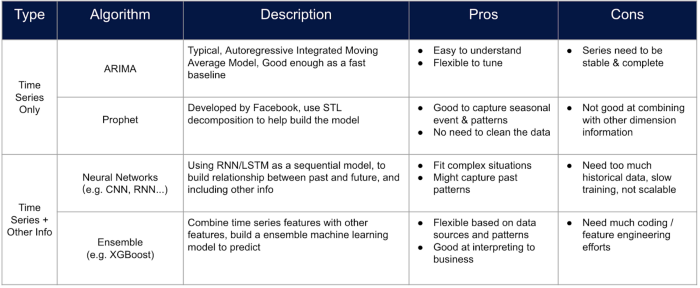
ARIMA: ARIMA est utilisé pour construire un modèle pour une série temporelle en utilisant des méthodes statistiques purement classiques sans autres caractéristiques qui peuvent représenter les caractéristiques du sku.
Prophète: Prophet est un outil de prévision avancé conçu par Facebook, qui permet de personnaliser les événements et les festivals, mais aucune fonction statique ne peut être ajoutée.
ARIMA et Prophet ne peuvent pas construire un modèle pour des séries temporelles multiples et l'erreur s'accumule au fur et à mesure que l'horizon augmente.
Modèles arborescents: Les modèles à base d'arbres sont souvent utilisés pour les problèmes de classification et de régression, mais ils peuvent également être utilisés pour la prévision de séries temporelles grâce à quelques astuces de traitement data spéciales. Il est possible de construire un tableau dans lequel chaque caractéristique représente les valeurs de la série à l'heure spécifique, et la prévision peut être faite en faisant rouler le temps de la prédiction avec la fenêtre temporelle. Les modèles d'ensemble basés sur des arbres sont désormais l'une des méthodes les plus efficaces pour construire un modèle de prévision des ventes, car il est possible de personnaliser davantage de caractéristiques dans le modèle sans trop de travail sur l'ingénierie des caractéristiques.
Réseau neuronal: Les méthodes de réseaux neuronaux ne sont jamais démodées en raison de leurs performances. On peut toujours construire un réseau neuronal comme LSTM avec des processus d'ingénierie des caractéristiques similaires à ceux des modèles à base d'arbres. Toutefois, la transparence du modèle, la quantité de data nécessaire et l'efficacité de l'apprentissage doivent toujours être estimées avant d'appliquer de telles approches.
D : Facteurs de vente
Qu'est-ce que c'est ?
Il est de notoriété publique dans le monde des affaires que les ventes d'un article peuvent être fortement influencées par d'autres facteurs (vacances, événements, campagnes, médias, conditions météorologiques, etc.) Lorsque vous êtes en mesure d'identifier ces facteurs, vous avez plus de chances d'améliorer les prévisions avec le pilote data, en particulier lorsque certains de ces facteurs peuvent être connus ou définis avant la prévision.
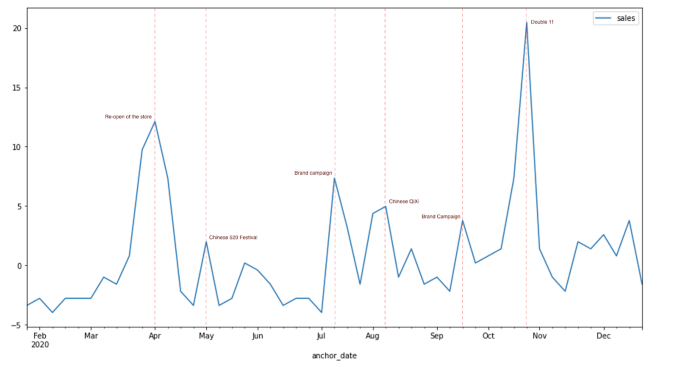
Pourquoi est-ce important ?
Les modèles de prévision des ventes peuvent difficilement atteindre une performance satisfaisante s'ils utilisent uniquement l'historique des ventes, car le comportement des clients peut être influencé par de trop nombreux facteurs. Les ventes d'un supermarché peuvent être influencées par la météo, et les ventes d'une marque de cosmétiques peuvent être tirées par les campagnes. D'après notre expérience, l'impact des différents facteurs peut être si fort que les ventes sont parfois doublées pendant les fêtes de fin d'année, ce qui peut entraîner d'énormes erreurs dans la prédiction du modèle. Néanmoins, l'analyse de l'impact des facteurs est toujours un sujet intéressant pour les spécialistes du marketing comme pour le département logistique : quels sont les facteurs clés qui déterminent les ventes ? Quels sont les facteurs clés qui déterminent les ventes ? Comment les ventes évolueraient-elles si une grande campagne était programmée à l'avenir ? Et comment optimiser la logistique dans différents scénarios ?
Comment choisir ?
Transformation en séries temporelles: Étant donné les data relatives aux conducteurs potentiels, la première chose à faire est de transformer ces data en séries temporelles afin de pouvoir analyser la corrélation entre le conducteur et les ventes d'un sku. Cependant, cela peut s'avérer très délicat. La méthode la plus simple consiste à coder un groupe d'événements sous la forme d'une variable binaire indiquant si au moins l'un de ces événements se produit au cours d'une certaine période. Sur cette base, les événements peuvent également être codés sous la forme d'une séquence temporelle numérique. Par exemple, le nombre d'événements survenus le même jour, le nombre de villes où les événements se sont produits ce jour-là, etc. Certaines transformations personnalisées peuvent également être ajoutées, comme l'utilisation d'autres formes d'ondes au lieu d'ondes carrées, en fonction de l'expérience de l'entreprise.
Étude de corrélation: Ensuite, nous devons étudier la corrélation entre deux séries temporelles. Nous vous proposons d'utiliser la méthode TLCC (Time Lagged Cross Correlation) car l'effet d'un événement peut apparaître avant ou après l'événement. Par exemple, les campagnes prennent généralement effet plusieurs jours après leur lancement, tandis que les gens ont tendance à préparer le cadeau une semaine avant la fête. Par conséquent, le décalage peut être positif ou négatif, tandis que les valeurs absolues doivent être limitées sur la base de l'expérience commerciale, sinon il serait trop difficile d'expliquer pourquoi les ventes d'aujourd'hui sont affectées par le Noël de 2018.
S : Ensembles d'UGS
Qu'est-ce que c'est ?
La plupart du temps, les ventes data sont rassemblées par UGS (unité de gestion des stocks), de sorte qu'une question importante lors de l'élaboration d'un modèle de prévision au niveau des UGS est de savoir s'il faut former un modèle individuel pour chaque UGS ou utiliser toutes les UGS disponibles pour former un seul modèle. Alors que la première solution se concentre sur une seule unité de stock et en différencie les caractéristiques, la seconde bénéficie de l'énorme volume des data d'apprentissage et économise de l'espace pour stocker les paramètres des modèles.
Pourquoi est-ce important ?
La raison pour laquelle nous pouvons entraîner le modèle avec toutes les UGS est que la plupart des signaux appris par le modèle sont similaires. Par conséquent, si nous sommes en mesure de maximiser la similarité entre les data que nous utilisons pour l'entraînement, nous pouvons optimiser le compromis entre le respect de la particularité de chaque UGS et le volume des data d'entraînement.
Comment choisir ?
Sur la base de cette hypothèse, nous proposons deux méthodes différentes pour regrouper les UGS.
La voie de l'entreprise: Étant donné que les ventes d'une catégorie peuvent être similaires, le regroupement des UGS par catégorie est un moyen pratique de tirer parti des modèles communs à certaines UGS. Parfois, il existe même des sous-catégories que vous pouvez exploiter pour trouver la meilleure coupe d'UGS.
Data voie scientifique: Une data science façon de regrouper les UGS est d'appliquer des algorithmes de clustering. Dans la section précédente, nous avons mentionné l'analyse de la corrélation entre les UGS et les conducteurs, nous pouvons utiliser la même méthode pour calculer la corrélation entre les UGS. En fait, la corrélation peut être considérée comme une distance, les algorithmes de regroupement peuvent donc être appliqués à la matrice de distance entre toutes les paires d'UGS, puis le modèle peut être entraîné individuellement sur chacun de ces regroupements.
Pour conclure
En guise de conclusion, voici une version abrégée de “GLADS” à garder à l'esprit lorsque vous faites des choix en matière de prévision :
En fin de compte, ces choix ne peuvent que vous aider à prendre une bonne longueur d'avance au début d'un projet de prévision, ou à affiner la méthodologie en cours de route. Mais le diable se cache dans les détails, et nous publierons ultérieurement un article sur une méthodologie plus détaillée en rapport avec ce sujet. Après tout, il n'y a pas de finalité à la prévision, il faut toujours faire mieux.
