


NOTÍCIAS / TECNOLOGIA AI
25 de novembro de 2020
Neste artigo, Amale El Hamri, Cientista Sênior do Data na Artefact França, explica como treinar um modelo de linguagem sem que o próprio usuário tenha conhecimento da linguagem. O artigo inclui dicas sobre onde obter o data de treinamento, quanto data o senhor precisa, como pré-processar o data e como encontrar uma arquitetura e um conjunto de hiperparâmetros que melhor se adaptem ao seu modelo.
TLDR
Este artigo explica como criei meu próprio modelo de linguagem em coreano, um idioma complexo com treinamento limitado data. Aqui o senhor poderá aprender como treinar um modelo de idioma sem ter o luxo de entender esse idioma. O senhor encontrará dicas sobre onde obter o data de treinamento, a quantidade de data necessária, como pré-processar o data e como encontrar uma arquitetura e um conjunto de hiperparâmetros que melhor se adaptem ao seu modelo.
Meus principais aprendizados são:
Coleção Data:
- Quando a Wikipédia não tem volume suficiente ou não é usada o suficiente por falantes nativos do idioma a partir do qual o senhor deseja treinar seu modelo de idioma, uma boa opção é combinar a Wikipédia com outras fontes data, como o CommonCrawl.
Volume Data:
- Escolha os documentos que melhor representam o idioma coreano. Um número excessivo de documentos não seria útil, pois a melhoria marginal do desempenho seria muito pequena em comparação com o enorme tempo de treinamento.
- Escolha documentos que contenham as palavras mais usadas no idioma coreano.
- Encontrar uma arquitetura que consiga modelar a complexidade do treinamento data.
- Encontrar a combinação certa de parâmetros de regularização para não se ajustar demais.
Introdução
Se o senhor ainda não sabe, a PNL teve uma grande onda de aprendizagem por transferência nos últimos dois anos. A ideia principal é reutilizar modelos de linguagem pré-treinados para outra tarefa de PLN, como a classificação de texto. Um modelo de linguagem é um modelo de aprendizagem profunda que, dada parte de uma frase, é capaz de prever a próxima palavra da frase. A intuição para entender isso é que esse tipo de modelo compreende muito bem a estrutura do idioma, a gramática, o vocabulário, e o objetivo é ‘transferir’ esse conhecimento para outros modelos downstream.
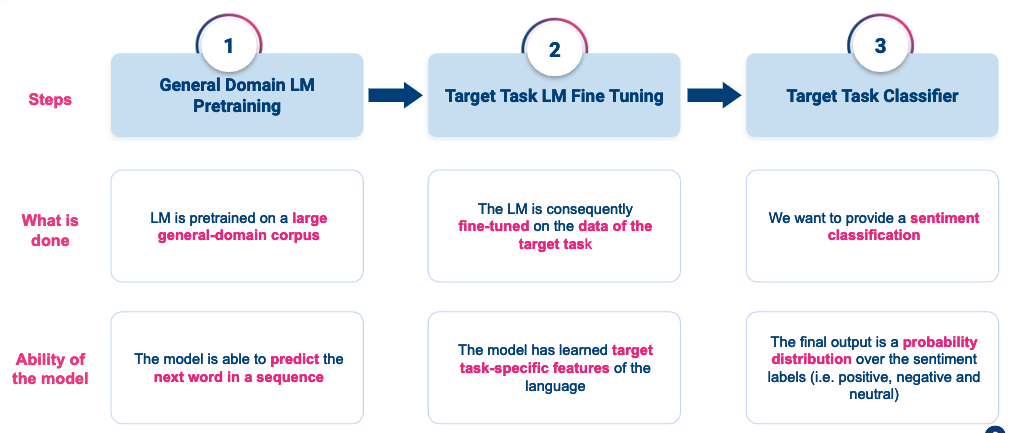
Exemplo: uma receita simples sobre como melhorar um classificador de texto usando o ajuste fino
Esta figura resume o método ULM Fit que usei para treinar meu modelo de linguagem e, portanto, ajustá-lo e transferi-lo para um classificador de texto.
- Etapa 1: Treinar um modelo geral de linguagem em um grande corpus de data no idioma de destino. Esse modelo será capaz de entender a estrutura do idioma, a gramática e o vocabulário principal.
- Etapa 2: Faça o ajuste fino do modelo de linguagem geral para o treinamento de classificação data. Ao fazer isso, o modelo aprenderá melhor a representar o vocabulário usado no corpus de treinamento.
- Etapa 3: Treine um classificador de texto usando o modelo de linguagem pré-treinado e bem ajustado. Esse método permite que o modelo compreenda as palavras em seu contexto. Além disso, o uso de um modelo de linguagem pré-treinado permite que o senhor treine o classificador com pouquíssimos exemplos de treinamento (apenas 400 textos por rótulo seriam suficientes).
Já sabemos que a classificação de texto funciona muito bem em inglês, francês, alemão, espanhol, chinês... mas o que devemos fazer em idiomas com poucos modelos de linguagem prontos para uso?
Antes de entrar em mais detalhes, o senhor deve estar se perguntando por que um cientista francês data como eu gostaria de ter um classificador de texto em coreano? O motivo é que faço parte de um projeto que desenvolve um produto para classificar publicações de mídia social em diferentes categorias. Depois de validar a metodologia em inglês e francês, começamos a ampliá-la para outros idiomas (inglês, francês, japonês, chinês e coreano).
Só que havia um desafio maior no idioma coreano, porque não havia nenhum modelo de idioma pré-treinado para ser encontrado em código aberto, então tive que fazer isso sozinho com pouquíssimos recursos linguísticos coreanos.
Este artigo se concentrará na classificação de textos coreanos usando o método multi-fit explicado a seguir papel.
Muitos idiomas estão bem representados na Web, como inglês, chinês, espanhol, português, francês: Inglês, chinês, espanhol, português, francês... O idioma coreano ainda é muito pouco documentado e não há muito conteúdo pronto para ser reutilizado. Por isso, pensei em contribuir compartilhando meus principais aprendizados com os senhores, enquanto descobria a PNL coreana.
Neste artigo, contarei aos senhores sobre minha jornada para treinar um modelo de idioma coreano sem entender uma única palavra de coreano e como o usei para classificação de texto.
Isenção de responsabilidade: Normalmente, consideramos que um modelo de linguagem é bom quando atinge uma precisão de cerca de 45-50%. Como meu objetivo não é gerar texto em coreano, não preciso atingir esse desempenho: Só preciso de um modelo que “entenda” a gramática e a estrutura do idioma coreano para que eu possa usá-lo para treinar um classificador de texto coreano.
1 - Coleção Data para treinamento do modelo de linguagem
1.1 - Fonte Data
Normalmente, ao treinar um modelo de idioma do zero, as sugestões do tutorial do ULM FiT são baixar todo o conteúdo da Wikipédia no idioma em questão. Essas diretrizes só funcionam se os falantes nativos desse idioma estiverem acostumados a publicar muito nesse canal.
Em coreano, parece que as pessoas não estão acostumadas a isso: não só o contexto coreano da Wikipédia não tem volume suficiente, como também não é representativo da fala coreana nativa.
Aqui está uma comparação entre o número de artigos na Wikipédia em inglês e na coreana para dar algumas dicas:

Meu conselho: Combinei artigos da Wikipédia com o Common Crawl data, que o senhor pode baixar em aqui.
1.2 - Volume do Data
Lembremos que um modelo de linguagem é um modelo que deve prever a próxima palavra em um texto. Para fazer isso, nosso modelo deve ter visto muitos exemplos para aprender o idioma e ser bom em falar. Dito isso, não é útil ir além de 100 milhões de tokens. Isso só aumenta a complexidade do seu modelo, além de aumentar o tempo de treinamento.
Assim, à primeira vista, depois de recuperar toda a Wikipédia e o Common Crawl data, eu me deparei com muito mais de 100 milhões de tokens, de modo que tive de escolher os documentos mais relevantes para treinar meu modelo. O objetivo da minha metodologia é manter os documentos que representam da melhor forma o idioma coreano nativo:
- Primeiro, realizei uma tokenização fraca em meu corpus para aproximar o número de tokens que eu tinha ao dividir o corpus em espaços.
- Removi todos os números, emojis, pontuação e outros símbolos que não são específicos do coreano de meus tokens obtidos.
- Calculei um contador de todos os tokens em meu corpus e recuperei os 70.000 tokens mais mencionados.
- Em seguida, recuperei documentos que mencionavam a maioria dos tokens mais usados, de modo que meu corpus seria construído com 100 milhões de tokens e aí estava meu corpus de treinamento!
Agora que temos nosso corpo bruto de treinamento, podemos começar a fazer negócios de verdade!
2 - tokenização Data
Acho que quando eu lhe disse antes que tokenizei com uma função de divisão, o senhor começou a pensar que este artigo era realmente uma piada, mas vamos tranquilizá-lo, esse nunca foi o meu objetivo final!
Primeiro, vamos lembrá-lo de que nenhum outro pré-processamento do data é necessário para treinar um modelo de linguagem. Muitas tarefas de NLP executam a remoção de números, stopwords, letras minúsculas, stemming... Tudo isso tiraria o texto de seu contexto e nosso objetivo é aprender a falar coreano, portanto, devemos manter todo o texto como foi originalmente escrito.
Para tokenizar o texto coreano, experimentei dois modelos de tokenização:
- Modelo coreano de espaço que é um wrapper para o tokenizador mecab coreano.
- peça de sentença modelo de tokenizador de subpalavras treinado em meu corpus com 28.000 tokens máximos
Como é recomendado no artigo multifit, Por isso, optei pela segunda opção para ter uma granularidade de subpalavra.
3 - Modelo de treinamento
Ao treinar um modelo de linguagem, bem como treinar qualquer modelo, os dois aspectos que o senhor deseja evitar são subadaptação e sobreajuste.
Um modelo sob ajustes quando ele é simples demais em relação ao data que está tentando modelar. Isso pode ser detectado quando o senhor constata que o modelo não consegue aprender com o data de treinamento e que a perda de treinamento não converge para 0.
Por outro lado, um modelo sobre ajustes quando ele aprende “muito bem” a modelar seu data de treinamento, mas o desempenho permanece baixo no data de teste. Isso é um sinal de que seu modelo provavelmente não conseguirá prever bem o data que ele ainda não viu.
Quando comecei a treinar meu modelo de linguagem, no início eu estava realmente lutando para aprender alguma coisa com meu data. Como o senhor pode ver na imagem abaixo, após 10 épocas de treinamento, minha perda de treinamento não diminuía nem um centímetro.
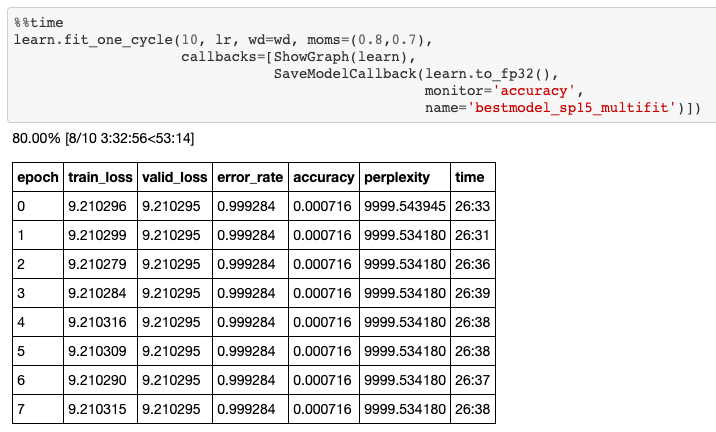
Isso significa que meu modelo era simples demais para representar a complexidade do idioma coreano.
Aqui está o que fiz para superar esse problema:
Como o senhor pode imaginar, a depuração de qualquer modelo de aprendizagem profunda não é fácil, pois há muitos graus de liberdade. O senhor precisa encontrar a estrutura de rede correta, bem como o conjunto certo de hiperparâmetros.
Para simplificar o problema no início, o caminho certo a seguir é tentar fazer o overfit em um único lote de data. A ideia aqui é garantir que, dado algum data, seu modelo seja capaz de interpretar sua complexidade e ter um bom desempenho no conjunto de treinamento.
Aqui estão todas as coisas que tentei:
- Aumentar o tamanho da incorporação
- Aumentar o número de camadas ocultas
- Alteração das funções do otimizador
- Alteração da taxa de aprendizado
Depois de muitas tentativas, aqui estão a estrutura e os hiperparâmetros que permitiram que meu modelo começasse a aprender:
Arquitetura de rede neural:
- Estrutura do QRNN
- Número de camadas ocultas: 2500
- Número de camadas: 4
- Tamanho da incorporação: 768
Quando o modelo for capaz de prever corretamente no conjunto de treinamento, o próximo passo a ser evitado é o ajuste excessivo.
Aqui estão algumas regularizações que tentei para garantir que meu modelo não se ajustasse demais.
- Adicionar desistência
- Adicionar redução de peso
- Adicionar recorte de gradiente
Aqui estão os regularizadores que usei para treinar meu modelo:
- Taxa de aprendizado: 0.0002
- Decaimento do peso: 1e-8
- Recorte de gradiente: 0.25
Resultados
Depois de treinar meu modelo por 15 épocas, finalmente alcancei uma precisão de 25% e uma perplexidade de 100. Como disse no início, nunca tive a intenção de usar meu modelo de linguagem para geração de texto, portanto, já fiquei satisfeito em saber que meu modelo é capaz de prever corretamente uma palavra em cada 4.
Em seguida, reutilizei meu modelo pré-treinado para classificação de texto. O dataset que usei é um dataset equilibrado composto por 10 mil documentos sociais provenientes do Instagram, Facebook, YouTube e sites que foram rotulados como “label1” ou não “not label1”. Meu objetivo era prever se uma nova publicação é sobre “label1” ou não.
Aqui estão os desempenhos que obtive para todos os idiomas que desenvolvemos:
Imagem para postagem
Desempenho de classificadores de texto de diferentes idiomas
Portanto, mesmo sem falar o idioma e treinar eu mesmo o modelo de idioma pré-treinado, o desempenho do classificador de texto coreano alcança muito bem o desempenho dos outros idiomas.
Ainda tenho muitas coisas que preciso tentar para melhorar o desempenho que obtenho, mas, ainda assim, foi uma espécie de granizo aprender a processar documentos de um idioma complexo como o coreano sem entender uma palavra sequer e sem encontrar informações e orientações relevantes na Web.
Próximas etapas
Acabei de descrever como poderia aprimorar um modelo de classificação de texto coreano utilizando um modelo de linguagem simples criado do zero. O desempenho inicial já é bom, mas ainda há espaço para melhorias. Acho que o que eu gostaria de trabalhar em curto prazo seria:
- Revisar a tokenização: como não falo uma palavra de coreano, seria interessante que um falante nativo de coreano desse uma olhada na tokenização e confirmasse se ela faz sentido.
- Aprimore meu modelo de linguagem e compare os desempenhos de classificação:
- Aprendizagem por transferência de um modelo de linguagem retroativa, pois parecia ter sido mais eficiente em inglês ou francês.
- Aprendizagem por transferência de um modelo de linguagem bidirecional.
- Ter taxas de aprendizado dinâmicas durante o treinamento para evitar ficar preso em um mínimo local.

