Desafio: dimensionar o marketing de precisão avançado em mais de 30 mercados
A Sanofi é uma das líderes mundiais do setor farmacêutico. Nos últimos 3 anos, Artefact tem ajudado A unidade de negócios CHC (Consumer Health Care) da Sanofi comercializa seus medicamentos de venda livre por meio de táticas e capacitadores com prioridade digital para alcançar os consumidores certos, no momento certo e com a mensagem certa, em mais de 30 mercados.
Para sua categoria de produtos sazonais, a Sanofi CHC desenvolveu uma abordagem baseada em previsões para ajustar os gastos com mídia digital de acordo com os picos de demanda previstos. Por meio de várias campanhas piloto, a equipe de Transformação Digital Global conseguiu provar o valor agregado dessa abordagem com um ROAS multiplicado por 2 a 4 de acordo com as regiões geográficas.
No entanto, a configuração de uma nova campanha continuava a consumir muito tempo: Os cientistas do data precisavam passar por uma série de tarefas manuais, repetitivas e sujeitas a erros, o que os impedia de se concentrar em outros projetos inovadores. Para dimensionar seus pipelines de ML inovadores, a equipe científica do data da Sanofi definiu suas necessidades para industrializar o caso de uso e solicitou o apoio do Artefact para projetar e implementar em conjunto uma solução robusta.
Solução: um processo de industrialização co-projetado com base em 6 soluções-chave
“A chave para o sucesso do projeto foi a estreita colaboração entre os especialistas em negócios da Sanofi e os cientistas do data da Sanofi com a equipe do Artefact.”
- Albert Pla Planas, líder da equipe científica do Data, Sanofi
Por meio de uma estreita colaboração entre o Artefact e o data da Sanofi e as equipes de negócios, um processo de industrialização abrangente que aproveita a tecnologia unificada de Databricks A plataforma foi projetada. Nossos objetivos conjuntos eram:
Simplifique a configuração de ponta a ponta de uma nova campanha sazonal
Automatizar as tarefas de ingestão e processamento do data
Tornar a solução mais robusta para evitar erros e manutenção manual
Melhorar a capacidade de manutenção e o dimensionamento do projeto
Após uma rápida auditoria de uma semana para mapear o processo atual e os pontos técnicos problemáticos, a equipe se alinhou para implementar uma infraestrutura preparada para o futuro com base em seis soluções principais:
Separação de preocupações:
Ter um pipeline ETL separado do processo do modelo de previsão facilita a manutenção e o dimensionamento. Isso nos permitiu implementar verificações automatizadas juntamente com um sistema de monitoramento que envia reports detalhados para as equipes relevantes sobre o status da ingestão.
Uso de Lago Delta como uma fonte dourada data:
Nas equipes de DS em que a infraestrutura pode ser difícil de obter/manter, o Delta Lake combina os principais recursos das soluções de armazém do data e de lagos do data, eliminando assim a complexidade da administração do SQL database. Ele também possui recursos de controle de versão - importantes para a reprodutibilidade do ML - e servirá como a única fonte de verdade para o data.
Empacotar o máximo possível de código em uma biblioteca Python para simplificar os processos:
Parte do código inicial estava dispersa em vários notebooks dentro do Databricks, complexificando o gerenciamento de dependências e a reutilização do código. O desenvolvimento baseado em notebooks é relevante para a criação de protótipos, mas pode criar desafios para a industrialização de projetos de ML. Ter bibliotecas Python claramente definidas implementadas no notebook e manter apenas o Databricks como ponto de entrada para o Compute facilitou a generalização dos notebooks e a organização das campanhas de entrada.
Aproveitamento do Spark e do Databricks:
O treinamento do modelo usando métodos de pesquisa de hiperparâmetros pode ser demorado e exigente. É nesse ponto que a infraestrutura de dimensionamento automático do Databricks e o tempo de execução de ML gerenciado com Spark e HyperOpt são úteis. O uso de cálculos de memória de forma distribuída em um conjunto de trabalhadores acelera o desempenho e melhora consideravelmente o tempo de treinamento.
Uso do ML Flow tracking:
Com ML Flow tracking A Sanofi agora tem uma interface de usuário na qual os cientistas do Data podem comparar execuções de modelos e acompanhar todos os parâmetros usados (versão do Data e parâmetros do modelo) e os resultados obtidos.
Teste e implementação simplificados de novos modelos de ML:
Foi criada uma estrutura genérica de fábrica de modelos, facilitando a implementação de novos modelos de aprendizado de máquina e a experimentação deles durante uma campanha de Marketing de Precisão com muito pouco esforço.
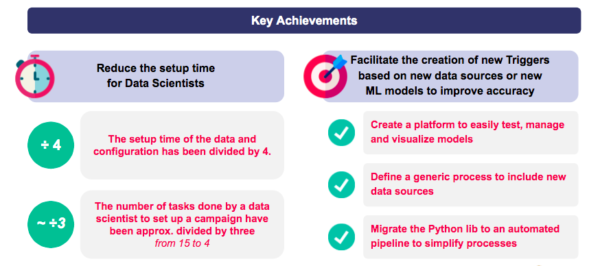
Resultados e aprendizados: um tempo de preparação dividido por quatro para ingestão e configuração do data
Graças a esse projeto, a Sanofi CHC conseguiu simplificar bastante seu pipeline data e acelerar o dimensionamento de seu caso de uso de marketing de precisão baseado em previsão.
Redução do tempo de configuração de novas campanhas:
- O tempo de instalação para ingestão e configuração do data foi reduzido em até um quarto.
- O número de tarefas realizadas pelos cientistas do data para configurar uma nova campanha foi reduzido em até um terço.
Simplificação da criação de novos modelos de previsão:
- Plataforma acessível para testar, gerenciar e visualizar modelos com facilidade.
- Processo genérico para incluir novas fontes data.
- Pipeline data automatizado.
O projeto também permitiu que as equipes gerassem 4 aprendizados importantes para futuros projetos orientados por ML:
Integrar a engenharia do data em projetos de ML:
Envolver os Data Engineers desde o início de um projeto para acelerar a industrialização do pipeline e dissociar claramente os diferentes estágios do pipeline (todo o manuseio, transformação e curadoria de data devem ocorrer antes de passar para os estágios de ML).
Aproveite as ferramentas pré-empacotadas:
O uso de Databricks com Delta Lake e ML Flow foi crucial para o sucesso da industrialização, garantindo uma infraestrutura de autoatendimento fácil sem a necessidade de DevOps.
Colaboração profunda entre as equipes de negócios e Data:
Possivelmente, o fator de sucesso mais importante foi a estreita colaboração entre os especialistas em negócios da Sanofi e os cientistas do data, que idealizaram e conduziram o projeto, com a equipe do Artefact, que trouxe experiência e know-how adicionais em industrialização.
Usar metodologias ágeis para industrializar:
A metodologia ágil (sprints e iterações rápidas seguidas de semanas de feedback e alinhamento) foi muito eficiente para identificar e abordar todos os pontos problemáticos da Sanofi e garantir a entrega de valor para as equipes da empresa.
A Artefact gostaria de agradecer a Ayaka Yanagisawa, Albert Pla Planas, Antoine Tran-Quan-Nam, Laurent Gautier e Sergio Villordo da Sanofi por sua confiança e colaboração neste projeto, bem como à equipe da Databricks por seu apoio reativo. Este artigo foi coproduzido pelas equipes da Sanofi CHC e da Databricks, juntamente com Tristan Silhol, Maui Bar, Louise Morin e Eva Le Saux, dos escritórios da Artefact nos EUA e na França.