


导言
现在,重心正在转移。随着人工智能,尤其是大型语言模型(LLM)渗透到工作流程中,性能不再取决于我们拥有什么 data,而是更多地取决于 如何指导系统使用. .关键资产已成为 背景提示:提示、指令集、游戏手册、代理记忆、工具使用指南,以及在推理时引导推理的领域启发式方法。. 背景是新的主控 data。.
无人管理的环境已经在创造 背景混乱、, 提示不断增加,团队临时改写指令,诀窍坍塌成通用摘要,行为发生偏移。最近的研究指出了一种补救方法。我们的 ACE,代理情境工程框架、, 斯坦福大学和加州大学伯克利分校的研究人员将上下文作为一种 全面、不断发展的游戏手册 通过 生成→反映→整理 循环。在报告的基准测试中,ACE 显示 代理任务 +10.6 个百分点 和 特定领域财务推理 +8.6 分, 即使是自然执行反馈,也能实现更快的适应和收益。.
人工智能时代传统 MDM 的局限性
MDM 解决了以下问题 data人工智能应用程序:它集中和同步实体记录,执行模式和生存权,调节重复,并提供世系和管理。然而,人工智能应用程序是在 背景. .情境是动态的、可操作的。它随着系统遇到新的场景而变化,由许多人(人类和模型)共同完成,其质量由下游任务的性能和安全性而不是模式的一致性来评判。.
常见的故障模式有三种。. 简洁性偏差 假定简短的提示会更好;实际上,法律硕士的表现往往是 更适合长而详细的上下文 并可在运行时选择相关性。. 背景崩溃 当重复重写将丰富的知识压缩成平淡的摘要时,就会出现这种情况;在一个 ACE 案例中,上下文从 18,282 个代币,精确度为 66.7% 至 122个代币,价格为57.1% 一次重写。还有 泛滥成灾 这将导致行为不一致、适应缓慢以及合规性暴露。传统的 MDM 在这方面帮不上什么忙。.
主上下文管理 (MCM)
什么是 MCM
主语境管理 是一种有纪律的方式 管理、版本和不断改进 驱动人工智能行为的情境。MCM 不把提示当作一次性的片段,而是将其视为 活剧本 积累机构知识、政策、战术、优势案例和工具配方,并在不失去记忆的情况下不断发展。.
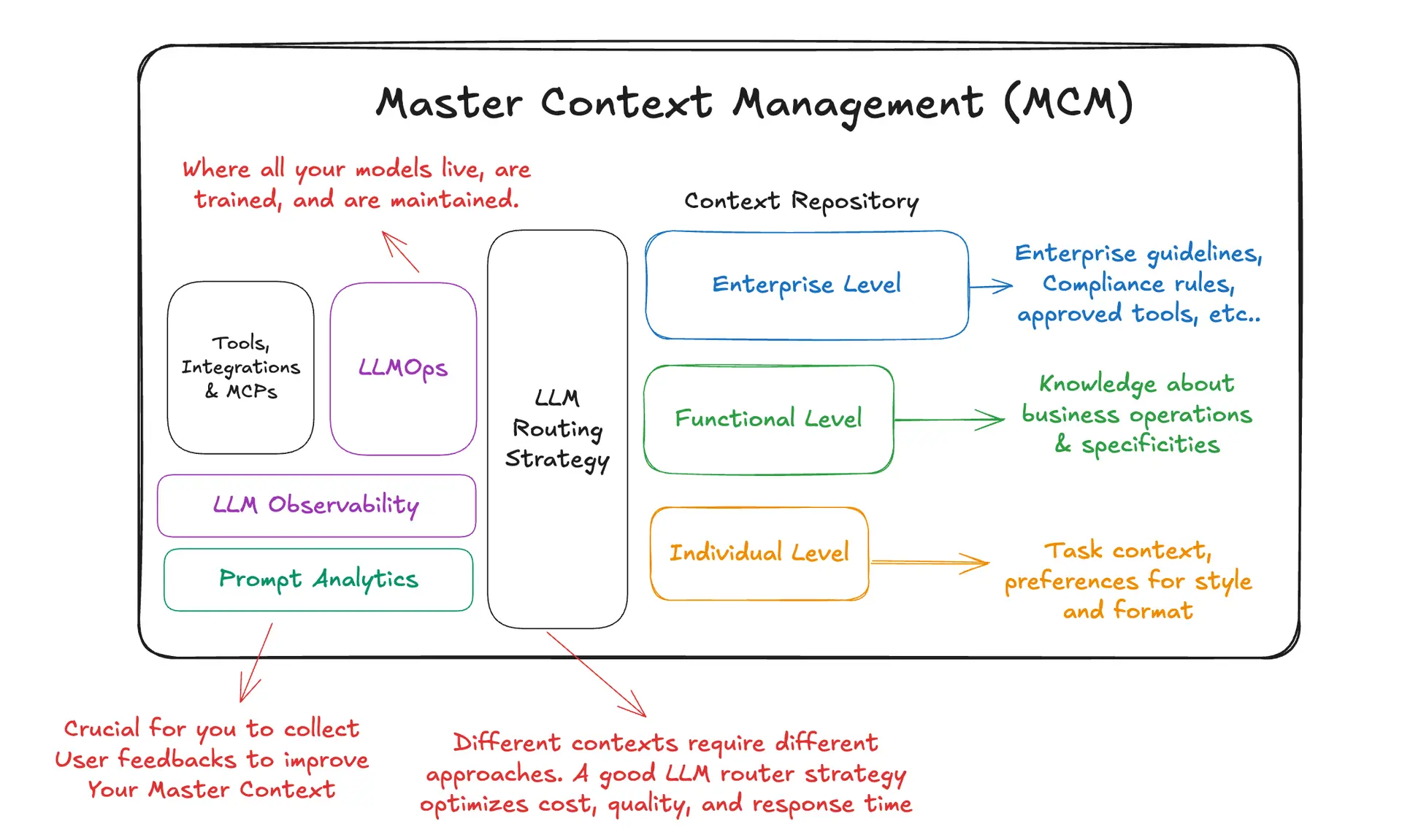
设计原则
MCM 依靠一些习惯来保持高质量和低漂移。首先 丰富的玩法 长上下文模型和推理优化(如 KV 缓存重用)使这一做法切实可行。第二、, 分工 在学习循环中:生成器执行任务并生成轨迹;反思器分析这些轨迹,以提取见解并诊断故障模式;策展器将见解转化为 有控制的窄幅更新. .第三,首选 三角洲编辑 到大的改写,因此改进是分项的、可测试的和可逆的。第四、, 从执行反馈中学习、, 成功/失败、工具输出和用户评价,因此,在没有标注 data 的情况下,上下文会得到改进。最后,实践 多波段细化 通过重温常见问题,加强指导,同时减少冗余。.
实用分类法
为了在重复使用和特殊性之间取得平衡,MCM 将上下文组织成三个自然交错的层次。. 企业背景 对整个组织的规则、合规性、安全态势和批准的工具进行编码。. 功能背景 掌握业务领域、程序、边缘案例、关键绩效指标和地区细微差别的操作知识。. 个人背景 为特定用户或工作流程量身定制任务设置和首选风格。这些功能可让团队为任何请求编写单一、连贯的操作手册,而无需重新发明轮子。.
核心能力
上下文存储和组成。. MCM 以存储离线资产(系统提示、指令模板、策略手册、工具指南)和在线资产(代理记忆、执行跟踪、可重复使用的对话片段)的存储库为起点。每个项目都带有元 data、所有者、领域、风险类别和沿袭关系,可按需组装成应用程序所需的上下文。.
路由和装配。. 轻量级路由层决定使用哪种模型,以及如何为给定请求组合企业、功能和个人上下文。这就需要在 成本、质量和延迟 明确且可重复,而不是隐藏在临时的提示编辑中。.
版本和实验。. 所有更改都作为 三角洲链. .团队可以运行并行变体,附加比较指标(准确性、策略一致性、延迟、幻觉率和业务影响),逐步推出变更,并在回归时自动恢复。结构化更新可减少适应延迟并降低风险。.
学习工作流程。. 期间 一代, 代理在当前指导下运行,并记录计划、工具调用、输入/输出和结果。在 反照, ,这些痕迹被分析为具体的指导,“在聚合之前翻阅 API 结果”、“在写入之前验证模式”、“在 Z 区域中策略 X 优先于 Y”。在 策展, 这样,洞察力就会变成带有 ID 和证据链接的可合并条目;重复的内容会被删除,格式化和防护措施会被执行,游戏手册也会随之增长,而不会崩溃。.
治理与风险。. MCM 为主要域指派管理者,定义建议更新的审批阈值,执行安全分类(PII、受管制、机密),并对谁在何时、为何更改了什么进行全面审计。在 data 中行之有效的治理理念--所有权、标准和升级路径--也能很好地应用到上下文中。.
可观察性和反馈。. 使用分析揭示了情境注入的位置及其表现。提示分析可识别对结果贡献最大的通道。漂移检测器可监测 “有害 ”计数器尺寸的突然收缩或峰值,以及崩溃的早期迹象。用户反馈成为改进循环的首要输入。.
整合与运作。. 最后,MCM 与日常的人工智能操作紧密结合:模型在 LLMOps 的规范下进行评估和部署;工具和集成作为受管能力公开;应用程序接口将组成的上下文注入代理和 RAG 系统;缓存和令牌经济功能使成本保持一致。.
一个简短的例子
想象一下,当忠诚度等级发生变化时,支持副驾驶员有时会计算错误退款。生成会产生失败案例的痕迹;反映会浮现出规则,“如果层级在过去 30 天内发生变化,则在退款前从生效日期重新定价”。整理添加了一个小的三角洲、两句话和一个工作示例,标记到退款部分,并提供失败跟踪的链接。下一次部署显示,首次接触解决问题的能力有了显著提高,而且无需广泛重写,必要时还可以轻松回滚。这就是 MCM 的实际效果: 可证明的小编辑积累成强大的行为.
MCM 的预防措施
有了这些做法,企业就能避免常见的陷阱:“当日提示 ”文化、大刀阔斧的改写抹杀了来之不易的知识、团队间的复制粘贴泛滥,以及无法解释哪些指导产生了特定结果。MCM 恢复 记忆、问责制和可重复性 对人工智能行为的影响。.
未来:自我完善的情境生态系统
通过 MCM,系统可以 从执行中学习 并根据任务成功/失败和工具结果等自然信号自动提出更新建议。ACE 证明,这种无标签学习可以带来巨大的收益(例如,ACE 可以通过对任务的成功/失败和工具结果等自然信号进行自动更新)、, +17.1 分 代理任务),这表明系统具有弹性,可在运行过程中不断改进。在 2010 年代,data 护城河最为重要;在 2020-2030 年代,data 护城河最为重要、, 背景护城河、, 编纂的诀窍将使领导者脱颖而出。随着操作手册的更新换代,知识管理有望复兴。 可审计、执行验证 资产、与知识图谱更紧密的联系以提供事实依据,以及通过明确、可逆的行为提高安全性。不断扩大的上下文窗口和推理优化使丰富的游戏手册在规模上更加经济。.
结论
MCM 并不取代 MDM,而是将其扩展到一个新的资产类别。. 清理 data 混乱的管理思想、监管、黄金源、分类法、生命周期和质量度量,现在也适用于 背景, 即决定人工智能如何推理和行动的指令和启发式方法。ACE 框架表明 将语境视为不断演变的剧本 并通过 生成→反映→整理 提高准确性 (+10.6 分和 +8.6 分),加速适应,并能仅通过执行信号进行自我改进。像对待主 data 一样对待上下文,通过基于三角洲的整理防止崩溃,利用您的治理基础,并将学习循环与强大的可观察性结合起来。掌握 MCM 的团队将享有更可靠的人工智能、更快的迭代速度和持久的优势;而那些随意管理上下文的团队则会重复 MDM 之前的无序发展,只是风险和成本更高。.

