


ACTUALITÉS / TECHNOLOGIE DE L'AI
25 novembre 2020
Chez Artefact, nous sommes tellement français que nous avons décidé d'appliquer l'apprentissage automatique aux croissants. Ce premier article sur deux explique comment nous avons décidé d'utiliser Catboost pour prédire les ventes de “viennoiseries”. Les caractéristiques les plus importantes qui influencent les ventes sont les dernières ventes hebdomadaires, le fait que le produit soit en promotion ou non et son prix. Nous vous présenterons quelques caractéristiques techniques intéressantes, notamment la cannibalisation et les raisons pour lesquelles vous devez parfois mettre à jour votre variable cible.
Qu'est-ce que c'est ?
Chez Artefact, nous sommes tellement français que nous avons décidé d'appliquer l'apprentissage automatique aux croissants. Ce premier article sur deux explique comment nous avons décidé d'utiliser Catboost pour prédire les ventes de “viennoiseries”. Les caractéristiques les plus importantes qui influencent les ventes sont les dernières ventes hebdomadaires, le fait que le produit soit en promotion ou non et son prix.
Nous vous présenterons quelques caractéristiques techniques intéressantes, notamment la cannibalisation et les raisons pour lesquelles vous devez parfois mettre à jour votre variable cible. Nous avons choisi la précision des prévisions et le biais comme mesures d'évaluation. Notre deuxième article vous expliquera comment nous avons mis ce modèle en production et quelques bonnes pratiques de ML Ops.
Pour qui ?
- Data scientifique, ingénieur ML ou Data amoureux
À retenir ?
- Algorithmes de stimulation pour la prédiction de séries temporelles
- Comment répondre à un problème de prévision avec data bruyant ?
- Comment gérer les contraintes opérationnelles dans la production
Contexte
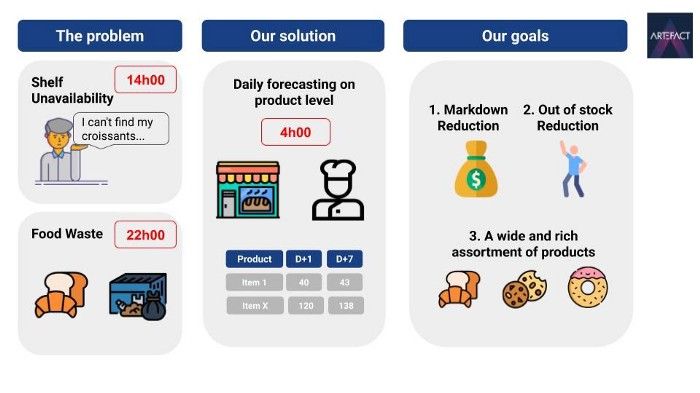
Nous avons récemment travaillé sur un sujet très intéressant et stimulant pour un grand détaillant en France : Comment prévoir la demande quotidienne de produits frais périssables tels que les pâtisseries, y compris nos chers croissants.
Ce détaillant était confronté à un problème classique de chaîne d'approvisionnement : chaque jour, ses boulangers doivent cuire une certaine quantité de produits frais et périssables : croissants, pains au chocolat, baguettes, tartes au citron, etc. La plupart de ces produits ne durent pas plus d'une journée, et s'ils ne sont pas vendus, ils sont considérés comme un manque à gagner. La plupart de ces produits ne durent pas plus d'une journée. S'ils ne sont pas vendus, ils sont considérés comme des pertes de revenus. Le défi consiste à prévoir quotidiennement, sept jours à l'avance, la quantité de chaque produit périssable pour chaque magasin. Ce projet vise donc à améliorer la disponibilité des produits en rayon tout en réduisant le gaspillage alimentaire.
Pour prévoir les ventes quelques jours à l'avance, une solution interne utilisant des mesures statistiques simples était déjà utilisée. Cependant, après avoir rencontré les responsables de la boulangerie, nous avons compris qu'il y avait une nette marge d'amélioration en tirant parti de plus de data et de caractéristiques telles que les effets de saisonnalité, la météo, les vacances, les effets de substitution de produits, etc. Nous avons donc décidé d'utiliser la solution actuelle comme référence et d'essayer des algorithmes plus récents pour améliorer la précision des prévisions.
Et pour conclure cette introduction, une illustration du défi et de ce que nous voulons réaliser.
Développement de modèles
Maintenant que nous avons un problème bien défini et des objectifs à atteindre, nous pouvons enfin commencer à écrire du beau code python dans nos carnets - que le plaisir commence !
Demande Data
Comme dans tout projet scientifique data, tout commence par data. D'après notre expérience, nous vous recommandons vivement de demander data le plus tôt possible. N'hésitez pas à demander beaucoup de data et, pour chaque source de data, veillez à identifier un référent, une personne que vous pouvez facilement contacter et à qui vous pouvez poser vos questions sur la collection de data ou sur la façon dont le data est structuré.
Grâce aux différentes réunions, nous avons pu dresser une liste des data que nous pouvions utiliser :
- Transactionnel data incluant le prix des produits.
- Promotions : une liste de toutes les promotions à venir et des prix qui y sont associés.
- Informations sur les produits : différentes caractéristiques relatives aux produits.
- Informations sur les magasins : emplacement, taille des magasins, concurrents.
- Météo data.
- Déchets data : à la fin de chaque journée, combien de produits ont été jetés.
Analyse exploratoire Data (EDA) et détection des valeurs aberrantes
Une fois le data collecté, nous avons commencé à l'analyser. Y a-t-il une saisonnalité dans mon data ? Une tendance ? Combien de produits ai-je ? Sont-ils constants dans le temps ? Y a-t-il des produits saisonniers ?
En traçant les différentes séries temporelles, nous avons également repéré quelques caractéristiques intéressantes :
- Saisonnalité sur l'année mais aussi en semaine.
- Prix et si le produit est en promotion ou non.
- Cannibalisation des produits et ventes différées en cas de rupture de stock.
- La structure des ventes varie d'un magasin à l'autre.
Notez que nous avons créé différentes fonctionnalités liées à la tarification. Le prix absolu, mais aussi les prix relatifs par rapport aux autres produits de la même sous-famille, famille ou magasin. Le prix relatif est un moyen de quantifier la cannibalisation des prix entre les produits. Nous avons également créé des fonctions traduisant la variation du prix d'un produit dans le temps.
Pour des tâches de prédiction aussi terre à terre, le diable se cache dans les détails et il est vraiment important de rechercher les valeurs aberrantes et les anomalies, de prendre le temps d'analyser votre data.
Mais tout d'abord, pourquoi devrions-nous nous préoccuper de la détection des valeurs aberrantes ? Pour de nombreuses raisons, cela peut indiquer une mauvaise data, des erreurs dans les ETL, des processus commerciaux que vous ne connaissiez pas. Deuxièmement, il est très probable que cela ait un impact sur votre algorithme et la partie inférence, il s'agit donc d'une partie importante du développement.
Vous pouvez repérer les valeurs aberrantes à différents moments du projet, soit au cours de l'analyse exploratoire data (EDA), soit en analysant les erreurs les plus importantes de vos modèles.
En effectuant l'AED, nous avons repéré quelques data étranges telles que les ventes B2B, par exemple 1800 ventes d'un seul article sur un seul reçu d'achat. Des valeurs aberrantes liées à la tarification, principalement dues à des erreurs manuelles de la caissière : des prix négatifs ou un croissant coûtant 250 euros !
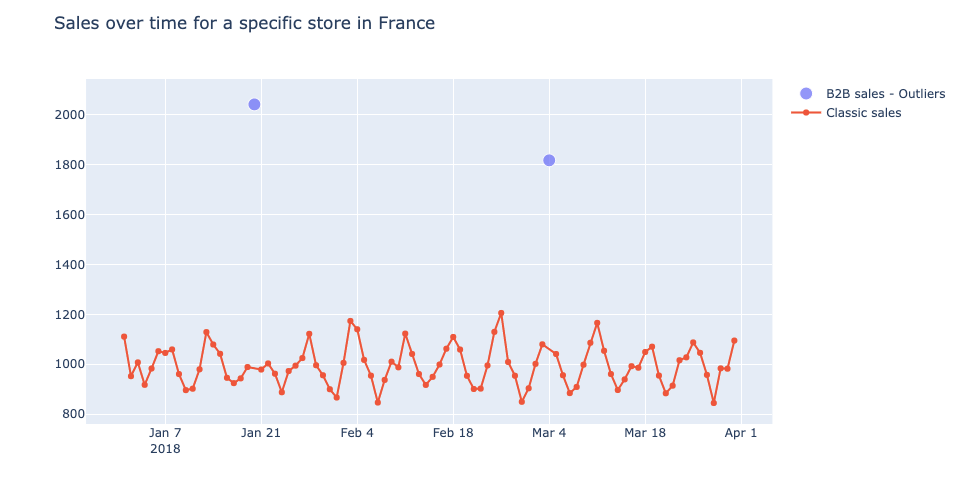
Nous avons remarqué que nos prédictions étaient parfois totalement fausses les premiers jours des périodes de promotion. Après analyse, nous avons constaté que cela était dû au fait que la promotion était lancée un jour avant ou après le jour officiel. En effet, il arrive que le responsable prenne une certaine liberté et décide de modifier le début ou la fin des promotions. Ces changements peuvent être repérés et corrigés dans le jeu d'entraînement data mais peuvent conduire à de grosses erreurs de prédiction. En effet, les promotions peuvent atteindre des volumes 4 à 5 fois plus importants qu'en l'absence de promotion.
Voici une liste d'autres exemples intéressants de processus et de mécanismes que nous avons découverts grâce à cette analyse et que vous trouverez peut-être dans vos projets :
- L'assortiment n'est pas toujours cohérent d'un jour à l'autre en raison de contraintes opérationnelles, d'erreurs, de la gestion des stocks.
- Pour certaines sources data, les dates indiquées correspondent aux jours où le data a été chargé, de sorte que vous devez retirer un jour pour obtenir le jour réel.
De la prédiction des ventes à la prédiction optimale des ventes
Un défi nous a amenés à mettre à jour notre variable cible. Parfois, en raison d'une influence inattendue ou d'une mauvaise prévision, le département s'attendait à une pénurie de produits avant la fin de la journée. Deux phénomènes peuvent alors se produire : le client ne trouvant pas son produit n'achète rien, ou achète un produit similaire. Sur la base de l'historique data, nous avons déduit quelques lois de distribution (statistiques de base) qui nous ont permis de modéliser cet impact et de mettre à jour notre variable cible afin de prédire non pas les ventes historiques mais les ventes optimales pour un produit particulier.
Cette mise à jour de la variable cible est délicate car il est vraiment difficile de savoir si la mise à jour a eu un sens. Avez-vous réellement amélioré la qualité du data ou l'avez-vous détériorée ? Une façon de quantifier notre impact a été de prendre les ventes sans rupture de stock et de créer une fausse pénurie, par exemple en supprimant toutes les ventes après 17 ou 18 heures, puis en essayant de reconstituer les ventes. Cette méthode nous permet de revenir à un problème classique supervisé que nous pouvons évaluer objectivement.
Nous avons ainsi pu prédire les ventes optimales et éviter que notre algorithme n'apprenne des schémas de pénurie.
Nos modèles
Après avoir correctement nettoyé notre data, nous pouvons enfin tester et essayer quelques modèles.
Vous disposez d'un grand nombre de possibilités pour résoudre un problème de prévision : approches statistiques classiques (SARIMA, lissage exponentiel, prophète, etc.), approches d'apprentissage automatique (régression linéaire, algorithmes de boosting) ou apprentissage profond (RNN, LSTM, CNN). Comment choisir la bonne approche est une question délicate, voici quelques éléments qui nous ont aidés à faire notre choix :
- Pas une mais plusieurs séries temporelles : ~10 000
- Séries temporelles irrégulières : il peut arriver qu'il n'y ait pas de ventes pendant certains jours en raison de choix du gestionnaire, de contraintes commerciales ou opérationnelles.
- Les promotions ont un impact considérable et ne sont ni saisonnières ni cycliques.
- Nous avons observé une forte corrélation entre les ventes à J-0 et les ventes à J-7, J-14, J-21 pour les articles par magasin et le fait d'être en promotion ou non.
- Les éléments exogènes data ont un impact sur les ventes : prix, journées spéciales, etc.
Pour ces raisons, nous avons décidé de choisir Catboost comme modèle. Catboost présente de nombreux avantages tels que la gestion native des valeurs catégorielles et manquantes, la prise en charge d'un grand nombre de caractéristiques, une bonne mise à l'échelle et la possibilité d'inférer un grand nombre de séries temporelles au sein d'un même modèle. De plus, il fournit un joli tracé pendant l'apprentissage et s'intègre très facilement avec SHAP pour l'importance de la caractéristique.
Voici par exemple une capture d'écran du tracé interactif de l'algorithme pendant son apprentissage :
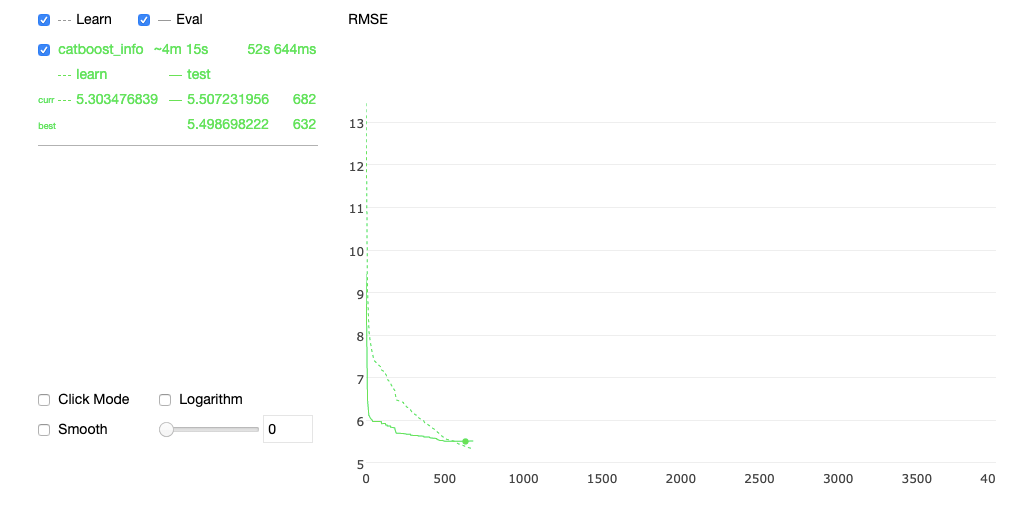
Néanmoins, l'un des inconvénients des approches de ML pures est la nécessité de coder vous-même toutes les caractéristiques, en particulier celles liées au temps. Sans une forte ingénierie des caractéristiques, ces algorithmes seront incapables d'identifier les schémas temporels. De plus, ils ne peuvent déduire qu'une période de temps fixe, contrairement à Sarima ou Prophet, où vous pouvez spécifier le nombre de jours à prévoir à l'aide du paramètre periods.
Enfin, vous devez faire très attention aux fuites de data, en particulier lorsque vous construisez votre dispositif de décalage.
L'une des principales caractéristiques n'était pas le décalage hebdomadaire mais la moyenne des décalages : J-7, J-14, J-21, ... etc. des six dernières semaines. En effet, la caractéristique non régulière de nos séries temporelles, combinée à l'utilisation de promotions de temps à autre, induit une saisonnalité floue, d'où l'utilisation d'une moyenne. Il est important de noter que l'utilisation de cette moyenne comme modèle unique donne déjà de très bonnes performances !
Un modèle ou plusieurs modèles
En résumé, nous avons utilisé un algorithme : Catboost, pour prédire l'ensemble de nos 10 000 séries temporelles, pour chaque produit et chaque magasin. Mais qu'en est-il si un article a un modèle de vente vraiment particulier, ou un magasin spécifique ? L'algorithme pourrait-il identifier et apprendre ce modèle ?
Ces questions nous amènent à nous demander si nous ne devrions pas regrouper nos produits et nos magasins et former un algorithme par groupe. Même si l'utilisation d'algorithmes d'arbres de décision devrait permettre de relever ce défi, nous avons observé des limites dans certains cas spécifiques.
Les algorithmes de stimulation sont des algorithmes itératifs, basés sur des apprenants faibles qui se concentrent sur leurs plus grosses erreurs. C'est évidemment un peu trop simplifié, mais cela me permet de souligner l'une de leurs limites. Si vous n'avez pas normalisé votre variable cible, votre algorithme se concentrera “uniquement” sur les produits présentant de grosses erreurs, qui sont plus susceptibles d'être ceux dont les ventes sont les plus importantes. Par conséquent, l'algorithme peut se concentrer davantage sur les produits ou les magasins dont le volume de ventes est plus important.
Nous n'avons pas trouvé la solution idéale pour relever ce défi, mais nous avons observé quelques améliorations en regroupant nos produits/magasins par famille ou par fréquence de vente.
L'un des avantages de l'apprentissage de plusieurs algorithmes est qu'il est possible d'utiliser plusieurs algorithmes :
- Une formation plus rapide
- Plus facile à ajuster
- Plus facile à déboguer
- En cas d'anomalies du data, tous les modèles ne fonctionneront pas de la même manière.
- Selon les produits, vous pouvez jouer avec la fonction de perte et favoriser la pénurie ou la surproduction.
Mais d'un autre côté, il sera plus difficile à maintenir !
Finalement, nous avons décidé d'adopter cette approche car elle donnait de meilleurs résultats.
Comment évaluer notre modèle ?
Nous avons discuté d'un grand nombre de modèles et de leurs performances dans les sections précédentes. Mais comment évaluer un algorithme de prévision ? Il est évident que ce problème est très similaire à tous les autres problèmes d'apprentissage automatique, mais il a néanmoins ses propres spécificités :
- Validation croisée
Comme nous l'avons déjà mentionné, l'un des défis de la prévision des séries temporelles est d'éviter les fuites data. Cela peut se produire lors de la création de nos caractéristiques : retards, normalisation de nos variables, etc...
Mais cela peut également se produire lors de la validation croisée, en divisant les ensembles data de formation, de validation et de test.
Vous ne pouvez pas utiliser la méthode classique train_test_split() de sklearn. Pourquoi ? Imaginez que votre dataset soit les ventes de 2019, si vous divisez aléatoirement, vous vous entraînerez sur data de janv, fév, ..., décembre 2019 et votre data de test aura les ventes des mêmes dates ! Par conséquent, votre algorithme s'entraînera sur des modèles qu'il n'aura pas en production, d'où un problème de fuite de data. Pour résoudre ce problème, il existe d'autres façons de diviser votre data, comme la fonction TimeSeriesSplit() également de sklearn.
2. Le choix de la métrique :
La prévision des séries temporelles est un problème de régression, c'est pourquoi nous pouvons utiliser les mesures classiques telles que MSE, RMSE, mais d'autres mesures sont également disponibles, dont voici une liste non exhaustive :
- MAPE ou précision des prévisions
- Un MAPE pondéré
- Distorsion temporelle dynamique
Nous avons optimisé notre algorithme en utilisant le RMSE, mais pour communiquer avec nos propriétaires d'entreprise, nous avons utilisé une précision de prévision pondérée :
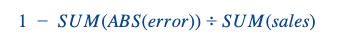
Nous l'avons d'abord calculée au niveau de la journée et du magasin, puis nous l'avons agrégée par magasin à l'aide d'une moyenne pondérée, les pondérations étant les ventes par jour des différents magasins. Cette mesure peut évidemment être contestée, mais elle présente l'avantage d'avoir une valeur pour chaque magasin et, si un jour le directeur réalise une performance vraiment supérieure (mauvaise ou bonne), elle n'est pas surestimée. En outre, l'AF est une mesure réellement interprétable qui parle à l'entreprise, contrairement à la RMSE.
Enfin, une autre mesure intéressante à garder à l'esprit est le biais, qui introduit la tendance générale de l'algorithme à sur-prédire ou à sous-prédire. En fonction de l'analyse de rentabilité, vous voudrez peut-être privilégier l'une ou l'autre de ces tendances. Dans notre cas, nous avons légèrement surestimé les prévisions afin d'être sûrs d'avoir le produit en rayon et de satisfaire nos clients !
En conclusion, quelques conseils pour les projets data
J'ai pensé qu'il serait également intéressant de partager avec vous quelques conseils et erreurs que nous commettons au niveau des projets.
Tout d'abord, comment avons-nous développé nos modèles, notre ingénierie des fonctionnalités ?
Toutes ces différentes étapes, expériences ont été réalisées dans des cahiers, mais l'utilisation de cahiers n'est pas synonyme de code sale ! Au contraire, nous vous recommandons vivement de prendre le temps d'écrire des carnets corrects avec des titres, des noms propres, des fonctions, et de factoriser les lignes redondantes.
L'utilisation de notebooks soulève quelques défis, en particulier lorsque de nombreux développeurs travaillent ensemble : conflits sur github, code non réplicable, etc...
Voici quelques conseils pour réduire ces problèmes :
- Versionnez vos carnets en utilisant les démarques
- Évitez de travailler ensemble sur les mêmes cahiers
- Si c'est encore le cas, pour gérer les conflits dans le bloc-notes, utilisez la fonction nbdev bibliothèque à partir de fastai
- Regrouper les fonctions communes dans des fichiers .py afin que tout le monde utilise les mêmes fonctions
- Pour versionner votre expérience, utilisez des outils tels que Flux ML
- Evitez print() et utilisez un logger à la place, n'enregistrez que les informations utiles. Vérifiez scikit-lego qui possède des fonctionnalités assez intéressantes, des décorateurs.
- Si vous voulez vraiment imprimer des documents, essayez la bibliothèque. riche ce qui le rend plus agréable et peut également être utilisé comme outil d'enregistrement. Ici, un Démonstration rapide de riche par calmcode.io
Principaux enseignements
Nous aurions aimé partager avec vous nos résultats, mais nous n'avons pas été autorisés à le faire pour des raisons de confidentialité :
- Soyez aussi bon que leur meilleur planificateur de la demande
- Augmenter le FA de certains magasins jusqu'à 30%
Mais d'un autre côté, voici la liste de nos plus grands apprentissages qui, je l'espère, vous aideront à développer votre propre solution :
- Prenez le temps de comprendre votre problème, de définir un objectif clair et mesurable, une mesure d'évaluation, etc.
- Si vous n'avez pas trouvé d'anomalies, c'est que vous n'avez pas assez regardé !
- Suivez rigoureusement vos expériences
- Écrivez du code propre, en particulier dans des carnets de notes, cela vous facilitera grandement la vie au moment du déploiement.
- Pensez toujours que la production et les fuites data sont votre pire ennemi dans la prévision des séries temporelles.
- Commencez par un périmètre restreint, avec des modèles simples, testez, échouez, apprenez, améliorez et réussissez !

