


NOTÍCIAS / TECNOLOGIA AI
25 de novembro de 2020
Na Artefact, somos tão franceses que decidimos aplicar o aprendizado de máquina aos croissants. Este primeiro artigo de dois explica como decidimos usar o Catboost para prever as vendas de “viennoiseries”. Os recursos mais importantes que impulsionaram as vendas foram as últimas vendas semanais, o fato de o produto estar ou não em promoção e seu preço. Apresentaremos aos senhores alguns recursos interessantes de engenharia, inclusive a canibalização e por que às vezes é necessário atualizar a variável de destino.
O que é isso?
Na Artefact, somos tão franceses que decidimos aplicar o aprendizado de máquina aos croissants. Este primeiro artigo de dois explica como decidimos usar o Catboost para prever as vendas de “viennoiseries”. Os recursos mais importantes que impulsionaram as vendas foram as últimas vendas semanais, o fato de o produto estar ou não em promoção e seu preço.
Apresentaremos aos senhores alguns recursos interessantes de engenharia, incluindo canibalização e por que às vezes é necessário atualizar a variável-alvo. Escolhemos a precisão da previsão e os biais como métricas de avaliação. Nosso segundo artigo explicará como colocamos esse modelo em produção e algumas práticas recomendadas de ML Ops.
Para quem?
- Cientista Data, engenheiro ML ou amantes Data
Conclusões?
- Algoritmos de reforço para previsão de séries temporais
- Como responder a um problema de previsão com data com ruído
- Como lidar com as restrições operacionais na produção
Contexto
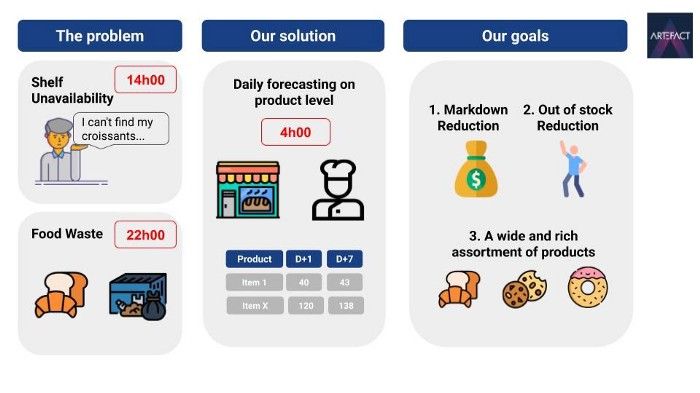
Recentemente, trabalhamos em um tópico realmente interessante e desafiador para um grande varejista na França: Como prever a demanda diária de produtos frescos perecíveis, como doces, incluindo nossos amados croissants.
Esse varejista estava enfrentando um problema clássico de cadeia de suprimentos: todos os dias, seus padeiros precisam assar uma certa quantidade de produtos frescos e perecíveis: croissants, pães de chocolate, baguetes, tortas de limão etc. A maioria desses produtos não dura mais de um dia e, se não forem vendidos, são considerados como receita perdida. Por outro lado, se não houver disponibilidade na prateleira durante o dia, os consumidores ficarão insatisfeitos e haverá perda de dinheiro. O desafio é prever em nível diário, com sete dias de antecedência, a quantidade de cada produto perecível para cada loja. Como resultado, esse projeto teve como objetivo melhorar a disponibilidade nas prateleiras e, ao mesmo tempo, reduzir o desperdício de alimentos.
Para prever as vendas com alguns dias de antecedência, já era usada uma solução interna que utilizava medidas estatísticas simples. No entanto, depois de nos reunirmos com os gerentes da padaria, entendemos que havia um espaço claro para aprimoramento, aproveitando mais data e recursos como efeitos de sazonalidade, clima, feriados, efeitos de substituição de produtos etc. Assim, decidimos usar a solução atual como linha de base e experimentar algoritmos mais recentes para melhorar a precisão da previsão.
E para concluir esta introdução, uma ilustração do desafio e do que queremos alcançar.
Desenvolvimento de modelos
Agora que temos um problema bem definido e alguns objetivos a serem alcançados, podemos finalmente começar a escrever um bom código python em nossos notebooks - que comece a diversão!
Solicitação de Data
Como em qualquer projeto científico data, tudo começa com o data. Por experiência própria, recomendamos enfaticamente que o senhor solicite o data o mais rápido possível. Não tenha vergonha de pedir muitos data e, para cada fonte de data, certifique-se de identificar um referente, alguém com quem o senhor possa entrar em contato facilmente e fazer suas perguntas sobre a coleção de data ou sobre como o data está estruturado.
Graças às diversas reuniões, conseguimos fazer uma lista dos data que poderíamos usar:
- Transacional data incluindo o preço dos produtos.
- Promoções: uma lista de todas as promoções futuras e seus preços associados.
- Informações sobre o produto: diferentes características relacionadas aos produtos.
- Informações sobre a loja: localização, tamanho das lojas, concorrentes.
- Tempo data.
- Resíduos data: no final de cada dia, quantos produtos foram jogados fora.
Análise exploratória Data (EDA) e detecção de outliers
Depois que o data foi coletado, começamos a fazer algumas análises. Há sazonalidade em meu data? Uma tendência? Quantos produtos eu tenho? Eles são consistentes ao longo do tempo? Há produtos sazonais?
Ao plotar as diferentes séries temporais, também identificamos alguns recursos interessantes:
- Sazonalidade ao longo do ano, mas também durante a semana.
- Preço e se o produto está em promoção ou não.
- Canibalização de produtos e vendas adiadas durante a falta de estoque.
- O padrão de vendas difere de uma loja para outra.
Observe que criamos diferentes recursos relacionados ao preço. O preço absoluto, mas também os preços relativos em comparação com outros produtos da mesma subfamília, família ou loja. O preço relativo é uma forma de quantificar a canibalização de preços entre produtos. Também criamos recursos que traduzem a variação de preço de um produto ao longo do tempo.
Para essas tarefas de previsão realistas, os demônios estão nos detalhes e é realmente importante procurar por exceções e anomalias e dedicar algum tempo para analisar seu data.
Mas, primeiro, por que deveríamos nos preocupar com a detecção de outliers? Por vários motivos: pode indicar que o data é ruim, erros nos ETLs, processos comerciais que o senhor não conhecia. Em segundo lugar, é muito provável que isso afete seu algoritmo e a parte de inferência, portanto, é definitivamente uma parte importante do desenvolvimento.
O senhor pode identificar outliers em diferentes momentos do projeto, seja durante a análise exploratória data (EDA) ou analisando os maiores erros de seus modelos.
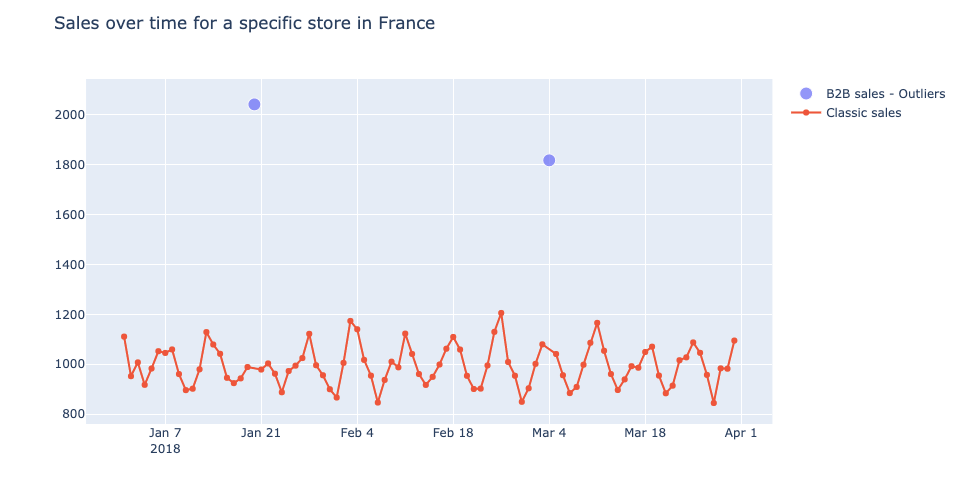
Ao fazer a EDA, detectamos alguns data estranhos, como vendas B2B, por exemplo, 1800 vendas de um único item em um único recibo de compra. Os valores atípicos relacionados aos preços, principalmente devido a erros manuais do caixa: preços negativos ou um croissant que custa 250 euros!
Percebemos que, às vezes, nossas previsões estavam totalmente erradas nos primeiros dias dos períodos de promoção. Após algumas análises, percebemos que isso se devia ao fato de a promoção ter sido lançada um dia antes ou depois do dia oficial. De fato, às vezes o gerente tomava alguma liberdade e decidia alterar o início ou o fim das promoções. Essas alterações podem ser detectadas e corrigidas no conjunto de treinamento data, mas podem levar a grandes erros de previsão. De fato, as promoções podem atingir volumes de 4 a 5 vezes maiores do que os de uma não promoção.
Aqui está uma lista de alguns outros exemplos interessantes de processos e mecanismos que descobrimos graças a essa análise e que o senhor pode encontrar em seus projetos:
- O sortimento nem sempre é consistente ao longo dos dias devido a restrições operacionais, erros e gerenciamento de estoque.
- Para algumas fontes do data, as datas indicadas eram os dias em que o data foi carregado, portanto, o senhor precisa remover um dia para obter o dia real.
Da previsão de vendas à previsão ideal de vendas
Um desafio nos levou a atualizar nossa variável de meta. Às vezes, devido a uma influência inesperada ou a uma previsão ruim, o departamento esperava uma falta de produtos antes do final do dia. Então, dois fenômenos podem ocorrer: o cliente que não consegue encontrar seu produto não compra nada ou compra um produto semelhante. Com base no histórico data, inferimos algumas leis de distribuição (estatísticas básicas) que nos ajudaram a modelar esse impacto e atualizamos nossa variável-alvo para não prever as vendas históricas, mas as vendas ideais para um determinado produto.
Essa atualização da variável de destino é complicada porque é realmente difícil saber se a atualização fez sentido. O senhor realmente melhorou a qualidade do data ou a piorou? Uma maneira de quantificar nosso impacto foi pegar as vendas sem falta de estoque e criar uma falsa escassez, por exemplo, remover todas as vendas após as 17 ou 18 horas e, em seguida, tentar reconstruir as vendas. Esse método nos ajuda a voltar a um problema supervisionado clássico que podemos avaliar objetivamente.
Como resultado, conseguimos prever as vendas ideais e evitar que nosso algoritmo aprendesse padrões de escassez.
Nossos modelos
Depois de limpar adequadamente nosso data, podemos finalmente testar e experimentar alguns modelos.
O senhor tem muitas possibilidades diferentes para lidar com um problema de previsão: abordagens estatísticas clássicas (SARIMA, suavização exponencial, Prophet etc.), abordagens de aprendizado de máquina (regressão linear, algoritmos de reforço) ou aprendizado profundo (RNN, LSTM, CNN). Como escolher a abordagem certa é uma questão complicada, mas aqui estão alguns elementos que nos ajudaram a escolher:
- Não uma, mas muitas séries temporais: ~10 000
- Séries temporais irregulares: pode acontecer de não haver vendas em alguns dias devido a escolhas do gerente, restrições comerciais ou operacionais.
- As promoções têm um impacto enorme e não são sazonais ou cíclicas.
- Observamos uma enorme correlação entre as vendas em J-0 e as vendas em J-7, J-14, J-21 para itens por loja e o estado de estar ou não em promoções.
- data exógenos têm um impacto sobre as vendas: preços, dias especiais, etc.
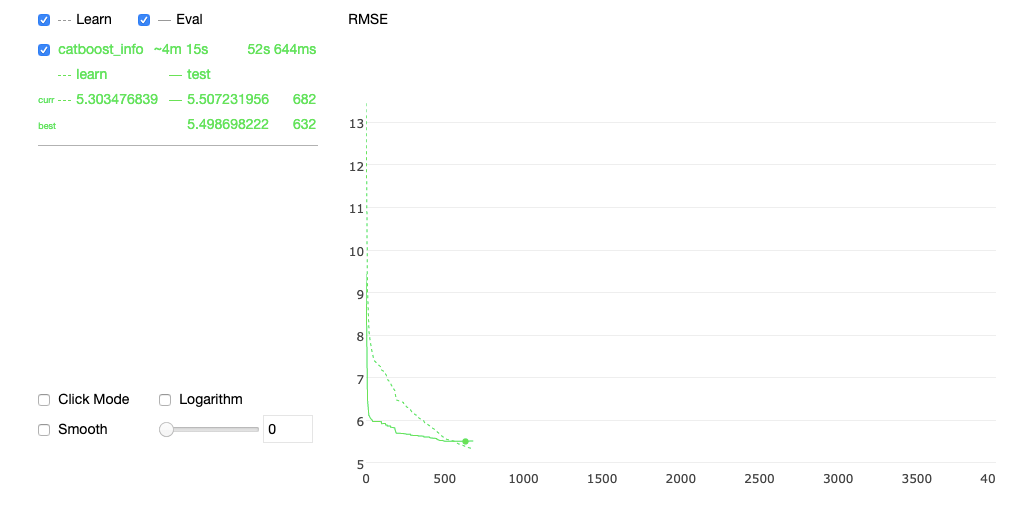
Por esses motivos, decidimos escolher o Catboost como modelo. O Catboost tem muitas vantagens, como lidar nativamente com valores categóricos e ausentes, pode lidar com muitos recursos, escalonar bem e inferir muitas séries temporais dentro do mesmo modelo. Além disso, ele fornece um bom gráfico durante o treinamento e se integra muito facilmente ao SHAP para a importância do recurso.
Aqui está, por exemplo, uma captura de tela do gráfico interativo do algoritmo durante seu treinamento:
No entanto, uma das desvantagens das abordagens de ML puro é a necessidade de codificar todos os recursos por conta própria, especialmente os relacionados ao tempo. Sem uma forte engenharia de recursos, esses algoritmos não conseguirão detectar os padrões de tempo. Além disso, eles só podem inferir um período de tempo fixo, ao contrário do Sarima ou do Prophet, em que o usuário pode especificar o número de dias a serem previstos usando o parâmetro periods.
Por fim, é preciso ter muito cuidado com o vazamento do data, especialmente quando o senhor constrói seu recurso de atraso.
Uma das principais características não era a defasagem semanal, mas a média das defasagens: D-7, D-14, D-21, ... etc. nas últimas seis semanas. De fato, a característica não regular de nossa série temporal, combinada com o uso de promoção de tempos em tempos, induz a uma sazonalidade difusa, daí o uso de uma média. É importante observar que apenas o uso dessa média como um modelo único já proporciona um desempenho muito bom!
Um modelo versus muitos modelos
Em resumo, usamos um algoritmo: Catboost, para prever todas as nossas 10.000 séries temporais, para cada produto e cada loja. Mas e se um item tiver um padrão de vendas realmente particular ou uma loja específica? O algoritmo identificaria e aprenderia esse padrão?
Essas perguntas nos levam à seguinte questão: devemos agrupar nossos produtos e lojas e treinar um algoritmo por agrupamento? Mesmo que o uso de algoritmos de árvore de decisão deva enfrentar esse desafio, observamos limitações em alguns casos específicos.
Os algoritmos de reforço são algoritmos iterativos, baseados em aprendizes fracos que se concentrarão em seus maiores erros. Obviamente, isso é um pouco simplificado demais, mas me ajuda a apontar uma de suas limitações. Se o senhor não normalizar a variável-alvo, o algoritmo se concentrará “apenas” nos produtos com grandes erros, que provavelmente serão aqueles com as maiores vendas. Como resultado, o algoritmo pode se concentrar mais nos produtos ou lojas com maior volume de vendas.
Não encontramos a maneira perfeita de enfrentar esse desafio, mas observamos algumas melhorias ao agrupar nossos produtos/lojas por família ou frequência de vendas.
Uma das vantagens de treinar vários algoritmos é a seguinte:
- Treinamento mais rápido
- Mais fácil de ajustar
- Mais fácil de depurar
- No caso de anomalias no data, nem todos os modelos darão errado
- Dependendo dos produtos, o senhor pode brincar com a função de perda e promover a escassez ou o excesso de produção
Mas, por outro lado, será mais difícil de manter!
No final, decidimos adotar essa abordagem, pois ela estava produzindo melhores resultados.
Como avaliar nosso modelo?
Discutimos muitos modelos e seus desempenhos nas seções anteriores. Mas como se avalia um algoritmo de previsão? Obviamente, isso é muito semelhante a qualquer problema de aprendizado de máquina, mas, ainda assim, tem suas próprias especificidades:
- Validação cruzada
Conforme mencionado anteriormente, um dos desafios da previsão de séries temporais é evitar o vazamento de data. Isso pode acontecer durante a criação de nossos recursos: defasagens, normalização de nossas variáveis, etc.
Mas isso também pode acontecer ao fazer a validação cruzada, dividida entre os conjuntos data de treinamento, validação e teste.
O senhor não pode usar o clássico train_test_split() do sklearn. Por quê? Imagine que seu conjunto de data seja as vendas de 2019. Se o senhor dividir aleatoriamente, treinará com data de janeiro, fevereiro, ..., dezembro de 2019 e seu data de teste terá vendas das mesmas datas! Como resultado, seu algoritmo treinará em padrões que ele não terá na produção, o que resulta em um problema de vazamento de data. Para resolver isso, há outras maneiras de dividir seu data, como a função TimeSeriesSplit() também do sklearn.
2. A escolha da métrica:
A previsão de séries temporais é um problema de regressão e, como resultado, podemos usar as métricas clássicas, como MSE, RMSE, mas outras também estão disponíveis:
- MAPE ou Precisão da previsão
- Um MAPE ponderado
- Distorção dinâmica do tempo
Otimizamos nosso algoritmo usando o RMSE, mas, para nos comunicarmos com nossos proprietários de negócios, usamos uma precisão de previsão ponderada:
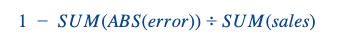
Primeiro, calculamos esse valor em nível de dia/loja e, em seguida, o agregamos por loja usando uma média ponderada, sendo os pesos as vendas por dia das diferentes lojas. Obviamente, essa métrica pode ser contestada, mas tem a vantagem de ter um valor para cada loja e, se em um dia o gerente realmente tiver um desempenho superior (ruim ou bom), ele não será superestimado. Além disso, o FA é uma métrica realmente interpretável que se relaciona com o negócio, ao contrário do RMSE.
Por fim, outra métrica interessante de se ter em mente é o biais, que apresenta a tendência geral do algoritmo de prever demais ou de menos. Dependendo do caso de negócios, o senhor pode querer promover uma ou outra. Em nosso caso, fizemos uma previsão ligeiramente acima do esperado para garantir que o produto estivesse na prateleira e manter nosso cliente satisfeito!
Palavras finais, alguns conselhos para qualquer projeto data
Achei que também seria bom compartilhar com os senhores algumas dicas e erros que cometemos em nível de projeto.
Antes de mais nada, como desenvolvemos nossos modelos, a engenharia de recursos?
Todas essas diferentes etapas e experimentos foram realizados em notebooks, mas o uso de notebooks não significa código sujo! Pelo contrário, é altamente recomendável que o senhor dedique tempo para escrever cadernos adequados com títulos, nomes apropriados, funções e eliminar linhas redundantes.
O uso de notebooks traz alguns desafios, especialmente quando muitos desenvolvedores trabalham juntos: conflitos no github, ausência de código replicável etc...
Aqui estão algumas dicas para reduzir esses problemas:
- Versão de seus notebooks usando remarcações
- Evite trabalhar juntos nos mesmos notebooks
- Se ainda assim o fizer, para lidar com conflitos no notebook, use o nbdev biblioteca de fastai
- Empacote funções comuns em arquivos .py para que todos usem as mesmas funções
- Para versionar seu experimento, use ferramentas como Fluxo de ML
- Evite print() e use um registrador em vez disso, registre apenas informações úteis. Confira scikit-lego que tem recursos muito legais, decoradores.
- Se o senhor realmente quiser imprimir coisas, tente a biblioteca rico o que o torna mais agradável e também pode ser usado como uma ferramenta de registro. Aqui está um demonstração rápida de rich por calmcode.io
Principais conclusões
Gostaríamos muito de compartilhar com os senhores nossos resultados, mas não nos foi permitido por motivos de privacidade, mas podemos dizer que, com essa metodologia, conseguimos:
- Ser tão bom quanto o seu melhor planejador de demanda
- Aumentar o FA de algumas lojas para até 30%
Mas, por outro lado, aqui está a lista dos nossos maiores aprendizados que, espero, ajudem o senhor a desenvolver sua própria solução:
- Dedique tempo para entender seu problema, definir um objetivo claro e mensurável, uma métrica de avaliação
- Se o senhor não encontrou anomalias... não procurou o suficiente!
- Acompanhe rigorosamente seus experimentos
- Escreva código limpo, especialmente em notebooks, isso facilitará muito sua vida na implantação
- Sempre pense que a produção e o vazamento de data são seus piores inimigos na previsão de séries temporais
- Comece com um escopo pequeno, com modelos simples, teste, falhe, aprenda, melhore e tenha sucesso!

