


NIEUWS / AI TECHNOLOGIE
25 november 2020
In dit artikel legt Amale El Hamri, Senior Data Scientist bij Artefact Frankrijk uit hoe u een taalmodel kunt trainen zonder zelf de taal te begrijpen. Het artikel bevat tips over waar u trainings data vandaan kunt halen, hoeveel data u nodig heeft, hoe u uw data kunt voorbewerken en hoe u een architectuur en een set hyperparameters kunt vinden die het beste bij uw model passen.
TLDR
In dit artikel wordt uitgelegd hoe ik zelf een taalmodel heb gemaakt in het Koreaans, een complexe taal met een beperkte data training. Hier kunt u leren hoe u een taalmodel kunt trainen zonder de luxe te hebben om deze taal zelf te begrijpen. U vindt tips over waar u trainings data vandaan kunt halen, hoeveel data u nodig hebt, hoe u uw data kunt voorbewerken en hoe u een architectuur en een set hyperparameters kunt vinden die het beste bij uw model passen.
Mijn belangrijkste learnings zijn:
Data collectie:
- Als Wikipedia niet genoeg volume heeft of niet genoeg gebruikt wordt door moedertaalsprekers van de taal waaruit u uw taalmodel wilt trainen, is het goed om Wikipedia te combineren met andere data bronnen zoals CommonCrawl.
Data volume:
- Kies documenten die het best de Koreaanse taal vertegenwoordigen. Te veel documenten zouden niet nuttig zijn omdat de marginale prestatieverbetering te klein zou zijn in vergelijking met de enorme trainingstijd.
- Kies documenten die de meest gebruikte woorden in de Koreaanse taal bevatten.
- Zoek een architectuur die de complexiteit van de training data kan modelleren.
- Vind de juiste combinatie van regularisatieparameters om overfit te voorkomen.
Inleiding
Als u het nog niet wist, NLP heeft de afgelopen twee jaar een enorme hype gehad op het gebied van transfer learning. Het belangrijkste idee is om vooraf getrainde taalmodellen te hergebruiken voor een andere NLP taak, zoals tekstclassificatie. Een taalmodel is een deep learning model dat, gegeven een deel van een zin, in staat is om het volgende woord van de zin te voorspellen. De intuïtie die u hieruit kunt afleiden is dat dit soort model de taalstructuur, grammatica en woordenschat heel goed begrijpt, en het doel is om die kennis ‘over te dragen’ aan andere downstream modellen.
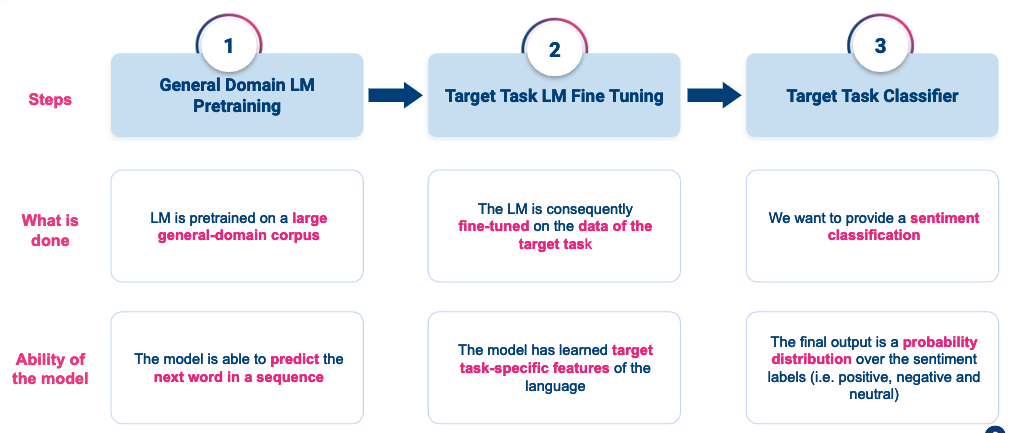
Voorbeeld: een eenvoudig recept voor het verbeteren van een tekstclassificator met behulp van fijnafstemming
Deze figuur vat de ULM Fit-methode samen die ik heb gebruikt om mijn taalmodel te trainen, te verfijnen en om te zetten in een tekstclassificator.
- Stap 1: Train een algemeen taalmodel op een groot corpus van data in de doeltaal. Dit model zal in staat zijn om de taalstructuur, grammatica en belangrijkste woordenschat te begrijpen.
- Stap 2: Verfijn het algemene taalmodel op de classificatietraining data. Hierdoor zal uw model beter leren om de woordenschat weer te geven die in uw trainingscorpus wordt gebruikt.
- Stap 3: Train een tekstclassificator met behulp van uw vooraf opgestelde taalmodel. Met deze methode kan uw model de woorden in hun context begrijpen. Bovendien kunt u met een voorgetraind taalmodel uw classifier trainen op zeer weinig trainingsvoorbeelden (slechts 400 teksten per label zijn voldoende).
We weten al dat tekstclassificatie goed werkt in het Engels, Frans, Duits, Spaans, Chinees... maar wat moeten we doen in talen met weinig kant-en-klare taalmodellen?
Voordat we verder op de details ingaan, vraagt u zich misschien af waarom een Franse data wetenschapper zoals ik een tekstclassificator in het Koreaans zou willen hebben? De reden is dat ik deel uitmaak van een project dat een product ontwikkelt om berichten op sociale media in verschillende categorieën in te delen. Na het valideren van de methodologie in het Engels en Frans, zijn we begonnen met het opschalen naar andere talen (Engels, Frans, Japans, Chinees en Koreaans).
Alleen was er een grotere uitdaging in de Koreaanse taal omdat er geen voorgetraind taalmodel te vinden was in open source, dus moest ik het zelf doen met zeer weinig Koreaanse taalkundige bronnen.
Dit artikel richt zich op Koreaanse tekstclassificatie met behulp van de multi-fit methode die in het volgende wordt uitgelegd papier.
Veel talen zijn goed vertegenwoordigd op het web, zoals: Engels, Chinees, Spaans, Portugees, Frans... De Koreaanse taal blijft erg slecht gedocumenteerd en er is niet veel inhoud klaar voor hergebruik. Dus dacht ik erover om zelf een bijdrage te leveren door mijn belangrijkste lessen met u te delen, terwijl ik Koreaanse NLP aan het ontdekken was.
In dit artikel vertel ik u over mijn reis om een Koreaans taalmodel te trainen zonder ook maar één woord Koreaans te verstaan en hoe ik het heb gebruikt voor tekstclassificatie.
Disclaimer: Gewoonlijk beschouwen we een taalmodel als goed wanneer het een nauwkeurigheid van ongeveer 45-50% haalt. Aangezien het niet mijn doel is om Koreaanse tekst te genereren, hoef ik zulke prestaties niet te behalen: Ik heb alleen een model nodig dat de grammatica en structuur van de Koreaanse taal “begrijpt”, zodat ik het kan gebruiken om een Koreaanse tekstclassificator te trainen.
1 - Data collectie voor taalmodeltraining
1.1 - Data bron
Als u een taalmodel vanaf nul wilt trainen, stelt de ULM FiT handleiding meestal voor om alle Wikipedia-inhoud in de gegeven taal te downloaden. Deze richtlijnen werken alleen als moedertaalsprekers van deze taal gewend zijn om veel op dit kanaal te publiceren.
In het Koreaans blijkt dat mensen er niet aan gewend zijn: niet alleen heeft Wikipedia Koreaanse context niet genoeg volume, en het is ook niet representatief voor moedertaalsprekers in het Koreaans.
Hier is een vergelijking tussen het aantal artikelen in de Engelse en Koreaanse Wikipedia om enkele hints te geven:

Mijn advies: Ik heb Wikipedia artikelen gecombineerd met Common Crawl data die u kunt downloaden van hier.
1.2 - Data volume
Laten we niet vergeten dat een taalmodel een model is dat het volgende woord in een tekst moet voorspellen. Om dat te kunnen, moet ons model veel voorbeelden gezien hebben om de taal te leren en goed te kunnen spreken. Dat gezegd hebbende, is het niet nuttig om verder te gaan dan 100 miljoen tokens. Het voegt alleen maar complexiteit toe aan uw model, evenals een enorme trainingstijd.
Dus op het eerste gezicht, nadat ik alle Wikipedia en Common Crawl data had opgehaald, zat ik met veel meer dan 100 miljoen tokens, dus ik moest de meest relevante documenten uitkiezen om mijn model mee te trainen. Het doel van mijn methodologie is om de documenten te behouden die de Koreaanse taal het beste vertegenwoordigen:
- Ik heb eerst een zwakke tokenisatie uitgevoerd op mijn corpus om het aantal tokens dat ik had te benaderen door het corpus op te splitsen op spaties.
- Ik heb alle getallen, emoji's, leestekens en andere symbolen die niet specifiek zijn voor Koreaans uit mijn verkregen tokens verwijderd.
- Ik heb een teller berekend van alle tokens in mijn corpus en de top 70.000 vermelde tokens opgehaald.
- Vervolgens heb ik documenten opgehaald waarin de meeste van de meest gebruikte tokens worden genoemd, zodat mijn corpus uit 100 miljoen tokens zou bestaan en daar was mijn trainingscorpus!
Nu we ons ruwe corpus van trainingen hebben, kunnen we echt zaken gaan doen!
2 - Data tokenisatie
Ik denk dat toen ik u eerder vertelde dat ik tokeniseerde met een splitfunctie, u begon te denken dat dit artikel echt een grap was, maar laten we u geruststellen, dit was nooit mijn eindspel!
Laten we u er eerst aan herinneren dat er geen verdere data voorbewerking nodig is voor het trainen van een taalmodel. Veel NLP-taken strippen tekst van nummers, stopwoorden, kleine letters, stammen ... Al deze dingen zouden uw tekst uit zijn context halen en ons doel is om Koreaans te leren spreken, dus we moeten al onze tekst houden zoals hij oorspronkelijk geschreven is.
Om Koreaanse tekst te tokenen heb ik twee tokenisatiemodellen geprobeerd:
- Koreaans spacy model die een wrapper is voor de Koreaanse mecab tokenizer.
- zinnestuk subwoorden tokenizer model getraind op mijn corpus met 28000 maximale tokens
Zoals aanbevolen in de multifit artikel, Ik koos voor de tweede optie om een granulariteit van subwoorden te hebben.
3 - Opleidingsmodel
Bij het trainen van een taalmodel, net als bij het trainen van elk ander model, zijn de twee dingen die u wilt vermijden onderfitting en overpassen.
Een model onder past wanneer het te eenvoudig is met betrekking tot de data die het probeert te modelleren. U kunt dit detecteren wanneer u merkt dat uw model niet kan leren op uw trainings data en dat uw trainingsverlies helemaal niet convergeert naar 0.
Aan de andere kant is een model over past wanneer het “te goed” leert om uw training data te modelleren, maar die prestatie laag blijft op de test data. Dat is een teken dat uw model waarschijnlijk niet goed data kan voorspellen die het nog niet heeft gezien.
Toen ik begon met het trainen van mijn taalmodel, had ik in het begin echt moeite om iets te leren van mijn data. Zoals u op de afbeelding hieronder kunt zien, werd mijn trainingsverlies na 10 epochs training nog geen centimeter kleiner.
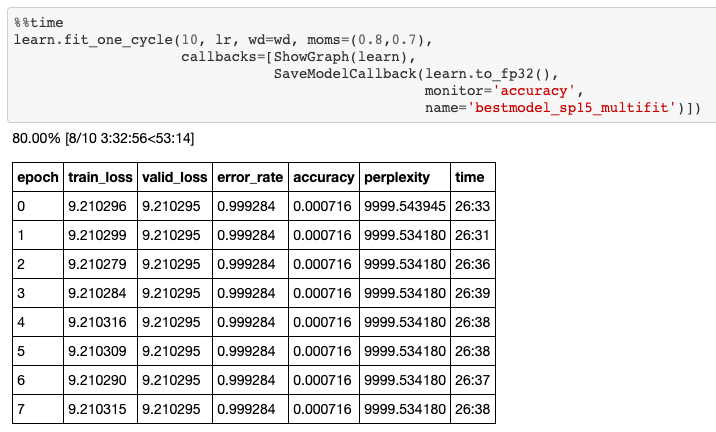
Dit betekent dat mijn model te eenvoudig was om de complexiteit van de Koreaanse taal weer te geven.
Dit is wat ik heb gedaan om dit probleem op te lossen:
Zoals u zich kunt voorstellen, is het debuggen van elk deep learning-model niet eenvoudig, omdat er zoveel vrijheidsgraden zijn. U moet de juiste netwerkstructuur en de juiste set hyperparameters vinden.
Om het probleem in het begin te vereenvoudigen, is de juiste manier om te proberen te overfiten op een enkele batch van data. Het idee hier is om ervoor te zorgen dat uw model, gegeven data, in staat is om de complexiteit ervan te interpreteren en goed te presteren op de trainingsset.
Hier zijn alle dingen die ik heb geprobeerd:
- Embedding vergroten
- Aantal verborgen lagen verhogen
- Optimalisatorfuncties wijzigen
- Veranderende leersnelheid
Na veel pogingen zijn hier de structuur en hyperparameters waarmee mijn model kon beginnen met leren:
Neurale netwerkarchitectuur:
- QRNN Structuur
- Aantal verborgen lagen: 2500
- Aantal lagen : 4
- Insluitingsgrootte : 768
Zodra uw model in staat is om correct te voorspellen op uw trainingsset, is het volgende dat u wilt vermijden overfitting.
Hier zijn enkele regularisaties die ik heb geprobeerd om ervoor te zorgen dat mijn model niet te veel zou passen.
- Uitval toevoegen
- Gewichtsverval toevoegen
- Kleurverloop knippen toevoegen
Hier zijn de regularizers die ik heb gebruikt om mijn model te trainen:
- Leertempo: 0.0002
- Gewichtsverval: 1e-8
- Kleurverloop knippen: 0.25
Resultaten
Na het trainen van mijn model gedurende 15 epochs, bereikte ik uiteindelijk een nauwkeurigheid van 25% en een perplexiteit van 100. Zoals ik in het begin al zei, was ik nooit van plan om mijn taalmodel te gebruiken voor het genereren van tekst, dus ik was al tevreden toen ik wist dat mijn model in staat was om één op de vier woorden correct te voorspellen.
Daarna heb ik mijn voorgetrainde model opnieuw gebruikt voor tekstclassificatie. De dataset die ik gebruikte is een gebalanceerde dataset van 10k sociale documenten afkomstig van Instagram, Facebook, Youtube en websites die gelabeld waren als “label1” of niet “not label1”. Mijn doel was om te voorspellen of een nieuwe publicatie over “label1” gaat of niet.
Hier zijn de prestaties die ik krijg voor alle talen die we hebben ontwikkeld:
Afbeelding voor post
Prestaties van tekstclassificeerders voor verschillende talen
Dus zelfs zonder de taal te spreken en het voorgetrainde taalmodel zelf te trainen, halen de prestaties voor de Koreaanse tekstclassificator vrij goed de prestaties van de andere talen.
Ik heb nog steeds veel dingen die ik moet proberen om de prestaties die ik krijg te verbeteren, maar toch was het een soort hagelschot om documenten van een complexe taal als Koreaans te leren verwerken zonder er een woord van te begrijpen en zonder relevante informatie en advies op het web te vinden.
Volgende stappen
Ik heb zojuist beschreven hoe ik een Koreaans tekstclassificatiemodel kon verbeteren door gebruik te maken van een eenvoudig taalmodel dat vanaf nul is gemaakt. De aanvankelijke prestaties zijn al goed, maar er is ruimte voor verbetering. Ik denk dat ik op korte termijn zou willen werken aan het volgende:
- Proeflezen van de tokenisering: aangezien ik geen woord Koreaans spreek, zou het interessant zijn om een Koreaanse moedertaalspreker naar de tokenisering te laten kijken en te laten bevestigen dat het zinvol is.
- Mijn taalmodel verbeteren en classificatieprestaties vergelijken door:
- Transfer-learning van een achterwaarts taalmodel, omdat dit beter leek te presteren op Engels of Frans.
- Transfer-leren van een bidirectioneel taalmodel.
- Dynamische leersnelheden tijdens de training om te voorkomen dat u vast komt te zitten in een lokaal minimum.

