


新闻 / 人工智能技术
2020 年 11 月 25 日
在 Artefact,我们是如此法国,以至于我们决定将机器学习应用于羊角面包。本文是两篇文章中的第一篇,介绍了我们如何决定使用 Catboost 来预测 “羊角面包 ”的销售情况。影响销售额的最重要特征是最近一周的销售额、产品是否在促销以及价格。我们将向您介绍一些不错的功能工程,包括蚕食以及为什么有时需要更新目标变量。.
是什么?
在 Artefact,我们是如此法国,以至于我们决定将机器学习应用于羊角面包。本文是两篇文章中的第一篇,介绍了我们如何决定使用 Catboost 来预测 “羊角面包 ”的销售情况。影响销售额的最重要特征是最近一周的销售额、产品是否在促销以及价格。.
我们将向您介绍一些不错的功能工程,包括蚕食以及为什么有时需要更新目标变量。我们选择预测准确率和 biais 作为评估指标。第二篇文章将介绍我们如何将该模型投入生产,以及 ML Ops 的一些最佳实践。.
为了谁?
- Data 科学家、ML 工程师或 Data 爱好者
收获?
- 用于时间序列预测的提升算法
- 如何利用噪声 data 解答预测问题
- 如何处理生产中的操作限制
背景
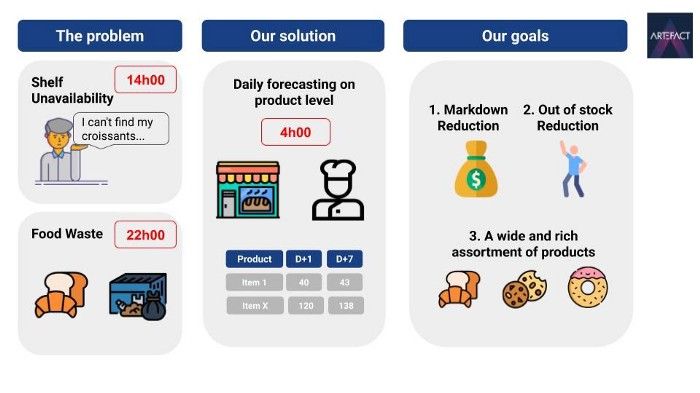
最近,我们为法国的一家大型零售商研究了一个非常有趣和具有挑战性的课题:如何预测糕点等新鲜易腐产品的每日需求量,包括我们钟爱的羊角面包。.
这家零售商面临着一个典型的供应链问题:他们的面包师每天都要烘焙一定数量的新鲜易腐产品:羊角面包、巧克力面包、法棍面包、柠檬派等。这些产品的保质期大多不超过一天,如果卖不出去,就会被视为收入损失。另一方面,如果一天内货架上没有现货,就会导致消费者不满和资金损失。挑战在于如何提前七天预测每家店每天每种易腐产品的数量。因此,该项目旨在提高货架可用性,同时减少食品浪费。.
为了提前几天预测销售情况,我们已经使用了一个使用简单统计方法的内部解决方案。然而,在与面包店经理会面后,我们了解到,利用更多的 data 和功能(如季节效应、天气、节假日、产品替代效应等),显然还有改进的余地。因此,我们决定将当前的解决方案作为基准,并尝试使用更先进的算法来提高预测准确性。.
最后,我想用一个例子来说明我们所面临的挑战和我们想要实现的目标。.
模型开发
现在,我们有了一个明确的问题和一些要实现的目标,我们终于可以开始在笔记本中编写一些漂亮的 python 代码了--让我们开始享受乐趣吧!
Data 申请
与任何 data 科学项目一样,一切都始于 data。根据经验,我们强烈建议尽快申请 data。不要羞于提出大量的 data,对于每个 data 来源,一定要确定一个参考者,一个您可以轻松联系并询问有关 data 收集或 data 结构的问题的人。.
由于召开了不同的会议,我们得以列出我们可以使用的 data 的清单:
- 交易 data,包括产品价格。.
- 促销:未来所有促销活动及其相关价格的列表。.
- 产品信息:与产品有关的各种特征。.
- 商店信息:地点、商店规模、竞争对手。.
- 天气 data。.
- 废物 data:每天结束时,有多少产品被扔掉。.
探索性 Data 分析(EDA)和异常值检测
收集到 data 数据后,我们开始进行分析。我的 data 有季节性吗?有趋势吗?我有多少产品?它们在一段时间内是否一致?是否有季节性产品?
通过绘制不同的时间序列,我们还发现了一些有趣的特征:
- 全年都有季节性,但一周内也有。.
- 定价以及产品是否在促销中。.
- 缺货期间的产品蚕食和延迟销售。.
- 销售模式因店而异。.
请注意,我们创建了与定价相关的不同功能。有绝对价格,也有与同一子系列、家族或商店中其他产品相比的相对价格。相对价格是量化产品之间价格蚕食的一种方法。我们还创建了一些功能,以反映一种产品在一段时间内的价格变化。.
对于这种脚踏实地的预测任务来说,细节决定成败,寻找异常值和异常点,花时间对 data 进行分析,这一点非常重要。.
但首先,我们为什么要费心进行离群值检测呢?原因很多,它可能预示着糟糕的 data、ETL 中的错误、你不知道的业务流程。其次,它确实很可能会影响你的算法和推理部分,所以它绝对是开发的重要部分。.
您可以在项目的不同阶段发现离群值,可以在探索性 data 分析 (EDA) 中发现,也可以通过分析模型的最大误差来发现。.
在进行 EDA 时,我们发现了一些奇怪的 data,如 B2B 销售,例如在一张采购收据上有 1800 件单品销售。与定价有关的异常值,主要是由于收银员的手工错误:负价格或一个牛角面包的价格为 250 欧元!
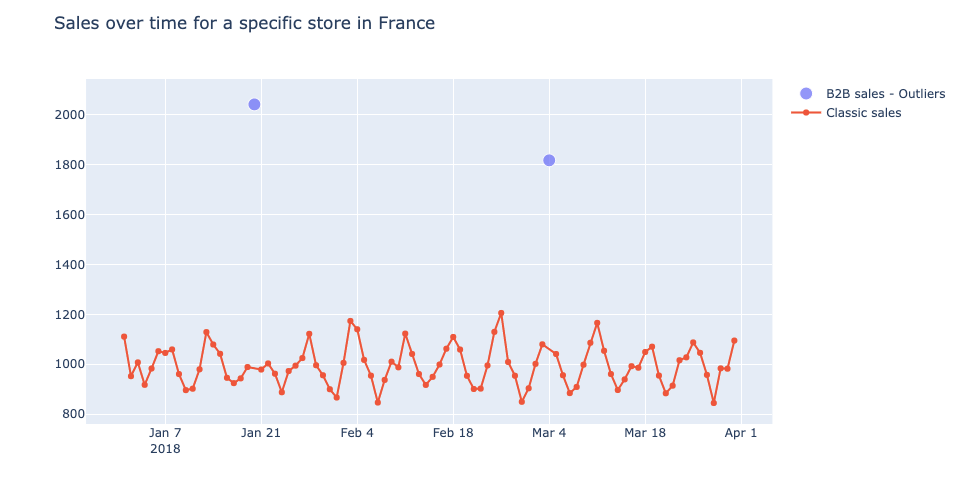
我们注意到,有时我们的预测在促销期的前几天会完全偏离。经过分析,我们发现这是因为促销活动是在正式促销日的前一天或后一天启动的。事实上,有时经理会擅自决定更改促销活动的开始或结束时间。这些变化可以在训练集 data 中被发现和修正,但会导致很大的预测误差。事实上,促销活动的销量可能是非促销活动的 4 到 5 倍。.
以下是我们通过分析发现的其他一些有趣的流程和机制示例,您可以在您的项目中找到:
- 由于操作限制、错误、库存管理等原因,产品种类并不总是每天都保持一致。.
- 对于某些 data 数据源,所显示的日期是 data 加载的日期,因此您需要去掉一天才能得到真正的日期。.
从销售预测到最佳销售预测
一项挑战促使我们更新目标变量。有时,由于意外影响或预测失误,部门预计下班前会出现产品短缺。这时就会出现两种现象:顾客找不到自己的产品,就什么也不买,或者购买类似的商品。根据 data 的历史数据,我们推断出一些分布规律(基本统计),帮助我们将这种影响模型化,并更新我们的目标变量,以便不预测历史销售额,而是预测特定产品的最佳销售额。.
目标变量的更新很棘手,因为很难知道更新是否有意义。您是真的提高了 data 的质量,还是使其变得更糟?量化我们的影响的一种方法是,提取没有缺货的销售额,制造虚假短缺,例如,删除下午 5 点或 6 点之后的所有销售额,然后尝试重建销售额。这种方法可以帮助我们回到一个可以客观评估的经典监督问题。.
因此,我们能够预测最佳销售额,并避免我们的算法学习短缺模式。.
我们的模型
在对 data 进行适当清洁后,我们终于可以测试和试用几款机型了。.
要解决预测问题,您有很多不同的选择:经典统计方法(SARIMA、指数平滑、先知等)、机器学习方法(线性回归、提升算法)或深度学习(RNN、LSTM、CNN)。如何选择正确的方法是一个棘手的问题,以下是帮助我们做出选择的一些要素:
- 不是一个时间序列,而是多个时间序列:~10 000
- 不规则的时间序列:由于经理的选择、业务或运营限制,可能会出现某些天没有销售额的情况。.
- 促销活动具有巨大的影响力,而且没有季节性或周期性。.
- 我们发现,J-0 的销售额与 J-7、J-14、J-21 的销售额之间存在着巨大的相关性。.
- 外来因素 data 对销售产生影响:价格、特殊日子等。.
基于这些原因,我们决定选择 Catboost 作为模型。Catboost 有很多优点,比如可以处理原生的分类值和缺失值,可以处理很多特征,扩展性好,并且可以在同一个模型中推断出很多时间序列。此外,它还能在训练时提供漂亮的曲线图,并能非常容易地与 SHAP 表示特征的重要性。.
下面是算法训练过程中的交互式绘图截图:
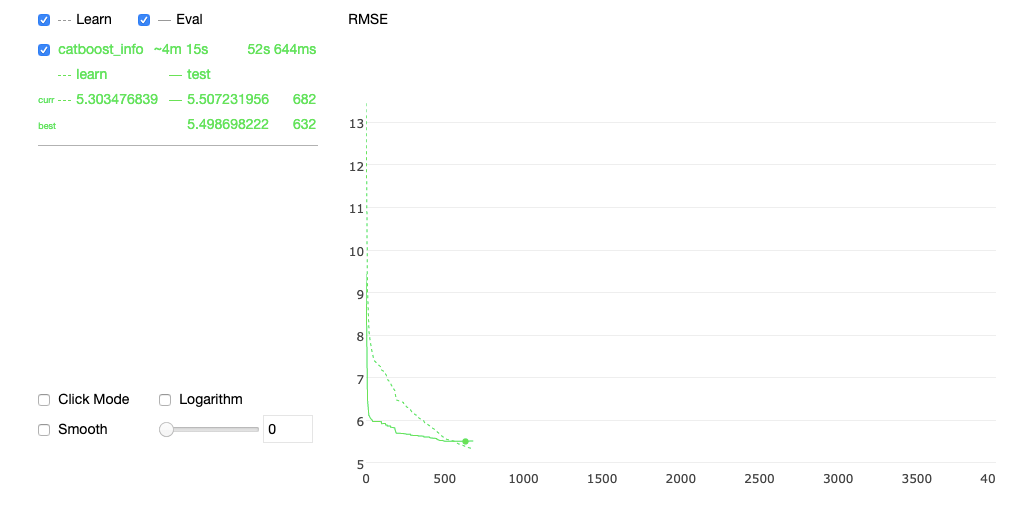
然而,纯 ML 方法的缺点之一是必须自行编码所有特征,尤其是与时间相关的特征。如果没有强大的特征工程,这些算法将无法捕捉时间模式。此外,它们只能推断出一个固定的时间框架,而不像 Sarima 或 Prophet 那样,可以使用周期参数指定预测的天数。.
最后,您必须非常小心 data 的泄漏,尤其是在构建滞后功能时。.
主要特点之一不是每周的滞后,而是滞后的平均值:D-7、D-14、D-21......等最近六周的平均值。事实上,我们的时间序列的非规则性特征与不时的促销活动相混合,导致了模糊的季 节性,因此使用了平均值。值得注意的是,仅仅使用平均值作为唯一的模型就已经取得了非常好的效果!
一种模式与多种模式
总而言之,我们使用了一种算法:Catboost)来预测每种产品和每家商店的所有 10,000 个时间序列。但是,如果某件商品或某家商店的销售模式非常特别呢?算法会识别并学习这种模式吗?
这些问题让我们想到,我们是否应该对产品、商店进行分组,并为每个分组训练一种算法?即使使用决策树算法可以应对这一挑战,我们也发现在某些特定情况下存在局限性。.
提升算法是一种迭代算法,以弱学习者为基础,将重点放在其最大的错误上。这显然有点过于简化,但有助于我指出其局限性之一。如果您没有将目标变量标准化,那么您的算法将 “只 ”关注误差大的产品,而误差大的产品更有可能是销量最大的产品。因此,算法可能会更关注销售量大的产品或商店。.
我们并没有找到解决这一难题的完美方法,但通过按产品系列或销售频率对产品/商店进行分组,我们看到了一些改进。.
训练多种算法的优势之一是
- 培训更快
- 更易于微调
- 更易于调试
- 如果 data 出现异常,并非所有型号都会出错
- 根据产品的不同,您可以利用损失函数,促进短缺或过量生产
但另一方面,维护起来也更具挑战性!
最后,我们决定采用这种方法,因为它能取得更好的效果。.
如何评估我们的模型?
在前面的章节中,我们讨论了很多模型及其性能。但如何评估预测算法呢?显然,这与任何机器学习问题都很相似,但它也有自己的特殊性:
- 交叉验证
如前所述,时间序列预测的挑战之一是避免 data 泄露。在创建特征时可能会出现这种情况:滞后、变量归一化等。
但在进行交叉验证时也可能出现这种情况,即在训练、验证和测试 datasets 之间进行分割。.
您不能使用经典的 train_test_split() 来自 sklearn。为什么?想象一下,您的 dataset 是 2019 年的销售额,如果随机拆分,您将训练 2019 年 1 月、2 月、......、12 月的 data,而您的测试 data 将包含相同日期的销售额!因此,您的算法将对生产中不存在的模式进行训练,从而产生 data 泄露问题。要解决这个问题,还有其他方法可以拆分 data,例如函数 T时间序列分割( ) 也来自 sklearn。.
2.度量标准的选择:
时间序列预测是一个回归问题,因此我们可以使用 MSE、RMSE 等经典指标,但也可以使用其他指标,在此不一一列举:
- MAPE 或预测精度
- 加权 MAPE
- 动态时间扭曲
我们使用 RMSE 对算法进行了优化,但为了与企业主沟通,我们使用了加权预测准确率:
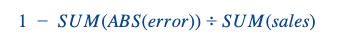
我们首先按日/店计算,然后用加权平均数按店汇总,加权数是不同店的日销售额。这个指标显然会受到质疑,但它的优点是每个门店都有一个值,如果有一天经理真的表现出色(很差或很好),也不会估计过高。此外,与 RMSE 不同的是,FA 是一个真正可解释的指标,它与业务息息相关。.
最后,还有一个值得注意的指标是 "预测值",它反映了算法预测过高或过低的总体趋势。根据不同的业务情况,您可能会选择其中之一。在我们的案例中,为了确保产品上架并让客户满意,我们略微推高了预测值!
最后,给任何 data 项目一些建议
我想,与大家分享一些小贴士和我们在项目层面上犯的错误也会很好。.
首先,我们是如何开发模型和特征工程的?
所有这些不同的步骤和实验都是在笔记本中实现的,但使用笔记本并不意味着代码肮脏!相反,我们强烈建议您花些时间在笔记本上写上适当的标题、适当的名称和函数,并删除多余的行。.
笔记本的使用带来了一些挑战,尤其是当许多开发人员一起工作时:github 上的冲突、没有可复制的代码等......
下面是一些减少这些问题的小贴士:
- 使用降价来调整笔记本版本
- 避免在同一笔记本上合作
- 如果您仍在使用,要处理笔记本中的冲突,请使用 nbdev 来自 fastai 的库
- 将常用函数打包到 .py 文件中,这样每个人都会使用相同的函数
- 使用以下工具对实验进行版本控制 ML 流量
- 避免使用 print(),而应使用日志记录器,只记录有用的信息。查看 scikit-lego 的装饰器功能非常酷。.
- 如果您真的想打印东西,可以去图书馆打印 丰富 这使它更美观,也可用作日志记录工具。这里有一个 快速演示 of rich by calmcode.io
主要收获
我们很想与大家分享我们的成果,但由于隐私原因,我们不能这样做,但我们可以说,有了这些方法,我们能够做到:
- 与他们最好的需求规划师一样优秀
- 将一些商店的 FA 提高到 30%
但另一方面,这里列出了我们最大的收获,希望能帮助你们制定自己的解决方案:
- 花时间了解您的问题,确定明确的可衡量目标和评估指标
- 如果您没有发现异常......那是因为您看得不够仔细!
- 严格跟踪实验
- 尤其是在笔记本中编写简洁的代码,这将使你的部署工作变得更加容易
- 在时间序列预测中,始终认为生产、data 泄漏是最大的敌人
- 从小范围、简单模型开始,测试、失败、学习、改进并取得成功!


