


NACHRICHTEN / KI-TECHNOLOGIE
25. November 2020
In diesem Artikel erklärt Amale El Hamri, Senior Data Scientist bei Artefact France, wie man ein Sprachmodell trainiert, ohne die Sprache selbst zu verstehen. Der Artikel enthält Tipps dazu, woher Sie Trainings-data erhalten, wie viel data Sie benötigen, wie Sie Ihr data vorverarbeiten und wie Sie eine Architektur und eine Reihe von Hyperparametern finden, die am besten zu Ihrem Modell passen.
TLDR
In diesem Artikel erkläre ich, wie ich mein eigenes Sprachmodell für Koreanisch erstellt habe, eine komplexe Sprache mit begrenztem Training data. Hier können Sie lernen, wie man ein Sprachmodell trainiert, ohne den Luxus zu haben, diese Sprache selbst zu verstehen. Sie finden Tipps dazu, woher Sie data für das Training bekommen, wie viel data Sie benötigen, wie Sie Ihr data vorverarbeiten und wie Sie eine Architektur und einen Satz von Hyperparametern finden, die am besten zu Ihrem Modell passen.
Meine wichtigsten Erkenntnisse sind:
Data Kollektion:
- Wenn Wikipedia nicht genügend Daten enthält oder von Muttersprachlern der Sprache, anhand derer Sie Ihr Sprachmodell trainieren möchten, nicht ausreichend genutzt wird, ist es sinnvoll, Wikipedia mit anderen data-Quellen wie CommonCrawl zu kombinieren.
Data Volumen:
- Wählen Sie Dokumente aus, die die koreanische Sprache am besten repräsentieren. Zu viele Dokumente wären nicht sinnvoll, da die marginale Leistungsverbesserung im Vergleich zur enormen Trainingszeit zu gering wäre.
- Wählen Sie Dokumente aus, die die am häufigsten verwendeten Wörter in der koreanischen Sprache enthalten.
- Finden Sie eine Architektur, die es schafft, die Komplexität des Trainings data zu modellieren.
- Finden Sie die richtige Kombination von Regularisierungsparametern, um eine Überanpassung zu vermeiden.
Einführung
Falls Sie es noch nicht wissen: NLP hat in den letzten zwei Jahren einen riesigen Hype um Transfer Learning erlebt. Die Hauptidee ist die Wiederverwendung von zuvor trainierten Sprachmodellen für eine andere NLP-Aufgabe wie z.B. die Textklassifizierung. Ein Sprachmodell ist ein Deep Learning-Modell, das aus einem Teil eines Satzes das nächste Wort des Satzes vorhersagen kann. Die Intuition dahinter ist, dass diese Art von Modell die Sprachstruktur, die Grammatik und das Vokabular sehr gut versteht und das Ziel darin besteht, dieses Wissen auf andere nachgelagerte Modelle zu übertragen.
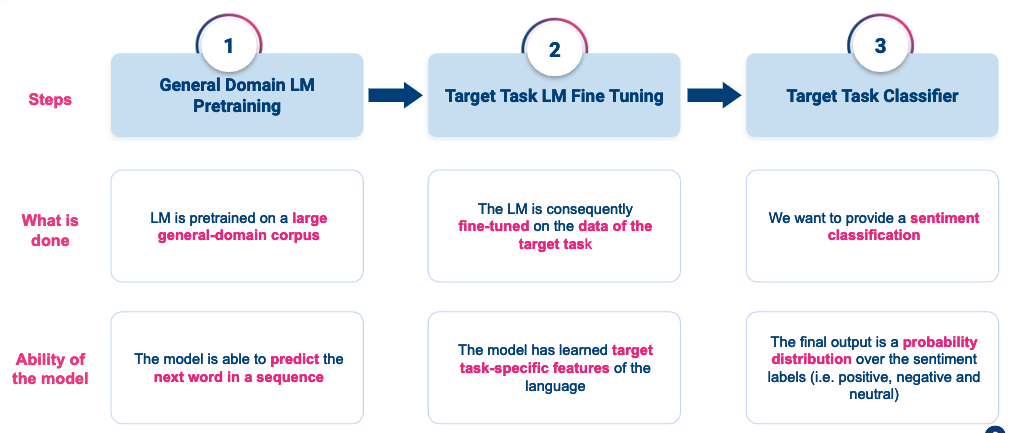
Beispiel: ein einfaches Rezept zur Verbesserung eines Textklassifikators durch Feinabstimmung
Diese Abbildung fasst die ULM Fit-Methode zusammen, die ich für das Training meines Sprachmodells verwendet habe, um es zu verfeinern und in einen Textklassifikator zu übertragen.
- Schritt 1: Trainieren Sie ein allgemeines Sprachmodell auf einem großen Korpus von data in der Zielsprache. Dieses Modell wird in der Lage sein, die Sprachstruktur, die Grammatik und den wichtigsten Wortschatz zu verstehen.
- Schritt 2: Stimmen Sie das allgemeine Sprachmodell auf das Klassifizierungstraining data ab. Auf diese Weise lernt Ihr Modell besser, das in Ihrem Trainingskorpus verwendete Vokabular darzustellen.
- Schritt 3: Trainieren Sie einen Textklassifikator mit Ihrem fein abgestimmten, vorab trainierten Sprachmodell. Diese Methode ermöglicht es Ihrem Modell, die Wörter in ihrem Kontext zu verstehen. Außerdem können Sie Ihren Klassifikator mit einem vorab trainierten Sprachmodell mit sehr wenigen Trainingsbeispielen trainieren (schon 400 Texte pro Label reichen aus).
Wir wissen bereits, dass die Textklassifizierung für Englisch, Französisch, Deutsch, Spanisch und Chinesisch gut funktioniert... aber was sollen wir mit Sprachen machen, für die es nur wenige Sprachmodelle von der Stange gibt?
Bevor ich auf weitere Details eingehe, fragen Sie sich vielleicht, warum ein französischer data-Wissenschaftler wie ich einen Textklassifikator auf Koreanisch haben möchte? Der Grund dafür ist, dass ich an einem Projekt beteiligt bin, das ein Produkt zur Klassifizierung von Beiträgen in sozialen Medien in verschiedene Kategorien entwickelt. Nachdem wir die Methode auf Englisch und Französisch validiert hatten, begannen wir, sie auf andere Sprachen zu übertragen (Englisch, Französisch, Japanisch, Chinesisch und Koreanisch).
Nur bei der koreanischen Sprache gab es eine größere Herausforderung, denn es gab kein vortrainiertes Sprachmodell in Open Source, so dass ich es mit sehr wenigen koreanischen Sprachressourcen selbst machen musste.
Dieser Artikel befasst sich mit der Klassifizierung koreanischer Texte mit Hilfe der Multi-Fit-Methode, die im Folgenden erläutert wird. Papier.
Viele Sprachen sind im Web stark vertreten, wie z.B.: Englisch, Chinesisch, Spanisch, Portugiesisch, Französisch... Die koreanische Sprache ist nach wie vor sehr schlecht dokumentiert und es gibt nicht viele Inhalte, die wiederverwendet werden können. Deshalb wollte ich selbst einen Beitrag leisten, indem ich meine wichtigsten Erkenntnisse mit Ihnen teile, während ich das koreanische NLP entdecke.
In diesem Artikel erzähle ich Ihnen, wie ich ein koreanisches Sprachmodell trainiert habe, ohne ein einziges Wort Koreanisch zu verstehen, und wie ich es zur Textklassifizierung eingesetzt habe.
Haftungsausschluss: Normalerweise betrachten wir ein Sprachmodell als gut, wenn es eine Genauigkeit von etwa 45-50% erreicht. Da mein Ziel nicht darin besteht, koreanischen Text zu generieren, muss ich eine solche Leistung nicht erreichen: Ich brauche nur ein Modell, das die Grammatik und Struktur der koreanischen Sprache “versteht”, damit ich damit einen koreanischen Textklassifikator trainieren kann.
1 - Data Sammlung für das Training des Sprachmodells
1.1 - Data Quelle
Wenn Sie ein Sprachmodell von Grund auf trainieren, empfiehlt das ULM FiT-Tutorial normalerweise, alle Wikipedia-Inhalte in der jeweiligen Sprache herunterzuladen. Diese Richtlinien funktionieren nur, wenn Muttersprachler dieser Sprache gewohnt sind, viel auf diesem Kanal zu veröffentlichen.
Im Koreanischen sind die Menschen anscheinend nicht daran gewöhnt: nicht nur der koreanische Wikipedia-Kontext hat nicht genug Volumen, und er ist auch nicht repräsentativ für die koreanische Muttersprache.
Hier ist ein Vergleich zwischen der Anzahl der Artikel in der englischen und koreanischen Wikipedia, um einige Hinweise zu geben:

Mein Ratschlag: Ich habe Wikipedia-Artikel mit Common Crawl data kombiniert, das Sie herunterladen können unter Hier.
1.2 - Data Volumen
Erinnern wir uns, dass ein Sprachmodell ein Modell ist, das das nächste Wort in einem Text vorhersagen soll. Um das zu tun, sollte unser Modell viele Beispiele gesehen haben, um die Sprache zu lernen und gut zu sprechen. Abgesehen davon ist es nicht sinnvoll, mehr als 100 Millionen Token zu verwenden. Das erhöht nur die Komplexität Ihres Modells und die Trainingszeit.
Auf den ersten Blick hatte ich also, nachdem ich alle Wikipedia- und Common Crawl data-Dokumente abgerufen hatte, weit mehr als 100 Millionen Token, so dass ich die relevantesten Dokumente für das Training meines Modells auswählen musste. Das Ziel meiner Methodik ist es, die Dokumente zu behalten, die die koreanische Muttersprache am besten repräsentieren:
- Ich habe zunächst eine schwache Tokenisierung an meinem Korpus vorgenommen, um die Anzahl der Token, die ich hatte, näherungsweise zu bestimmen, indem ich den Korpus auf Leerzeichen aufgeteilt habe.
- Ich habe alle Zahlen, Emojis, Satzzeichen und andere Symbole, die nicht spezifisch für Koreanisch sind, aus meinen erhaltenen Token entfernt.
- Ich habe einen Zähler für alle Token in meinem Korpus berechnet und die 70.000 am häufigsten erwähnten Token herausgesucht.
- Dann suchte ich nach Dokumenten, in denen die meisten der am häufigsten verwendeten Token vorkommen, so dass mein Korpus aus 100 Millionen Token bestehen würde - und fertig war mein Trainingskorpus!
Jetzt, wo wir unseren Rohbestand an Schulungen haben, können wir richtig loslegen!
2 - Data Tokenisierung
Als ich Ihnen vorhin erzählte, dass ich mit einer Split-Funktion tokenisiert habe, dachten Sie wohl, dieser Artikel sei ein Scherz, aber ich kann Sie beruhigen: Das war nie mein Ziel!
Zunächst möchten wir Sie daran erinnern, dass für das Training eines Sprachmodells keine weitere data-Vorverarbeitung erforderlich ist. Bei vielen NLP-Aufgaben wird der Text von Zahlen, Stoppwörtern, Kleinschreibung, Stemming ... befreit. All dies würde Ihren Text aus dem Kontext reißen, und unser Ziel ist es, Koreanisch zu lernen, also müssen wir den gesamten Text so behalten, wie er ursprünglich geschrieben wurde.
Um koreanischen Text zu tokenisieren, habe ich zwei Tokenisierungsmodelle ausprobiert:
- Koreanisches spaciges Modell das ein Wrapper für den koreanischen Mecab-Tokenizer ist.
- Satzteil subwords tokenizer model trainiert auf meinem Korpus mit 28000 maximalen Token
Wie in der Empfehlung des Multifit-Artikel, Ich habe mich für die zweite Option entschieden, um eine Unterwort-Granularität zu haben.
3 - Ausbildungsmodell
Beim Training eines Sprachmodells wie auch bei jedem anderen Modell sollten Sie zwei Dinge vermeiden Unterausstattung und Überanpassung.
Ein Modell unter passt wenn es in Bezug auf das data, das es zu modellieren versucht, zu einfach ist. Sie können dies erkennen, wenn Sie feststellen, dass Ihr Modell nicht auf Ihren Trainings-data lernen kann und dass Ihr Trainingsverlust überhaupt nicht gegen 0 konvergiert.
Auf der anderen Seite, ein Modell über passt wenn es “zu gut” lernt, um Ihre Trainings-data zu modellieren, aber die Leistung bei den Test-data niedrig bleibt. Das ist ein Zeichen dafür, dass Ihr Modell wahrscheinlich keine guten data vorhersagen kann, die es noch nicht gesehen hat.
Als ich begann, mein Sprachmodell zu trainieren, hatte ich anfangs wirklich Mühe, etwas von meinem data zu lernen. Wie Sie auf dem Bild unten sehen können, hat sich mein Trainingsverlust nach 10 Epochen Training nicht um einen Zentimeter verringert.
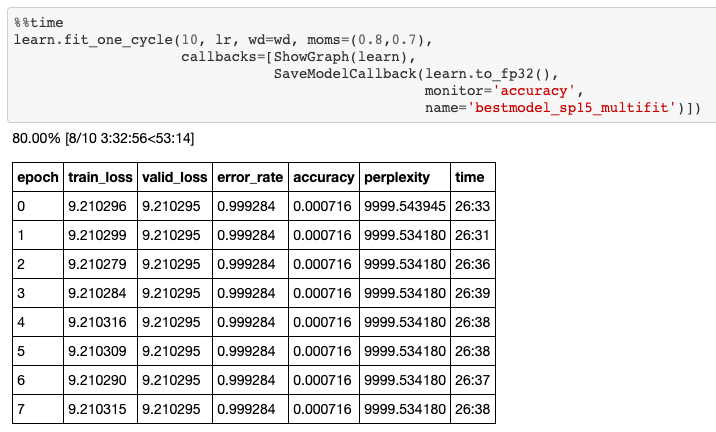
Das bedeutet, dass mein Modell zu einfach war, um die Komplexität der koreanischen Sprache darzustellen.
Hier ist, was ich getan habe, um dieses Problem zu lösen:
Wie Sie sich vorstellen können, ist die Fehlersuche bei einem Deep Learning-Modell nicht einfach, da es so viele Freiheitsgrade gibt. Sie müssen sowohl die richtige Netzwerkstruktur als auch den richtigen Satz an Hyperparametern finden.
Um das Problem zu Beginn zu vereinfachen, sollten Sie versuchen, einen einzelnen Stapel von data zu überarbeiten. Die Idee dahinter ist, sicherzustellen, dass Ihr Modell in der Lage ist, die Komplexität von data zu interpretieren und in der Trainingsmenge gut abzuschneiden.
Hier sind alle Dinge, die ich ausprobiert habe:
- Größe der Einbettung erhöhen
- Anzahl der versteckten Schichten erhöhen
- Ändern der Optimierungsfunktionen
- Ändern der Lerngeschwindigkeit
Nach vielen Versuchen habe ich die Struktur und die Hyperparameter gefunden, mit denen mein Modell zu lernen begann:
Architektur des neuronalen Netzwerks:
- QRNN Struktur
- Anzahl der versteckten Schichten: 2500
- Anzahl der Ebenen : 4
- Größe der Einbettung : 768
Sobald Ihr Modell in der Lage ist, eine korrekte Vorhersage für Ihre Trainingsmenge zu treffen, sollten Sie als nächstes eine Überanpassung vermeiden.
Hier sind einige Regularisierungen, die ich ausprobiert habe, um sicherzustellen, dass mein Modell nicht übermäßig angepasst wird.
- Abbruch hinzufügen
- Gewichtsabnahme hinzufügen
- Farbverlaufsausschnitt hinzufügen
Hier sind die Regularizer, die ich für das Training meines Modells verwendet habe:
- Lernrate: 0.0002
- Gewichtsabnahme: 1e-8
- Gradient clipping: 0.25
Ergebnisse
Nachdem ich mein Modell 15 Epochen lang trainiert hatte, erreichte ich schließlich eine Genauigkeit von 25% und eine Perplexität von 100. Wie ich eingangs sagte, hatte ich nie vor, mein Sprachmodell für die Texterstellung zu verwenden. Ich war also schon zufrieden, dass mein Modell eines von 4 Wörtern richtig vorhersagen kann.
Dann habe ich mein zuvor trainiertes Modell für die Textklassifizierung wiederverwendet. Das von mir verwendete dataset ist ein ausgewogenes dataset aus 10k sozialen Dokumenten von Instagram, Facebook, Youtube und Websites, die als “label1” oder nicht “not label1” gekennzeichnet waren. Mein Ziel war es, vorherzusagen, ob eine neue Veröffentlichung über “label1” handelt oder nicht.
Hier sind die Leistungen, die ich für alle von uns entwickelten Sprachen erhalte:
Bild für Beitrag
Leistungen von Textklassifikatoren für verschiedene Sprachen
Auch ohne die Sprache zu sprechen und das vortrainierte Sprachmodell selbst zu trainieren, erreicht die Leistung des koreanischen Textklassifikators die Leistung der anderen Sprachen recht gut.
Es gibt immer noch eine Menge Dinge, die ich versuchen sollte, um meine Leistungen zu verbessern, aber dennoch war es eine Art Hailmarie, zu lernen, Dokumente in einer komplexen Sprache wie Koreanisch zu bearbeiten, ohne ein Wort davon zu verstehen und ohne relevante Informationen und Ratschläge im Internet zu finden.
Nächste Schritte
Ich habe gerade beschrieben, wie ich ein koreanisches Textklassifizierungsmodell mit Hilfe eines einfachen, von Grund auf neu erstellten Sprachmodells verbessern konnte. Die anfängliche Leistung ist bereits gut, aber es gibt noch Raum für Verbesserungen. Ich denke, woran ich kurzfristig arbeiten möchte, ist Folgendes:
- Korrekturlesen der Tokenisierung: Da ich kein Wort Koreanisch spreche, wäre es interessant, wenn ein koreanischer Muttersprachler einen Blick auf die Tokenisierung werfen und bestätigen würde, dass sie sinnvoll ist.
- Verbessern Sie mein Sprachmodell und vergleichen Sie die Klassifizierungsleistungen, indem Sie:
- Transfer-Lernen eines rückwärtsgerichteten Sprachmodells, da es bei Englisch oder Französisch leistungsfähiger zu sein schien.
- Transfer-Lernen eines bi-direktionalen Sprachmodells.
- Dynamische Lernraten während des Trainings, um zu vermeiden, dass Sie in einem lokalen Minimum stecken bleiben.

