


ACTUALITÉS / TECHNOLOGIE DE L'AI
25 novembre 2020
Dans cet article, Amale El Hamri, scientifique senior Data à Artefact France, explique comment former un modèle linguistique sans comprendre la langue elle-même. L'article comprend des conseils sur l'origine des data d'entraînement, la quantité de data dont vous avez besoin, le prétraitement de vos data et la recherche d'une architecture et d'un ensemble d'hyperparamètres qui conviennent le mieux à votre modèle.
TLDR
Cet article explique comment j'ai créé mon propre modèle linguistique en coréen, une langue complexe pour laquelle la formation est limitée data. Vous apprendrez ici comment former un modèle linguistique sans avoir le luxe de comprendre cette langue vous-même. Vous trouverez des conseils sur l'obtention de data d'entraînement, la quantité de data dont vous avez besoin, le prétraitement de votre data et la recherche d'une architecture et d'un ensemble d'hyperparamètres qui conviennent le mieux à votre modèle.
Mes principaux enseignements sont les suivants :
Collection Data :
- Lorsque Wikipédia n'a pas un volume suffisant ou qu'elle n'est pas suffisamment utilisée par les locuteurs natifs de la langue à partir de laquelle vous souhaitez former votre modèle linguistique, il est judicieux de combiner Wikipédia avec d'autres sources data telles que CommonCrawl.
Volume Data :
- Choisissez les documents qui représentent le mieux la langue coréenne. Un trop grand nombre de documents ne serait pas utile, car l'amélioration marginale des performances serait trop faible par rapport à l'énorme temps de formation.
- Choisissez des documents qui contiennent les mots les plus utilisés dans la langue coréenne.
- Trouvez une architecture qui parvienne à modéliser la complexité de la formation data.
- Trouvez la bonne combinaison de paramètres de régularisation pour ne pas surajuster.
Introduction
Si vous ne le savez pas encore, l'apprentissage par transfert a connu un véritable engouement au cours des deux dernières années. L'idée principale est de réutiliser des modèles de langage pré-entraînés pour une autre tâche de NLP telle que la classification de texte. Un modèle de langage est un modèle d'apprentissage profond qui, à partir d'une partie de phrase, est capable de prédire le mot suivant de la phrase. L'intuition qu'il faut en tirer est que ce type de modèle comprend très bien la structure de la langue, la grammaire, le vocabulaire, et l'objectif est de ‘transférer’ cette connaissance à d'autres modèles en aval.
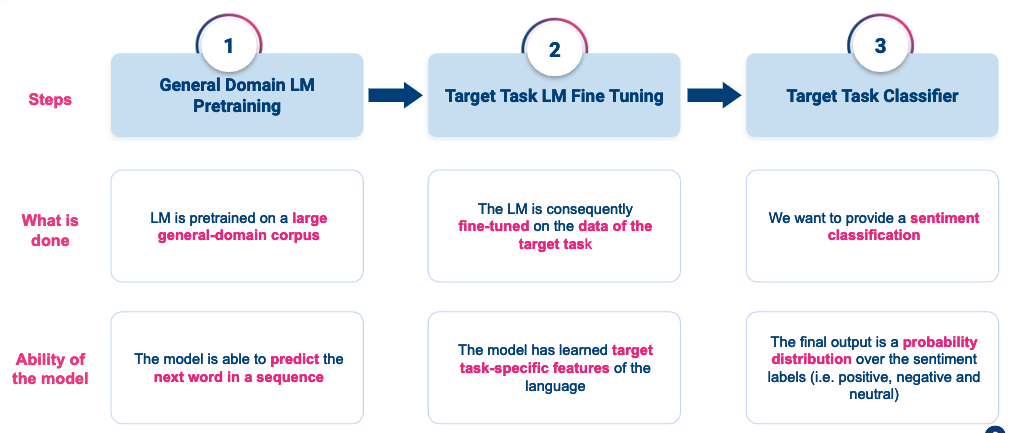
Exemple : une recette simple sur la façon d'améliorer un classificateur de texte en utilisant le réglage fin
Cette figure résume la méthode ULM Fit que j'ai utilisée pour entraîner mon modèle linguistique et donc l'affiner et le transférer dans un classificateur de texte.
- Étape 1 : Entraînez un modèle linguistique général sur un large corpus de data dans la langue cible. Ce modèle sera capable de comprendre la structure de la langue, la grammaire et le vocabulaire principal.
- Étape 2 : Ajustez le modèle linguistique général à la formation à la classification data. Ainsi, votre modèle apprendra mieux à représenter le vocabulaire utilisé dans votre corpus de formation.
- Étape 3 : Entraînez un classificateur de texte à l'aide de votre modèle linguistique pré-entraîné. Cette méthode permet à votre modèle de comprendre les mots dans leur contexte. En outre, l'utilisation d'un modèle linguistique pré-entraîné vous permet d'entraîner votre classificateur sur très peu d'exemples d'entraînement (400 textes par étiquette suffisent).
Nous savons déjà que la classification des textes fonctionne bien pour l'anglais, le français, l'allemand, l'espagnol, le chinois... mais que faire pour les langues pour lesquelles il n'existe que très peu de modèles linguistiques disponibles sur le marché ?
Avant d'entrer dans les détails, vous vous demandez peut-être pourquoi un scientifique français data comme moi voudrait avoir un classificateur de texte en coréen ? La raison est que je fais partie d'un projet qui développe un produit pour classer les messages des médias sociaux en différentes catégories. Après avoir validé la méthodologie en anglais et en français, nous avons commencé à l'étendre à d'autres langues (anglais, français, japonais, chinois et coréen).
Seul le coréen représentait un défi plus important, car il n'existait pas de modèle linguistique pré-entraîné en source ouverte, et j'ai donc dû le faire moi-même avec très peu de ressources linguistiques coréennes.
Cet article se concentre sur la classification de textes coréens à l'aide de la méthode multi-fit expliquée ci-dessous. papier.
De nombreuses langues sont très représentées sur le web, telles que l'anglais, le chinois, l'espagnol, le portugais et le français : L'anglais, le chinois, l'espagnol, le portugais, le français... Le coréen reste très peu documenté et peu de contenu est prêt à être réutilisé. J'ai donc pensé à apporter ma contribution en partageant avec vous mes apprentissages clés, tout en découvrant le NLP coréen.
Dans cet article, je vais vous raconter mon parcours pour former un modèle de langue coréenne sans comprendre un seul mot de coréen et comment je l'ai utilisé pour la classification de textes.
Avis de non-responsabilité : Habituellement, nous considérons qu'un modèle de langage est bon lorsqu'il atteint une précision d'environ 45-50%. Mon objectif n'étant pas de générer du texte coréen, je n'ai pas besoin d'atteindre de telles performances : J'ai seulement besoin d'un modèle qui “comprenne” la grammaire et la structure de la langue coréenne afin de pouvoir l'utiliser pour entraîner un classificateur de texte coréen.
1 - Collection Data pour l'entraînement au modèle linguistique
1.1 - Source Data
Habituellement, lors de l'entraînement d'un modèle linguistique à partir de zéro, le tutoriel ULM FiT suggère de télécharger tout le contenu de Wikipédia dans la langue donnée. Ces recommandations ne fonctionnent que si les locuteurs natifs de cette langue ont l'habitude de publier beaucoup sur ce canal.
En coréen, il semble que les gens ne soient pas habitués : non seulement le contexte coréen de Wikipedia n'a pas assez de volume, mais il n'est pas non plus représentatif de la langue maternelle coréenne.
Voici une comparaison entre le nombre d'articles dans les Wikipédias anglaise et coréenne pour vous donner quelques indications :

Mon conseil : J'ai combiné des articles de Wikipedia avec Common Crawl data que vous pouvez télécharger à partir de ici.
1.2 - Volume du Data
Rappelons qu'un modèle de langage est un modèle censé prédire le mot suivant dans un texte. Pour ce faire, notre modèle doit avoir vu un grand nombre d'exemples pour apprendre la langue et être capable de la parler. Ceci étant dit, il n'est pas utile d'aller au-delà de 100 millions de tokens. Cela ne fait qu'ajouter de la complexité à votre modèle ainsi qu'un temps d'apprentissage considérable.
Ainsi, à première vue, une fois que j'ai récupéré tous les documents de Wikipedia et de Common Crawl data, je me suis retrouvé avec bien plus de 100 millions de tokens, et j'ai donc dû choisir les documents les plus pertinents pour entraîner mon modèle. L'objectif de ma méthodologie est de conserver les documents qui représentent le mieux la langue coréenne :
- J'ai d'abord effectué une faible tokénisation sur mon corpus afin d'obtenir une approximation du nombre de tokens que j'avais en divisant le corpus sur les espaces.
- J'ai supprimé tous les chiffres, les émojis, la ponctuation et les autres symboles qui ne sont pas spécifiques au coréen des jetons que j'ai obtenus.
- J'ai calculé un compteur de tous les tokens de mon corpus et j'ai récupéré les 70 000 tokens les plus mentionnés.
- J'ai ensuite récupéré les documents qui mentionnent la plupart des termes les plus utilisés, de sorte que mon corpus soit constitué de 100 millions de termes, et voilà mon corpus de formation !
Maintenant que nous disposons de notre corpus brut de formation, nous pouvons commencer à travailler !
2 - Data tokenization
Je suppose que lorsque je vous ai dit tout à l'heure que j'avais tokenisé avec une fonction split, vous avez commencé à penser que cet article était vraiment une blague, mais rassurez-vous, cela n'a jamais été ma finalité !
Tout d'abord, rappelons qu'aucun autre prétraitement data n'est nécessaire pour l'entraînement d'un modèle de langage. Un grand nombre de tâches NLP procèdent à l'épuration du texte en supprimant les chiffres, les mots vides, les minuscules, les troncs d'arbre... Toutes ces opérations priveraient votre texte de son contexte et notre objectif étant d'apprendre à parler coréen, nous devons conserver tout notre texte tel qu'il a été écrit à l'origine.
Pour tokeniser le texte coréen, j'ai essayé deux modèles de tokenisation :
- Modèle spacy coréen qui est un wrapper pour le tokenizer coréen mecab.
- pièce de phrase modèle de tokenizer subwords entraîné sur mon corpus avec 28000 tokens maximum
Comme le recommande la article multifit, J'ai choisi la deuxième option pour avoir une granularité de sous-mots.
3 - Modèle de formation
Lors de la formation d'un modèle linguistique ou de tout autre modèle, les deux choses que vous voulez éviter sont les suivantes sous-adaptation et surajustement.
Un modèle sous convient lorsqu'il est trop simple par rapport à la data qu'il tente de modéliser. Vous pouvez détecter cela lorsque vous constatez que votre modèle ne peut pas apprendre sur votre data d'apprentissage et que votre perte d'apprentissage ne converge pas du tout vers 0.
Au contraire, un modèle plus s'adapte lorsqu'il apprend “trop bien” à modéliser votre data d'apprentissage mais que ses performances restent faibles sur le data de test. C'est le signe que votre modèle n'est pas susceptible de bien prédire data qu'il n'a pas vu.
Lorsque j'ai commencé à entraîner mon modèle de langage, j'ai d'abord eu du mal à apprendre quoi que ce soit de mon data. Comme vous pouvez le voir sur l'image ci-dessous, après 10 époques d'entraînement, ma perte d'entraînement ne diminuait pas d'un pouce.
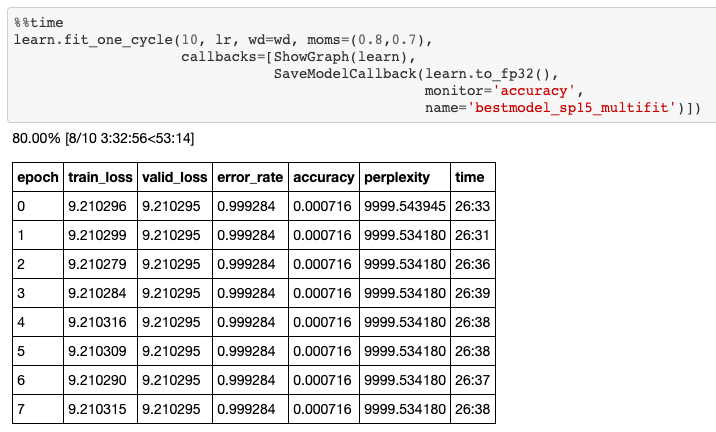
Cela signifie que mon modèle était trop simple pour représenter la complexité de la langue coréenne.
Voici ce que j'ai fait pour résoudre ce problème :
Comme vous pouvez l'imaginer, le débogage d'un modèle d'apprentissage profond n'est pas facile car il existe de nombreux degrés de liberté. Vous devez trouver la bonne structure de réseau ainsi que le bon ensemble d'hyperparamètres.
Pour simplifier le problème au départ, la bonne méthode consiste à essayer de surajuster un seul lot de data. L'idée ici est de s'assurer que, étant donné un certain nombre de data, votre modèle est capable d'interpréter sa complexité et d'obtenir de bons résultats sur l'ensemble d'apprentissage.
Voici toutes les choses que j'ai essayées :
- Augmenter la taille de l'encastrement
- Augmenter le nombre de couches cachées
- Modification des fonctions de l'optimiseur
- Modification du taux d'apprentissage
Après de nombreuses tentatives, voici la structure et les hyperparamètres qui ont permis à mon modèle de commencer à apprendre :
Architecture du réseau neuronal :
- Structure du QRNN
- Nombre de couches cachées : 2500
- Nombre de couches : 4
- Taille de l'image : 768
Une fois que votre modèle est capable de prédire correctement sur votre ensemble d'apprentissage, la prochaine chose que vous voulez éviter est le surajustement.
Voici quelques régularisations que j'ai essayées pour m'assurer que mon modèle ne serait pas surajouté.
- Ajouter l'abandon
- Ajouter la décroissance pondérale
- Ajouter un écrêtage de dégradé
Voici les régularisateurs que j'ai utilisés pour entraîner mon modèle :
- Taux d'apprentissage : 0.0002
- Décroissance du poids : 1e-8
- Écrêtage du dégradé : 0.25
Résultats
Après avoir entraîné mon modèle pendant 15 époques, j'ai finalement atteint une précision de 25% et une perplexité de 100. Comme je l'ai dit au début, je n'ai jamais eu l'intention d'utiliser mon modèle de langage pour générer du texte. Je suis donc déjà satisfait de savoir que mon modèle est capable de prédire correctement un mot sur 4.
J'ai ensuite réutilisé mon modèle pré-entraîné pour la classification de texte. L'ensemble dataset que j'ai utilisé est un ensemble dataset équilibré composé de 10k documents sociaux provenant d'Instagram, de Facebook, de Youtube et de sites web qui ont été étiquetés comme “label1” ou non “not label1”. Mon objectif était de prédire si une nouvelle publication concerne le “label1” ou non.
Voici les performances que j'obtiens pour toutes les langues que nous avons développées :
Image pour le poste
Performances des classificateurs de textes en différentes langues
Ainsi, même sans parler la langue et sans entraîner moi-même le modèle linguistique pré-entraîné, les performances du classificateur de texte coréen atteignent assez bien les performances des autres langues.
J'ai encore beaucoup de choses à essayer pour améliorer les performances que j'obtiens, mais c'était tout de même une sorte de grêle marie d'apprendre à traiter des documents d'une langue complexe comme le coréen sans en comprendre un mot et sans trouver d'informations et de conseils pertinents sur le web.
Prochaines étapes
Je viens de décrire comment j'ai pu améliorer un modèle de classification de texte coréen en tirant parti d'un modèle de langage simple créé de toutes pièces. Les performances initiales sont déjà bonnes, mais il est possible de les améliorer. Je pense que les points sur lesquels j'aimerais travailler à court terme sont les suivants :
- Relisez la tokenisation : comme je ne parle pas un mot de coréen, il serait intéressant qu'un Coréen de naissance examine la tokenisation et confirme qu'elle a du sens.
- Améliorez mon modèle linguistique et comparez les performances de classification :
- L'apprentissage par transfert d'un modèle linguistique rétrospectif, qui s'est avéré plus performant pour l'anglais ou le français.
- Apprentissage par transfert d'un modèle linguistique bidirectionnel.
- Avoir des taux d'apprentissage dynamiques pendant la formation pour éviter d'être bloqué dans un minimum local.

