


NACHRICHTEN / KI-TECHNOLOGIE
25. November 2020
Wir bei Artefact sind so französisch, dass wir beschlossen haben, Machine Learning auf Croissants anzuwenden. Dieser erste von zwei Artikeln erklärt, wie wir beschlossen haben, Catboost zu verwenden, um die Verkäufe von “viennoiseries” vorherzusagen. Die wichtigsten Merkmale, die den Umsatz beeinflussen, sind die letzten wöchentlichen Verkäufe, die Tatsache, ob das Produkt im Sonderangebot ist oder nicht und der Preis. Wir stellen Ihnen einige nette technische Funktionen vor, darunter die Kannibalisierung und warum Sie Ihre Zielvariable manchmal aktualisieren müssen.
Was ist das?
Wir bei Artefact sind so französisch, dass wir beschlossen haben, Machine Learning auf Croissants anzuwenden. Dieser erste von zwei Artikeln erklärt, wie wir beschlossen haben, Catboost zu verwenden, um die Verkäufe von “viennoiseries” vorherzusagen. Die wichtigsten Merkmale, die den Umsatz beeinflussen, sind die letzten wöchentlichen Verkäufe, die Tatsache, ob das Produkt im Sonderangebot ist oder nicht, und der Preis.
Wir stellen Ihnen einige nette Funktionen vor, darunter Kannibalisierung und warum Sie manchmal Ihre Zielvariable aktualisieren müssen. Wir haben die Vorhersagegenauigkeit und die Biais als Bewertungsmetriken gewählt. In unserem zweiten Artikel werden wir Ihnen erklären, wie wir dieses Modell in die Produktion gebracht haben und einige Best Practices von ML Ops.
Für wen?
- Data Wissenschaftler, ML Ingenieur oder Data Liebhaber
Mitnehmen?
- Boosting-Algorithmen für die Vorhersage von Zeitreihen
- Wie Sie ein Prognoseproblem mit verrauschten data beantworten
- Wie man mit betrieblichen Einschränkungen in der Produktion umgeht
Kontext
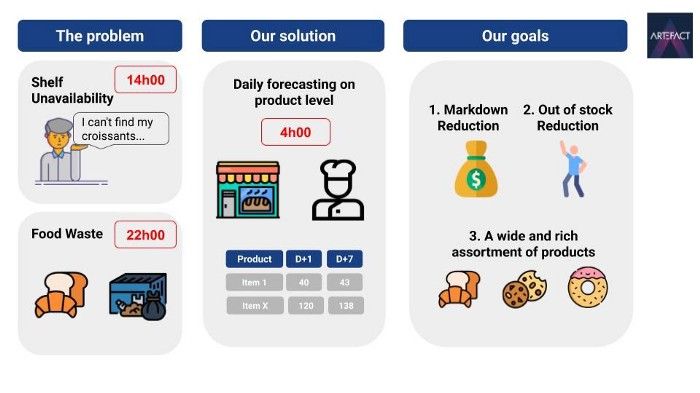
Wir haben kürzlich an einem wirklich interessanten und herausfordernden Thema für einen großen Einzelhändler in Frankreich gearbeitet: Wie kann man die tägliche Nachfrage nach frischen, verderblichen Produkten wie Gebäck, einschließlich unserer geliebten Croissants, vorhersagen?.
Dieser Einzelhändler stand vor einem klassischen Problem der Lieferkette: Jeden Tag müssen seine Bäcker eine bestimmte Menge frischer, leicht verderblicher Produkte backen: Croissants, Schokoladenbrote, Baguettes, Zitronenkuchen usw. Die meisten dieser Produkte sind nicht länger als einen Tag haltbar, und wenn sie nicht verkauft werden, gelten sie als verlorene Einnahmen. Wenn sie nicht verkauft werden, gelten sie als verlorene Einnahmen. Sind sie hingegen tagsüber nicht im Regal verfügbar, führt dies zu unzufriedenen Verbrauchern und einem Geldverlust. Die Herausforderung besteht darin, die Menge jedes verderblichen Produkts für jede Filiale sieben Tage im Voraus vorherzusagen. Ziel dieses Projekts war es daher, die Regalverfügbarkeit zu verbessern und gleichzeitig die Lebensmittelverschwendung zu reduzieren.
Um die Verkäufe einige Tage im Voraus zu prognostizieren, wurde bereits eine interne Lösung mit einfachen statistischen Maßnahmen verwendet. Nachdem wir uns jedoch mit den Managern der Bäckerei getroffen hatten, wurde uns klar, dass es ein deutliches Verbesserungspotenzial gab, indem wir mehr data und Funktionen wie saisonale Effekte, Wetter, Feiertage, Produktsubstitutionseffekte usw. nutzten. Wir haben daher beschlossen, die aktuelle Lösung als Basis zu verwenden und neuere Algorithmen auszuprobieren, um die Prognosegenauigkeit zu verbessern.
Und zum Abschluss dieser Einführung eine Illustration der Herausforderung und dessen, was wir erreichen wollen.
Entwicklung von Modellen
Jetzt, da wir ein gut definiertes Problem und einige Ziele haben, können wir endlich damit beginnen, schönen Python-Code in unseren Notizbüchern zu schreiben - der Spaß kann beginnen!
Data Anfrage
Wie bei jedem wissenschaftlichen data-Projekt beginnt alles mit data. Aus Erfahrung empfehlen wir dringend, die data-Anfrage so früh wie möglich zu stellen. Scheuen Sie sich nicht, viele data anzufordern und stellen Sie sicher, dass Sie für jede data-Quelle einen Ansprechpartner finden, an den Sie sich wenden können, um Ihre Fragen zur data-Sammlung oder zum Aufbau des data zu stellen.
Dank der verschiedenen Treffen konnten wir eine Liste der data erstellen, die wir verwenden konnten:
- Transaktionelle data einschließlich Preis der Produkte.
- Promotions: eine Liste aller zukünftigen Promotions und der dazugehörigen Preise.
- Produktinformation: verschiedene Eigenschaften der Produkte.
- Informationen zum Geschäft: Standort, Größe der Geschäfte, Wettbewerber.
- Wetter data.
- Abfall data: am Ende jedes Tages, wie viele Produkte weggeworfen wurden.
Explorative Data-Analyse (EDA) und Erkennung von Ausreißern
Sobald das data gesammelt war, haben wir mit der Analyse begonnen. Gibt es eine Saisonalität in meinem data? Ein Trend? Wie viele Produkte habe ich? Sind sie im Laufe der Zeit gleichbleibend? Gibt es saisonale Produkte?
Bei der Aufzeichnung der verschiedenen Zeitreihen haben wir auch einige interessante Merkmale entdeckt:
- Saisonalität im Laufe des Jahres, aber auch während der Woche.
- Preise und ob das Produkt im Angebot ist oder nicht.
- Kannibalisierung von Produkten und aufgeschobene Verkäufe bei Nichtverfügbarkeit.
- Das Verkaufsverhalten ist von Geschäft zu Geschäft unterschiedlich.
Beachten Sie, dass wir verschiedene Funktionen in Bezug auf die Preisgestaltung erstellt haben. Den absoluten Preis, aber auch die relativen Preise im Vergleich zu anderen Produkten in der gleichen Unterfamilie, Familie oder im gleichen Geschäft. Der relative Preis ist eine Möglichkeit, die Preiskannibalisierung zwischen Produkten zu quantifizieren. Wir haben auch Merkmale erstellt, die die Preisschwankungen eines Produkts im Laufe der Zeit darstellen.
Bei solch bodenständigen Vorhersageaufgaben steckt der Teufel im Detail und es ist wirklich wichtig, nach Ausreißern und Anomalien zu suchen, sich die Zeit zu nehmen, Ihr data zu crunchen.
Aber zunächst einmal: Warum sollten wir uns überhaupt die Mühe machen, Ausreißer zu erkennen? Dafür gibt es viele Gründe. Sie können auf schlechte data, Fehler in den ETLs oder Geschäftsprozesse hinweisen, die Sie nicht kannten. Zweitens ist es sehr wahrscheinlich, dass es sich auf Ihren Algorithmus und den Inferenzteil auswirkt, so dass es definitiv ein wichtiger Teil der Entwicklung ist.
Sie können Ausreißer zu verschiedenen Zeitpunkten des Projekts erkennen, entweder während der explorativen data-Analyse (EDA) oder durch Analyse der größten Fehler Ihrer Modelle.
Bei der EDA haben wir einige seltsame data entdeckt, wie z.B. B2B-Verkäufe, z.B. 1800 Verkäufe eines einzigen Artikels auf einem einzigen Kaufbeleg. Ausreißer im Zusammenhang mit der Preisgestaltung, die meist auf manuelle Fehler der Kassiererin zurückzuführen sind: negative Preise oder ein Croissant, das 250 Euro kostet!
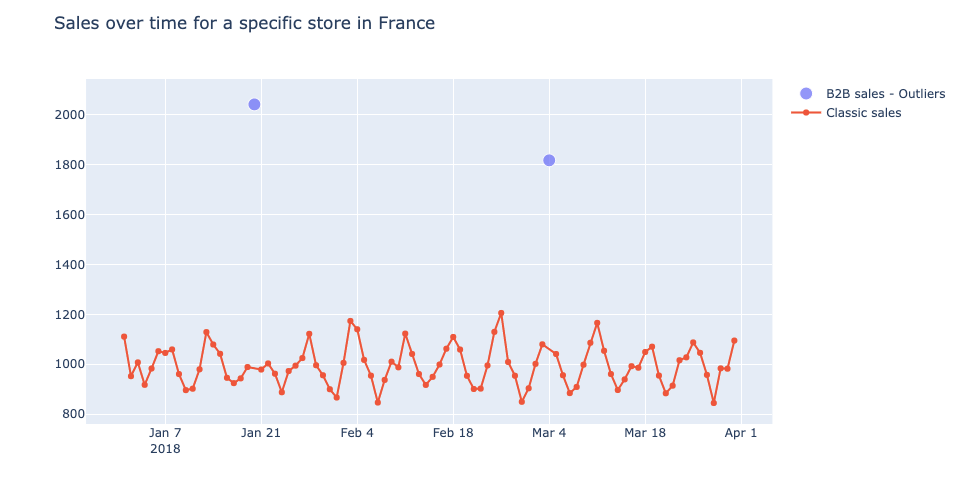
Wir haben festgestellt, dass unsere Vorhersagen an den ersten Tagen der Aktionszeiträume manchmal völlig daneben lagen. Nach einiger Analyse stellten wir fest, dass dies darauf zurückzuführen war, dass die Aktion einen Tag vor oder nach dem offiziellen Tag gestartet wurde. In der Tat hat sich der Manager manchmal die Freiheit genommen, den Beginn oder das Ende der Werbeaktionen zu ändern. Diese Änderungen können im Trainingsset data erkannt und korrigiert werden, können aber zu großen Fehlern bei der Vorhersage führen. In der Tat können Werbeaktionen ein 4- bis 5-mal größeres Volumen erreichen als eine Nicht-Werbeaktion.
Hier eine Liste mit weiteren interessanten Beispielen für Prozesse und Mechanismen, die wir dank dieser Analyse entdeckt haben und die Sie vielleicht in Ihren Projekten finden:
- Das Sortiment ist aufgrund von betrieblichen Zwängen, Fehlern und der Lagerverwaltung nicht immer über Tage hinweg konsistent.
- Bei einigen data-Quellen waren die angegebenen Daten die Tage, an denen das data geladen wurde. Daher müssen Sie einen Tag entfernen, um den tatsächlichen Tag zu erhalten.
Von der Absatzprognose zur optimalen Absatzprognose
Eine Herausforderung veranlasste uns, unsere Zielvariable zu aktualisieren. Manchmal erwartete die Abteilung aufgrund eines unerwarteten Einflusses oder einer schlechten Vorhersage einen Mangel an Produkten vor Ende des Tages. Dann können zwei Phänomene auftreten: Der Kunde, der sein Produkt nicht finden kann, kauft nichts oder er kauft ein ähnliches Produkt. Anhand der historischen data haben wir einige Verteilungsgesetze (grundlegende Statistiken) abgeleitet, die uns geholfen haben, diese Auswirkungen zu modellieren und unsere Zielvariable zu aktualisieren, um nicht die historischen Verkäufe, sondern die optimalen Verkäufe für ein bestimmtes Produkt vorherzusagen.
Diese Aktualisierung der Zielvariablen ist heikel, denn es ist wirklich schwer zu sagen, ob die Aktualisierung sinnvoll war. Haben Sie die Qualität des data wirklich verbessert oder verschlechtert? Eine Möglichkeit, unsere Auswirkungen zu quantifizieren, bestand darin, Verkäufe zu nehmen, die nicht auf Lager waren, und einen falschen Mangel zu erzeugen, z.B. alle Verkäufe nach 17 oder 18 Uhr zu entfernen und dann zu versuchen, die Verkäufe zu rekonstruieren. Diese Methode hilft uns, zu einem klassischen überwachten Problem zurückzukehren, das wir objektiv bewerten können.
So konnten wir die optimalen Verkäufe vorhersagen und vermeiden, dass unser Algorithmus Knappheitsmuster lernt.
Unsere Modelle
Nachdem wir unser data gründlich gereinigt haben, können wir endlich ein paar Modelle testen und ausprobieren.
Sie haben viele verschiedene Möglichkeiten, ein Prognoseproblem anzugehen: klassische statistische Ansätze (SARIMA, Exponential Smoothing, Prophet usw.), Ansätze des maschinellen Lernens (lineare Regression, Boosting-Algorithmen) oder Deep Learning (RNN, LSTM, CNN). Die Wahl des richtigen Ansatzes ist eine knifflige Frage. Hier sind einige Elemente, die uns bei der Auswahl geholfen haben:
- Nicht eine, sondern viele Zeitreihen: ~10 000
- Unregelmäßige Zeitreihen: Es kann vorkommen, dass aufgrund von Managerentscheidungen, geschäftlichen oder betrieblichen Zwängen an einigen Tagen keine Verkäufe getätigt werden.
- Werbeaktionen haben eine große Wirkung und sind nicht saisonal oder zyklisch.
- Wir haben eine enorme Korrelation zwischen den Umsätzen bei J-0 und den Umsätzen bei J-7, J-14, J-21 für Artikel pro Geschäft und dem Zustand, ob sie sich in einer Werbeaktion befinden oder nicht, festgestellt.
- Exogene data wirken sich auf den Verkauf aus: Preise, Sondertage usw.
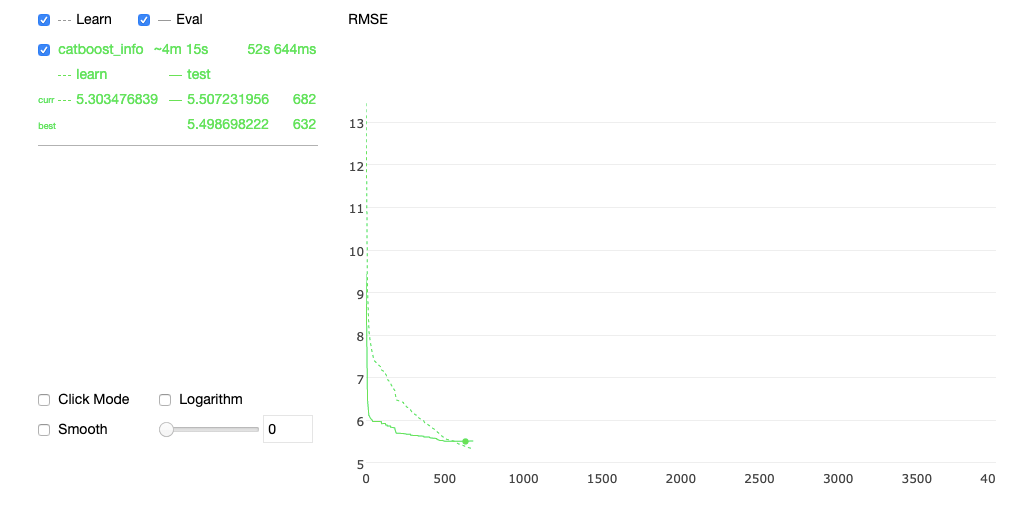
Aus diesen Gründen haben wir uns für Catboost als Modell entschieden. Catboost hat viele Vorteile, wie z.B. die native Verarbeitung von kategorischen und fehlenden Werten, die Verarbeitung vieler Merkmale, die gute Skalierung und die Ableitung vieler Zeitreihen innerhalb desselben Modells. Außerdem bietet es eine schöne Darstellung während des Trainings und lässt sich sehr leicht mit SHAP für die Bedeutung des Merkmals.
Hier zum Beispiel ein Screenshot der interaktiven Darstellung des Algorithmus während seines Trainings:
Einer der Nachteile der reinen ML-Ansätze ist jedoch die Notwendigkeit, alle Merkmale selbst zu kodieren, insbesondere die zeitlichen. Ohne ein starkes Feature-Engineering sind diese Algorithmen nicht in der Lage, die Zeitmuster zu erkennen. Außerdem können sie nur einen festen Zeitrahmen ableiten, im Gegensatz zu Sarima oder Prophet, bei denen Sie die Anzahl der zu prognostizierenden Tage über den Parameter Perioden festlegen können.
Schließlich müssen Sie sehr vorsichtig mit data Leckagen sein, besonders wenn Sie Ihr Lag-Feature bauen.
Eines der wichtigsten Merkmale war nicht die wöchentliche Verzögerung, sondern der Durchschnitt der Verzögerungen: D-7, D-14, D-21, ... usw. die letzten sechs Wochen. Die unregelmäßige Charakteristik unserer Zeitreihen in Verbindung mit dem Einsatz von Werbeaktionen von Zeit zu Zeit führt zu einer unscharfen Saisonalität, daher die Verwendung eines Durchschnitts. Es ist wichtig zu wissen, dass die Verwendung dieses Durchschnitts als einziges Modell bereits eine sehr gute Leistung erbringt!
Ein Modell gegen viele Modelle
Zusammenfassend haben wir einen Algorithmus verwendet: Catboost, um alle unsere 10 000 Zeitreihen für jedes Produkt und jedes Geschäft vorherzusagen. Aber was ist, wenn ein Artikel ein ganz bestimmtes Verkaufsmuster oder eine bestimmte Filiale hat? Würde der Algorithmus dieses Muster erkennen und lernen?
Diese Fragen führen uns zu der Frage, ob wir unsere Produkte und Geschäfte clustern und einen Algorithmus pro Cluster trainieren sollten. Auch wenn die Verwendung von Entscheidungsbaum-Algorithmen diese Herausforderung bewältigen sollte, haben wir in einigen spezifischen Fällen Einschränkungen festgestellt.
Boosting-Algorithmen sind iterative Algorithmen, die auf schwachen Lernern basieren, die sich auf ihre größten Fehler konzentrieren werden. Das ist natürlich etwas zu vereinfacht, aber es hilft mir, auf eine ihrer Einschränkungen hinzuweisen. Wenn Sie Ihre Zielvariable nicht normalisiert haben, wird sich Ihr Algorithmus “nur” auf die Produkte mit den größten Fehlern konzentrieren, die mit größerer Wahrscheinlichkeit auch die umsatzstärksten sind. Infolgedessen konzentriert sich der Algorithmus möglicherweise mehr auf die Produkte oder Geschäfte mit dem größten Umsatzvolumen.
Wir haben keine perfekte Lösung für dieses Problem gefunden, aber wir konnten einige Verbesserungen feststellen, indem wir unsere Produkte/Läden nach Familie oder Verkaufsfrequenz gruppiert haben.
Einer der Vorteile des Trainings mehrerer Algorithmen sind:
- Schneller zu trainieren
- Leichtere Feinabstimmung
- Leichtere Fehlersuche
- Im Falle von data-Anomalien gehen nicht alle Modelle schief
- Je nach Produkt können Sie mit der Verlustfunktion spielen und Knappheit oder Überproduktion fördern.
Auf der anderen Seite wird es aber auch schwieriger sein, sie zu pflegen!
Schließlich entschieden wir uns für diesen Ansatz, da er bessere Ergebnisse brachte.
Wie können Sie unser Modell bewerten?
In den vorangegangenen Abschnitten haben wir viele Modelle und ihre Leistungen besprochen. Aber wie bewertet man einen Prognosealgorithmus? Offensichtlich ist es ähnlich wie bei allen Problemen des maschinellen Lernens, aber dennoch hat es seine eigenen Besonderheiten:
- Kreuzvalidierung
Wie bereits erwähnt, besteht eine der Herausforderungen bei der Prognose von Zeitreihen darin, data-Lecks zu vermeiden. Das kann bei der Erstellung unserer Merkmale passieren: Lags, Normalisierung unserer Variablen usw...
Es kann aber auch bei der Kreuzvalidierung passieren, wenn Sie die data-Sets für Training, Validierung und Test aufteilen.
Sie können nicht die klassische train_test_split() von sklearn. Warum? Stellen Sie sich vor, Ihr data-Set sind die Verkäufe von 2019. Wenn Sie zufällig aufteilen, trainieren Sie auf data von Januar, Februar, ..., Dezember 2019 und Ihr Test data hat Verkäufe von denselben Daten! Infolgedessen wird Ihr Algorithmus mit Mustern trainieren, die er in der Produktion nicht haben wird, was zu einem data Leckproblem führt. Um dieses Problem zu lösen, gibt es andere Möglichkeiten, Ihre data aufzuteilen, z.B. die Funktion TimeSeriesSplit() auch von sklearn.
2. Die Wahl der Metrik:
Bei der Zeitreihenprognose handelt es sich um ein Regressionsproblem. Daher können wir die klassischen Metriken wie MSE, RMSE verwenden, aber es gibt auch noch andere, hier eine nicht erschöpfende Liste:
- MAPE oder Vorhersage-Genauigkeit
- Ein gewichteter MAPE
- Dynamisches Time Warping
Wir haben unseren Algorithmus anhand des RMSE optimiert, aber zur Kommunikation mit unseren Geschäftsinhabern eine gewichtete Prognosegenauigkeit verwendet:
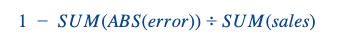
Wir haben ihn zunächst auf Tages-/Filialebene berechnet und ihn dann nach Filiale anhand eines gewichteten Durchschnitts aggregiert, wobei die Gewichtung den Tagesumsätzen der verschiedenen Filialen entspricht. Diese Kennzahl kann natürlich in Frage gestellt werden, aber sie hat den Vorteil, dass sie einen Wert für jede Filiale hat und dass sie nicht überschätzt wird, wenn der Manager an einem Tag wirklich überdurchschnittliche Leistungen erbringt (ob schlecht oder gut). Außerdem ist FA eine wirklich interpretierbare Kennzahl, die im Gegensatz zum RMSE etwas über das Geschäft aussagt.
Eine weitere interessante Metrik, die Sie im Auge behalten sollten, ist der Biais, der die allgemeine Tendenz des Algorithmus zur Über- oder Unterprognose angibt. Je nach Geschäftsvorfall können Sie das eine oder das andere vorziehen. In unserem Fall haben wir eine leicht überhöhte Vorhersage getroffen, um sicher zu gehen, dass das Produkt im Regal steht und unsere Kunden zufrieden sind!
Abschließende Worte, einige Ratschläge für alle data-Projekte
Ich dachte, es wäre auch schön, mit Ihnen einige Tipps und Fehler zu teilen, die wir auf Projektebene machen.
Zunächst einmal, wie haben wir unsere Modelle entwickelt, Feature Engineering?
All diese verschiedenen Schritte und Experimente wurden in Notizbüchern durchgeführt, aber die Verwendung von Notizbüchern bedeutet nicht, dass der Code unsauber ist! Im Gegenteil, wir empfehlen Ihnen dringend, sich die Zeit zu nehmen, ordentliche Notizbücher mit Titeln, Eigennamen und Funktionen zu schreiben und überflüssige Zeilen zu faktorisieren.
Die Verwendung von Notebooks bringt einige Herausforderungen mit sich, vor allem wenn viele Entwickler zusammenarbeiten: Konflikte auf Github, kein replizierbarer Code usw...
Hier sind einige Tipps, um diese Probleme zu verringern:
- Versionieren Sie Ihre Notizbücher mit Abschlägen
- Vermeiden Sie die gemeinsame Arbeit an denselben Notebooks
- Wenn Sie dies dennoch tun, verwenden Sie zur Behandlung von Konflikten in Notebooks die nbdev Bibliothek von fastai
- Packen Sie gängige Funktionen in .py-Dateien, so dass alle dieselben Funktionen verwenden.
- Verwenden Sie zur Versionierung Ihres Experiments Tools wie ML Flow
- Vermeiden Sie print() und verwenden Sie stattdessen einen Logger, der nur nützliche Informationen protokolliert. Prüfen Sie scikit-lego die ziemlich coole Funktionen hat, Dekorateure.
- Wenn Sie wirklich etwas ausdrucken möchten, gehen Sie in die Bibliothek. reich was es schöner macht und auch als Protokollierungswerkzeug verwendet werden kann. Hier ein Schnelle Demo von rich by calmcode.io
Wichtigste Erkenntnisse
Wir hätten unsere Ergebnisse gerne mit Ihnen geteilt, aber aus Gründen des Datenschutzes durften wir das nicht, aber wir können sagen, dass wir mit dieser Methodik in der Lage waren:
- Seien Sie so gut wie ihr bester Bedarfsplaner
- Erhöhen Sie die FA von einigen Geschäften auf bis zu 30%
Aber auf der anderen Seite, hier die Liste unserer wichtigsten Erkenntnisse, die Ihnen hoffentlich helfen, Ihre eigene Lösung zu entwickeln:
- Nehmen Sie sich die Zeit, Ihr Problem zu verstehen, definieren Sie ein klares, messbares Ziel, eine Bewertungsmetrik
- Knacken und untersuchen Sie Ihren data. Wenn Sie keine Anomalien gefunden haben, haben Sie nicht genug gesucht!
- Verfolgen Sie Ihre Experimente genauestens
- Schreiben Sie sauberen Code, vor allem in Notizbüchern, das wird Ihnen das Leben bei der Implementierung sehr erleichtern.
- Denken Sie immer an die Produktion: data-Leckagen sind Ihr schlimmster Feind bei Zeitreihenprognosen
- Beginnen Sie mit einem kleinen Umfang, mit einfachen Modellen, testen Sie, scheitern Sie, lernen Sie, verbessern Sie sich und haben Sie Erfolg!

