


NOTICIAS / TECNOLOGÍA AI
25 de noviembre de 2020
En este artículo, Amale El Hamri, científico senior de Data en Artefact Francia, explica cómo entrenar un modelo lingüístico sin tener que entender la lengua usted mismo. El artículo incluye consejos sobre de dónde obtener data de entrenamiento, cuánto data necesita, cómo preprocesar su data y cómo encontrar una arquitectura y un conjunto de hiperparámetros que se adapten mejor a su modelo.
TLDR
Este artículo explica cómo creé mi propio modelo lingüístico hecho en coreano, un idioma complejo con un entrenamiento limitado data. Aquí podrá aprender a entrenar un modelo lingüístico sin tener el lujo de entender este idioma usted mismo. Encontrará consejos sobre de dónde obtener data de entrenamiento, cuánto data necesita, cómo preprocesar su data y cómo encontrar una arquitectura y un conjunto de hiperparámetros que se adapten mejor a su modelo.
Mis principales aprendizajes son:
Colección Data:
- Cuando la Wikipedia no tiene suficiente volumen o no es suficientemente utilizada por hablantes nativos de la lengua a partir de la cual quiere entrenar su modelo lingüístico, una buena opción es combinar la Wikipedia con otras fuentes data como CommonCrawl.
Volumen Data:
- Elija los documentos que mejor representen la lengua coreana. Demasiados documentos no serían útiles, ya que la mejora marginal del rendimiento sería demasiado pequeña en comparación con el enorme tiempo de entrenamiento.
- Elija documentos que contengan las palabras más utilizadas en lengua coreana.
- Encontrar una arquitectura que consiga modelizar la complejidad de la formación data.
- Encuentre la combinación adecuada de parámetros de regularización para no sobreajustar.
Introducción
Por si aún no lo sabe, la PNL ha experimentado un gran auge del aprendizaje por transferencia en estos dos últimos años. La idea principal es reutilizar modelos de lenguaje preentrenados para otra tarea de PNL, como la clasificación de textos. Un modelo de lenguaje es un modelo de aprendizaje profundo que, dada una parte de una frase, es capaz de predecir la siguiente palabra de la frase. La intuición que se desprende de esto es que este tipo de modelo entiende muy bien la estructura del lenguaje, la gramática, el vocabulario, y el objetivo es ‘transferir’ ese conocimiento a otros modelos posteriores.
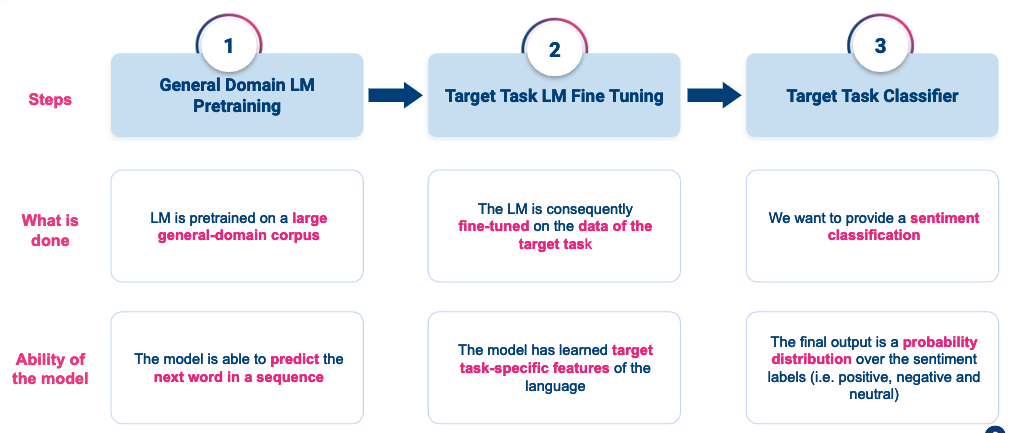
Ejemplo: una receta sencilla sobre cómo mejorar un clasificador de texto mediante el ajuste fino
Esta figura resume el método ULM Fit que utilicé para entrenar mi modelo lingüístico y así afinarlo y transferirlo a un clasificador de texto.
- Paso 1: Entrene un modelo lingüístico general sobre un corpus amplio de data en la lengua meta. Este modelo será capaz de comprender la estructura de la lengua, la gramática y el vocabulario principal.
- Paso 2: Ajuste el modelo lingüístico general a la clasificación de entrenamiento data. Al hacerlo, su modelo aprenderá mejor a representar el vocabulario que se utiliza en su corpus de entrenamiento.
- Paso 3: Entrene un clasificador de texto utilizando su modelo lingüístico preentrenado y afinado. Este método permite a su modelo comprender las palabras en su contexto. Además, el uso de un modelo lingüístico preentrenado le permite entrenar su clasificador con muy pocos ejemplos de entrenamiento (tan sólo 400 textos por etiqueta harían el trabajo).
Ya sabemos que la clasificación de textos funciona muy bien en inglés, francés, alemán, español, chino... pero ¿qué debemos hacer en lenguas con muy pocos modelos lingüísticos disponibles?
Antes de entrar en más detalles, quizá se pregunte por qué un científico data francés como yo querría tener un clasificador de texto en coreano. La razón es que formo parte de un proyecto que desarrolla un producto para clasificar las publicaciones de los medios sociales en diferentes categorías. Tras validar la metodología en inglés y francés, empezamos a escalarla a otros idiomas (inglés, francés, japonés, chino y coreano).
Sólo que el reto era mayor en coreano porque no se podía encontrar ningún modelo lingüístico preentrenado en código abierto, así que tuve que hacerlo yo mismo con muy pocos recursos lingüísticos coreanos.
Este artículo se centrará en la clasificación de textos coreanos mediante el método de ajuste múltiple que se explica a continuación papel.
Muchos idiomas están muy representados en la web como: Inglés, chino, español, portugués, francés... El coreano sigue estando muy poco documentado y no hay muchos contenidos listos para su reutilización. Así que pensé en contribuir compartiendo mis principales aprendizajes con ustedes, mientras descubría la PNL coreana.
En este artículo le contaré mi viaje para entrenar un modelo lingüístico coreano sin entender una sola palabra de coreano y cómo lo utilicé para la clasificación de textos.
Descargo de responsabilidad: Normalmente, consideramos que un modelo lingüístico es bueno cuando alcanza una precisión de alrededor de 45-50%. Como mi objetivo no es generar textos en coreano, no necesito alcanzar tales rendimientos: Sólo necesito un modelo que “entienda” la gramática y la estructura de la lengua coreana para poder utilizarlo para entrenar un clasificador de texto coreano.
1 - Colección Data para el entrenamiento del modelo lingüístico
1.1 - Fuente Data
Normalmente, cuando se entrena un modelo lingüístico desde cero, las sugerencias del tutorial de ULM FiT consisten en descargar todo el contenido de Wikipedia en el idioma en cuestión. Estas directrices sólo funcionan si los hablantes nativos de esta lengua están acostumbrados a publicar mucho en este canal.
En coreano, parece que la gente no está acostumbrada: no sólo el contexto coreano de Wikipedia no tiene suficiente volumen, sino que tampoco es representativo del habla coreana nativa.
He aquí una comparación entre el número de artículos de la Wikipedia en inglés y en coreano para dar algunas pistas:

Mi consejo: Combiné los artículos de Wikipedia con Common Crawl data que puede descargar de aquí.
1,2 - Data volumen
Recordemos que un modelo lingüístico es un modelo que debe predecir la siguiente palabra de un texto. Para ello, nuestro modelo debe haber visto muchos ejemplos para aprender la lengua y ser bueno hablándola. Dicho esto, no es útil ir más allá de 100 millones de tokens. Sólo añade complejidad a su modelo, así como un enorme tiempo de entrenamiento.
Así, a primera vista, una vez recuperados todos los documentos de Wikipedia y Common Crawl data, me encontré con mucho más de 100 millones de tokens, por lo que tuve que escoger los documentos más relevantes con los que entrenar mi modelo. El objetivo de mi metodología es quedarme con los documentos que representan de la mejor manera la lengua coreana nativa:
- Primero realicé una tokenización débil en mi corpus para aproximarme al número de tokens que tenía dividiendo el corpus en espacios.
- He eliminado todos los números, emojis, signos de puntuación y otros símbolos que no son específicos del coreano de mis fichas obtenidas.
- Calculé un contador de todas las fichas de mi corpus y recuperé las 70.000 fichas más mencionadas.
- A continuación, recuperé documentos que mencionan la mayoría de los tokens más utilizados, de tal forma que mi corpus estaría formado por 100 millones de tokens, ¡y ahí tenía mi corpus de entrenamiento!
Ahora que tenemos nuestro corpus bruto de formación, ¡podemos empezar a hacer negocios de verdad!
2 - Tokenización Data
Supongo que cuando le dije antes que había tokenizado con una función de división, empezó a pensar que este artículo era realmente una broma, pero vamos a tranquilizarle, ¡este nunca fue mi objetivo final!
En primer lugar, recordemos que para entrenar un modelo lingüístico no es necesario ningún otro preprocesamiento data. Muchas tareas de PNL eliminan del texto los números, las palabras vacías, las minúsculas, la raíz del texto... Todo ello despojaría al texto de su contexto y nuestro objetivo es aprender a hablar coreano, por lo que debemos mantener todo el texto tal y como fue escrito originalmente.
Para tokenizar el texto coreano probé dos modelos de tokenización:
- Modelo spacy coreano que es una envoltura del tokenizador coreano mecab.
- pieza de sentencia modelo tokenizador de subpalabras entrenado en mi corpus con 28000 tokens máximos
Como se recomienda en el artículo multifit, opté por la segunda opción para tener una granularidad de subpalabra.
3 - Modelo de formación
Al entrenar un modelo lingüístico, así como al entrenar cualquier modelo, las dos cosas que quiere evitar son subajuste y sobreajuste.
Un modelo under fits cuando es demasiado simple con respecto al data que intenta modelar. Puede detectarlo cuando vea que su modelo no puede aprender en su data de entrenamiento y que su pérdida de entrenamiento no converge a 0 en absoluto.
Por el contrario, un modelo sobre ajustes cuando aprende “demasiado bien” a modelar su data de entrenamiento pero ese rendimiento sigue siendo bajo en el data de prueba. Eso es señal de que su modelo no puede predecir bien data que no ha visto.
Cuando empecé a entrenar mi modelo lingüístico, al principio me costaba mucho aprender algo de mi data. Como puede ver en la imagen inferior, después de 10 epochs de entrenamiento mi pérdida de entrenamiento no disminuía ni un ápice.
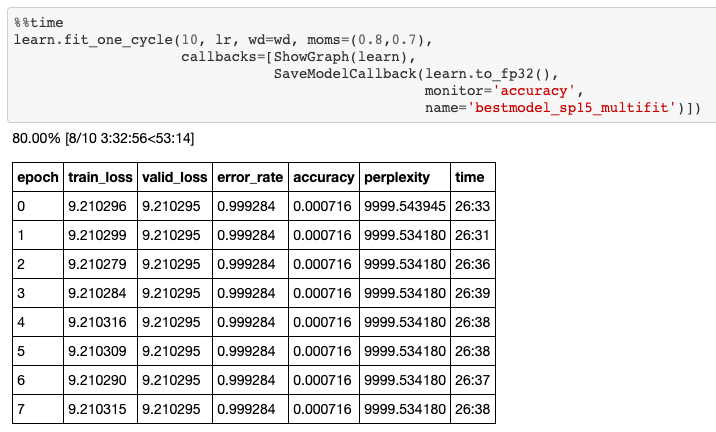
Lo que significa es que mi modelo era demasiado simple para representar la complejidad de la lengua coreana.
Esto es lo que hice para superar este problema:
Como puede imaginar, depurar cualquier modelo de aprendizaje profundo no es fácil, ya que existen muchos grados de libertad. Tiene que encontrar la estructura de red adecuada, así como el conjunto correcto de hiperparámetros.
Para simplificar el problema al principio, lo correcto es intentar sobreajustar un único lote de data. La idea aquí es asegurarse de que dado un cierto data, su modelo es capaz de interpretar su complejidad y rendir bien en el conjunto de entrenamiento.
Aquí están todas las cosas que probé :
- Aumentar el tamaño de la incrustación
- Aumentar el número de capas ocultas
- Cambio de las funciones del optimizador
- Cambiar el ritmo de aprendizaje
Tras muchos intentos, he aquí la estructura y los hiperparámetros que permitieron a mi modelo empezar a aprender :
Arquitectura de la red neuronal:
- Estructura de QRNN
- Número de capas ocultas: 2500
- Número de capas : 4
- Tamaño de incrustación : 768
Una vez que su modelo sea capaz de predecir correctamente en su conjunto de entrenamiento, lo siguiente que querrá evitar es el sobreajuste.
He aquí algunas regularizaciones que probé para asegurarme de que mi modelo no se ajustara en exceso.
- Añadir abandono
- Añadir decaimiento del peso
- Añadir recorte de degradado
Aquí están los regularizadores que utilicé para entrenar mi modelo:
- Tasa de aprendizaje: 0.0002
- Decaimiento del peso: 1e-8
- Recorte de degradado: 0.25
Resultados
Tras entrenar mi modelo durante 15 épocas, finalmente alcancé una precisión de 25% y una perplejidad de 100. Como dije al principio, nunca tuve la intención de utilizar mi modelo lingüístico para la generación de textos, así que ya estaba satisfecho de saber que mi modelo es capaz de predecir correctamente una de cada 4 palabras.
A continuación, volví a utilizar mi modelo preentrenado para la clasificación de texto. El dataset que utilicé es un dataset equilibrado compuesto por 10.000 documentos sociales procedentes de Instagram, Facebook, Youtube y sitios web etiquetados como “label1” o no “not label1”. Mi objetivo era predecir si una nueva publicación trata sobre “etiqueta1” o no.
Aquí están los rendimientos que obtengo para todas las lenguas que desarrollamos:
Imagen para el puesto
Rendimiento de los clasificadores de texto en diferentes idiomas
Así, incluso sin hablar el idioma ni entrenar yo mismo el modelo lingüístico preentrenado, los rendimientos del clasificador de texto coreano alcanzan bastante bien los rendimientos de otros idiomas.
Aún tengo muchas cosas que debería intentar para mejorar las prestaciones que obtengo pero, aún así, fue una especie de granizo mary aprender a procesar documentos de un idioma complejo como el coreano sin entender ni una palabra y sin encontrar información y consejos relevantes en la web.
Próximos pasos
Acabo de describir cómo podría mejorar un modelo de clasificación de texto coreano aprovechando un modelo lingüístico sencillo hecho desde cero. El rendimiento inicial ya es bueno, pero hay margen de mejora. Creo que en lo que me gustaría trabajar a corto plazo sería:
- Corregir la tokenización: como no hablo ni una palabra de coreano, sería interesante que un coreano nativo echara un vistazo a la tokenización y confirmara que tiene sentido.
- Mejore mi modelo lingüístico y compare los resultados de clasificación:
- Transferir-aprender un modelo lingüístico retrospectivo, ya que parecía tener más rendimiento en inglés o francés.
- Aprendizaje por transferencia de un modelo lingüístico bidireccional.
- Disponer de ritmos de aprendizaje dinámicos durante el entrenamiento para evitar quedarse atascado en un mínimo local.

