


NIEUWS / AI TECHNOLOGIE
25 november 2020
Bij Artefact zijn we zo Frans dat we besloten hebben Machine Learning toe te passen op croissants. In dit eerste van twee artikelen wordt uitgelegd hoe we hebben besloten Catboost te gebruiken om de verkoop van “viennoiseries” te voorspellen. De belangrijkste kenmerken voor de verkoop waren de laatste wekelijkse verkoop, of het product in promotie is of niet en de prijs. We zullen u een aantal leuke feature engineering presenteren, waaronder kannibalisatie en waarom u soms uw doelvariabele moet bijwerken.
Wat is het?
Bij Artefact zijn we zo Frans dat we besloten hebben Machine Learning toe te passen op croissants. In dit eerste van twee artikelen wordt uitgelegd hoe we hebben besloten Catboost te gebruiken om de verkoop van “viennoiseries” te voorspellen. De belangrijkste kenmerken voor de verkoop waren de laatste wekelijkse verkoop, of het product in promotie is of niet en de prijs.
We zullen u een aantal leuke functies presenteren, waaronder kannibalisatie en waarom u soms uw doelvariabele moet bijwerken. We hebben de voorspellingsnauwkeurigheid en de biais als evaluatieparameters gekozen. In ons tweede artikel leggen we uit hoe we dit model in productie hebben genomen en wat de best practices van ML Ops zijn.
Voor wie?
- Data wetenschapper, ML-ingenieur of Data liefhebbers
Meenemen?
- Boosting-algoritmen voor voorspelling van tijdreeksen
- Hoe een prognoseprobleem beantwoorden met lawaaierige data
- Hoe om te gaan met operationele beperkingen in de productie
Context
We hebben onlangs gewerkt aan een zeer interessant en uitdagend onderwerp voor een grote retailer in Frankrijk: Hoe de dagelijkse vraag naar verse, bederfelijke producten zoals gebak, waaronder onze geliefde croissants, te voorspellen.
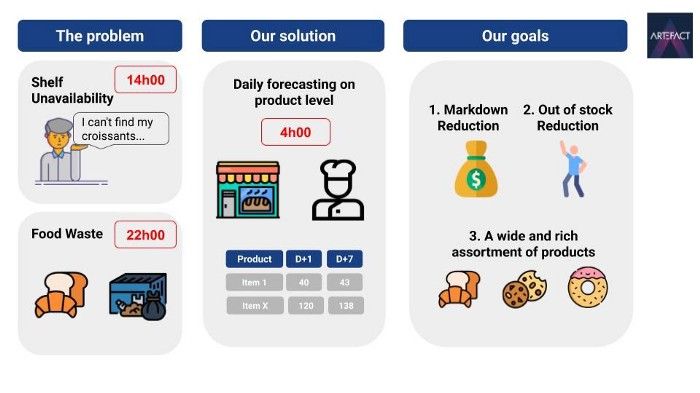
Deze detailhandelaar werd geconfronteerd met een klassiek probleem van de toeleveringsketen: elke dag moeten hun bakkers een bepaalde hoeveelheid verse, bederfelijke producten bakken: croissants, chocoladebroden, stokbroden, citroentaarten, enz. De meeste van deze producten zijn niet langer dan één dag houdbaar, en als ze niet verkocht worden, worden ze beschouwd als verloren inkomsten. Aan de andere kant zal een onbeschikbaarheid op het schap gedurende de dag leiden tot ontevreden consumenten en geldverlies. De uitdaging is om dagelijks zeven dagen van tevoren de hoeveelheid van elk bederfelijk product voor elke winkel te voorspellen. Het doel van dit project was dan ook om de schapbeschikbaarheid te verbeteren en tegelijkertijd voedselverspilling tegen te gaan.
Om de verkoop een paar dagen van tevoren te voorspellen, werd al een interne oplossing gebruikt die gebruik maakte van eenvoudige statistische maatstaven. Na een ontmoeting met de managers van de bakkerij begrepen we echter dat er duidelijk ruimte was voor verbetering door gebruik te maken van meer data en functies, zoals seizoensinvloeden, het weer, feestdagen, productsubstitutie-effecten, enz. We hebben daarom besloten om de huidige oplossing als basis te gebruiken en recentere algoritmen uit te proberen om de nauwkeurigheid van de voorspelling te verbeteren.
En om deze inleiding af te sluiten, een illustratie van de uitdaging en wat we willen bereiken.
Modelontwikkeling
Nu we een goed gedefinieerd probleem hebben en enkele doelen om te bereiken, kunnen we eindelijk beginnen met het schrijven van leuke pythoncode in onze notebooks - laat de pret beginnen!
Data verzoek
Zoals bij elk data wetenschapsproject begint alles met data. Uit ervaring raden we sterk aan om de data aanvraag zo snel mogelijk te doen. Wees niet verlegen om veel data aan te vragen en zorg ervoor dat u voor elke data bron een referent identificeert, iemand met wie u gemakkelijk contact kunt opnemen om uw vragen te stellen over de data verzameling of hoe de data is opgebouwd.
Dankzij de verschillende vergaderingen konden we een lijst opstellen van de data die we konden gebruiken:
- Transactionele data inclusief prijs van producten.
- Promoties: een lijst met alle toekomstige promoties en de bijbehorende prijzen.
- Productinformatie: verschillende kenmerken van de producten.
- Winkelinformatie: locatie, grootte van de winkels, concurrenten.
- Weer data.
- Afval data: hoeveel producten werden er aan het einde van elke dag weggegooid.
Verkennende Data analyse (EDA) en detectie van uitschieters
Toen de data verzameld was, zijn we begonnen met een analyse. Is er seizoensgebondenheid in mijn data? Een trend? Hoeveel producten heb ik? Zijn ze consistent in de tijd? Zijn er seizoensgebonden producten?
Door de verschillende tijdreeksen uit te zetten, zagen we ook enkele interessante kenmerken:
- Seizoensgebondenheid gedurende het jaar, maar ook tijdens de week.
- Prijzen en of het product in promotie is of niet.
- Kannibalisatie van producten en uitgestelde verkoop tijdens het niet op voorraad zijn.
- Het verkooppatroon verschilt van winkel tot winkel.
Merk op dat we verschillende functies met betrekking tot de prijs hebben gemaakt. De absolute prijs, maar ook de relatieve prijzen in vergelijking met andere producten in dezelfde subfamilie, familie of winkel. De relatieve prijs is een manier om kannibalisatie tussen producten te kwantificeren. We hebben ook functies gemaakt die de prijsvariatie van één product in de loop van de tijd vertalen.
Voor zulke nuchtere voorspellingstaken zit het venijn in de details en is het echt belangrijk om naar uitschieters en afwijkingen te zoeken, om de tijd te nemen om uw data te crunchen.
Maar eerst, waarom zouden we ons eigenlijk druk maken over het opsporen van uitschieters? Vele redenen, het kan wijzen op slechte data, fouten in de ETL's, bedrijfsprocessen die u niet kende. Ten tweede is het zeer waarschijnlijk dat het uw algoritme en het inferentiegedeelte beïnvloedt, dus het is zeker een belangrijk onderdeel van de ontwikkeling.
U kunt uitschieters op verschillende momenten van het project opsporen, tijdens de verkennende data analyse (EDA) of door de grootste fouten van uw modellen te analyseren.
Tijdens het uitvoeren van de EDA ontdekten we enkele vreemde data zoals B2B-verkopen, bijvoorbeeld 1800 verkopen van één artikel op één inkoopbon. Uitschieters met betrekking tot de prijsstelling, meestal als gevolg van handmatige fouten door de kassier: negatieve prijzen of een croissant die 250 euro kost!
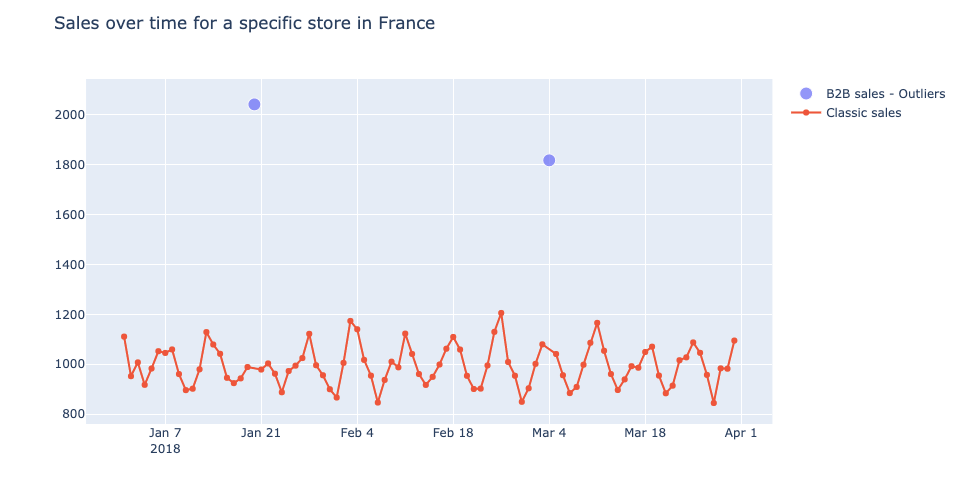
We merkten dat onze voorspellingen er soms helemaal naast zaten op de eerste dagen van de promotieperiodes. Na enige analyse merkten we dat dit te wijten was aan het feit dat de promotie één dag voor of na de officiële dag werd gelanceerd. Soms nam de manager inderdaad wat vrijheid en besloot om het begin of het einde van de promoties te veranderen. Deze veranderingen kunnen worden opgemerkt en hersteld in de trainingsset data, maar kunnen leiden tot grote voorspellingsfouten. Promoties kunnen namelijk volumes bereiken die 4 tot 5 keer groter zijn dan zonder promotie.
Hier volgt een lijst met enkele andere interessante voorbeelden van processen en mechanismen die we dankzij deze analyse hebben ontdekt en die u misschien in uw projecten tegenkomt:
- Het assortiment is niet altijd consistent over de dagen door operationele beperkingen, fouten, voorraadbeheer.
- Voor sommige data bronnen waren de aangegeven data de dagen waarop de data geladen was, waardoor u een dag moet verwijderen om de echte dag te krijgen.
Van verkoopvoorspelling naar optimale verkoopvoorspelling
Een uitdaging bracht ons ertoe om onze doelvariabele bij te werken. Soms verwachtte de afdeling door een onverwachte invloed of een slechte prognose een tekort aan producten voor het einde van de dag. Er kunnen zich dan twee fenomenen voordoen: de klant die zijn product niet kan vinden, koopt niets, of koopt een soortgelijk goed. Op basis van historische data leidden we enkele distributiewetten (basisstatistieken) af die ons hielpen om deze invloed te modelleren en onze doelvariabele aan te passen om niet de historische verkoop te voorspellen, maar de optimale verkoop voor een bepaald product.
Deze update van de doelvariabele is lastig omdat het echt moeilijk is om te weten of de update zinvol was. Is de kwaliteit van de data echt verbeterd of juist verslechterd? Een manier om onze impact te kwantificeren was om verkopen zonder uitverkochte voorraad te nemen en valse tekorten te creëren, bijvoorbeeld door alle verkopen na 17.00 of 18.00 uur te verwijderen en vervolgens te proberen de verkopen te reconstrueren. Deze methode helpt ons om terug te keren naar een klassiek probleem onder toezicht dat we objectief kunnen beoordelen.
Hierdoor konden we de optimale verkoop voorspellen en voorkomen dat ons algoritme tekortpatronen leerde.
Onze modellen
Nadat we onze data goed hebben schoongemaakt, kunnen we eindelijk een paar modellen testen en uitproberen.
U hebt veel verschillende mogelijkheden om een voorspellingsprobleem aan te pakken: klassieke statistische benaderingen (SARIMA, Exponential Smoothing, Prophet, enz.), machine-learning benaderingen (Lineaire Regressie, Boosting Algoritmen) of Deep Learning (RNN, LSTM, CNN). Hoe de juiste aanpak te kiezen is een lastige vraag, hier zijn enkele elementen die ons geholpen hebben om te kiezen:
- Niet één maar vele tijdreeksen: ~10 000
- Onregelmatige tijdreeksen: het kan gebeuren dat er sommige dagen geen verkoop is door keuzes van managers, bedrijfs- of operationele beperkingen.
- Promoties hebben een enorme impact en zijn niet seizoensgebonden of cyclisch.
- We zagen een enorme correlatie tussen de verkoop op J-0 en de verkoop op J-7, J-14, J-21 voor artikelen per winkel en de status van wel of niet in promoties.
- Exogene data hebben een invloed op de verkoop: prijzen, speciale dagen, enz.
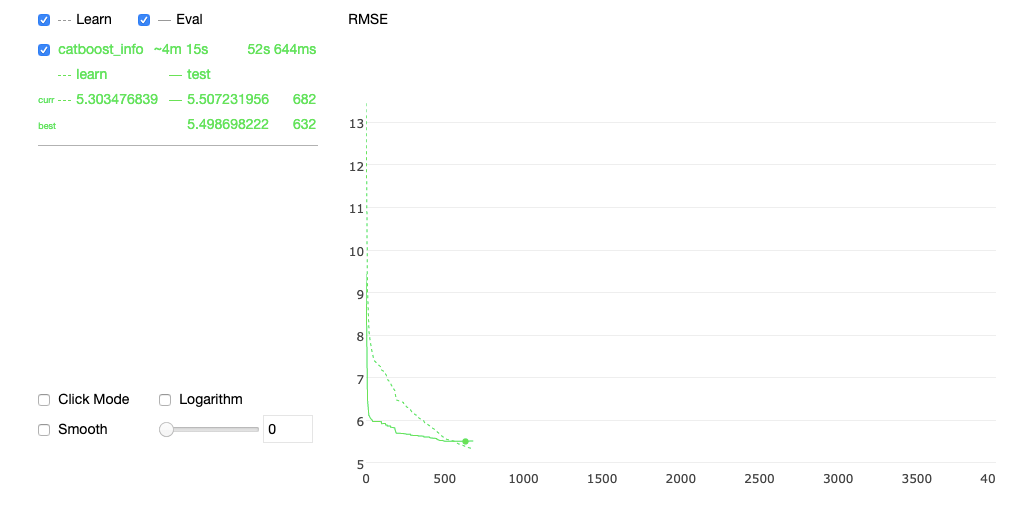
Om deze redenen hebben we besloten om Catboost als model te kiezen. Catboost heeft veel voordelen, zoals de natuurlijke verwerking van categorische en ontbrekende waarden, het kan veel kenmerken verwerken, het kan goed schalen en het kan veel tijdreeksen afleiden binnen hetzelfde model. Bovendien biedt het een mooie plot tijdens het trainen en integreert het heel gemakkelijk met SHAP voor het belang van de eigenschap.
Hier ziet u bijvoorbeeld een screenshot van de interactieve plot van het algoritme tijdens de training:
Een van de nadelen van pure ML-benaderingen is echter de noodzaak om alle kenmerken zelf te coderen, vooral die met betrekking tot tijd. Zonder sterke feature engineering zullen deze algoritmen niet in staat zijn om tijdspatronen te ontdekken. Bovendien kunnen ze alleen een vast tijdsbestek voorspellen, in tegenstelling tot Sarima of Prophet waar u het aantal te voorspellen dagen kunt opgeven met de parameter Perioden.
Tenslotte moet u heel voorzichtig zijn met data lekkage, vooral wanneer u uw vertragingsfunctie bouwt.
Een van de belangrijkste kenmerken was niet de wekelijkse vertraging, maar het gemiddelde van de vertragingen: D-7, D-14, D-21, ... etc laatste zes weken. Het feit dat onze tijdreeksen niet regelmatig zijn, gecombineerd met het gebruik van promotie van tijd tot tijd, leidt tot een vage seizoensgebondenheid, vandaar het gebruik van een gemiddelde. Het is belangrijk om op te merken dat alleen het gebruik van dit gemiddelde als uniek model al zeer goede prestaties geeft!
Eén model vs. veel modellen
Samengevat hebben we één algoritme gebruikt: Catboost, om al onze 10.000 tijdreeksen te voorspellen, voor elk product en elke winkel. Maar wat als een product een heel specifiek verkooppatroon heeft, of een specifieke winkel? Zou het algoritme dit patroon herkennen en leren?
Deze vragen leiden ons tot de vraag of we onze producten en winkels moeten clusteren en één algoritme per cluster moeten trainen. Zelfs als het gebruik van beslisboomalgoritmen deze uitdaging zou moeten aangaan, hebben we in enkele specifieke gevallen beperkingen geconstateerd.
Boosting-algoritmen zijn iteratieve algoritmen, gebaseerd op zwakke leerlingen die zich richten op hun grootste fouten. Het is natuurlijk een beetje overgesimplificeerd, maar het helpt me om op een van hun beperkingen te wijzen. Als u uw doelvariabele niet hebt genormaliseerd, zal uw algoritme zich “alleen” richten op producten met grote fouten, die waarschijnlijk de producten met de grootste verkoop zullen zijn. Als gevolg daarvan kan het algoritme zich meer richten op producten of winkels met een groter verkoopvolume.
We hebben niet de perfecte manier gevonden om dit probleem aan te pakken, maar we hebben enkele verbeteringen geconstateerd door onze producten/winkels te clusteren op basis van familie of verkoopfrequentie.
Een van de voordelen van het trainen van meerdere algoritmen zijn:
- Sneller te trainen
- Gemakkelijker af te stellen
- Eenvoudiger debuggen
- In het geval van data afwijkingen zullen niet alle modellen fout gaan
- Afhankelijk van de producten kunt u spelen met de verliesfunctie en tekorten of overproductie bevorderen
Maar aan de andere kant zal het een grotere uitdaging zijn om te onderhouden!
Uiteindelijk besloten we voor deze aanpak te kiezen, omdat dit betere resultaten opleverde.
Hoe evalueert u ons model?
In de vorige hoofdstukken hebben we veel modellen en hun prestaties besproken. Maar hoe evalueert men een voorspellingsalgoritme? Uiteraard is dit vergelijkbaar met elk ander machine-learningprobleem, maar toch heeft het zijn eigen specifieke kenmerken:
- Kruisvalidatie
Zoals eerder vermeld, is een van de uitdagingen van tijdreeksvoorspellingen het vermijden van data lekkage. Dit kan gebeuren tijdens het creëren van onze kenmerken: vertragingen, normalisatie van onze variabelen, enz.
Maar het kan ook gebeuren bij kruisvalidatie, gesplitst tussen train, validatie en test datasets.
U kunt de klassieke train_test_split() van sklearn. Waarom? Stel dat uw dataset de verkopen van 2019 zijn, als u willekeurig splitst, zult u trainen op data van januari, februari, ..., december 2019 en uw test data zal verkopen van dezelfde data hebben! Als gevolg daarvan zal uw algoritme trainen op patronen die hij niet in productie zal hebben, vandaar een data-lekprobleem. Om dat op te lossen zijn er andere manieren om uw data op te splitsen, zoals de functie TimeSeriesSplit() ook van sklearn.
2. De keuze van de metriek:
Tijdreeksvoorspelling is een regressieprobleem, en daarom kunnen we de klassieke meeteenheden zoals MSE, RMSE gebruiken, maar er zijn ook andere meeteenheden beschikbaar, hier een niet-uitputtende lijst:
- MAPE of voorspellingsnauwkeurigheid
- Een gewogen MAPE
- Dynamisch tijd vervormen
Wij optimaliseerden ons algoritme met RMSE, maar om met onze bedrijfseigenaars te communiceren gebruikten we een gewogen Forecast Accuracy:
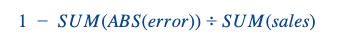
We hebben het eerst op dag-/winkelniveau berekend en vervolgens per winkel samengevoegd met behulp van een gewogen gemiddelde, waarbij de gewichten de verkopen per dag van de verschillende winkels zijn. Deze metriek kan natuurlijk worden aangevochten, maar het heeft het voordeel dat er een waarde voor elke winkel is, en als de manager op een dag echt beter presteert (slecht of goed), wordt het niet te hoog ingeschat. Bovendien is FA een echt interpreteerbare metriek die het bedrijf aanspreekt, in tegenstelling tot RMSE.
Een andere interessante metriek om in gedachten te houden is de biais, die de algemene trend van het algoritme weergeeft om te veel of te weinig te voorspellen. Afhankelijk van de business case kunt u het ene of het andere willen stimuleren. In ons geval hebben we een lichte overvoorspelling gedaan om er zeker van te zijn dat we het product op de plank hebben en onze klant tevreden houden!
Laatste woorden, wat advies voor alle data projecten
Het leek me ook leuk om wat tips en fouten die we op projectniveau maken met u te delen.
Ten eerste, hoe hebben we onze modellen, feature engineering, ontwikkeld?
Al deze verschillende stappen en experimenten werden uitgevoerd in notitieboeken, maar het gebruik van notitieboeken betekent niet dat er vuile code wordt geschreven! Integendeel, we raden ten zeerste aan om de tijd te nemen om goede notitieboeken te schrijven met titels, juiste namen, functies en overbodige regels te ontbinden in factoren.
Het gebruik van notebooks brengt een aantal uitdagingen met zich mee, vooral wanneer veel ontwikkelaars samenwerken: conflicten op github, geen repliceerbare code, enz...
Hier volgen enkele tips om deze problemen te verminderen:
- Verander uw notitieboeken met behulp van afprijzingen
- Vermijd om samen aan dezelfde notitieblokken te werken
- Als u dat nog steeds doet, gebruik dan voor het afhandelen van conflicten in het notitieblok de optie nbdev bibliotheek van fastai
- Verpak veelgebruikte functies in .py-bestanden, zodat iedereen dezelfde kan gebruiken
- Gebruik hulpmiddelen zoals ML Stroom
- Vermijd print() en gebruik in plaats daarvan een logger, log alleen nuttige informatie. Bekijk scikit-lego die behoorlijk coole functies heeft, decorateurs.
- Als u echt dingen wilt afdrukken, probeer dan de bibliotheek rijk waardoor het mooier wordt en ook als logprogramma kan worden gebruikt. Hier een snelle demo van rijk door calmcode.io
Belangrijkste opmerkingen
We hadden graag onze resultaten met u gedeeld, maar dat mocht niet vanwege privacyredenen, maar we kunnen wel zeggen dat we dat met deze methodologie wel konden:
- Wees net zo goed als hun beste vraagplanner
- Verhoog de FA van sommige winkels tot 30%
Maar aan de andere kant vindt u hier de lijst met onze grootste leermomenten die u hopelijk zullen helpen om uw eigen oplossing te ontwikkelen:
- Neem de tijd om uw probleem te begrijpen, definieer een duidelijk meetbaar doel, evaluatiemetriek
- Crunch en onderzoek uw data, als u geen afwijkingen hebt gevonden... dan hebt u niet genoeg gekeken!
- Volg uw experimenten nauwgezet
- Schrijf schone code, vooral in notitieblokken, het zal uw leven zo veel gemakkelijker maken voor de implementatie
- Denk altijd dat productie, data lekkage uw grootste vijand is bij het voorspellen van tijdreeksen
- Begin met een klein bereik, met eenvoudige modellen, test, faal, leer, verbeter en slaag!

