


新闻 / 人工智能技术
2020 年 11 月 25 日
在本文中,法国 Artefact 高级 Data 科学家 Amale El Hamri 介绍了如何在不理解语言的情况下训练语言模型。文章内容包括从哪里获取训练 data、需要多少 data、如何预处理 data,以及如何找到最适合模型的架构和超参数集。.
TLDR
本文介绍了我如何用韩语创建自己的语言模型,韩语是一种复杂的语言,训练 data 有限。在这里,您可以学习如何在自己不懂这种语言的情况下训练语言模型。您将了解到从哪里获取训练 data、需要多少 data、如何预处理 data,以及如何找到最适合您的模型的架构和超参数集。.
我的主要体会是
Data 系列:
- 如果维基百科的容量不够大,或者您想要训练语言模型的语言的母语使用者对维基百科的使用不够多,那么您可以将维基百科与其他 data 资源(如 CommonCrawl)结合起来。.
Data 音量:
- 选择最能代表韩语的文档。过多的文档并没有用处,因为与巨大的训练时间相比,边际性能提升太小。.
- 选择包含韩语常用词的文件。.
- 找到一种能将 data 培训的复杂性模型化的结构。.
- 找到正则化参数的正确组合,避免过拟合。.
导言
如果你还不知道,NLP 在过去两年里大肆炒作迁移学习。其主要思想是将预先训练好的语言模型重新用于另一项 NLP 任务,如文本分类。语言模型是一种深度学习模型,给定句子的一部分就能预测句子的下一个单词。从直观上理解,这种模型能够很好地理解语言结构、语法和词汇,其目标是将这些知识 ‘转移 ’给其他下游模型。.
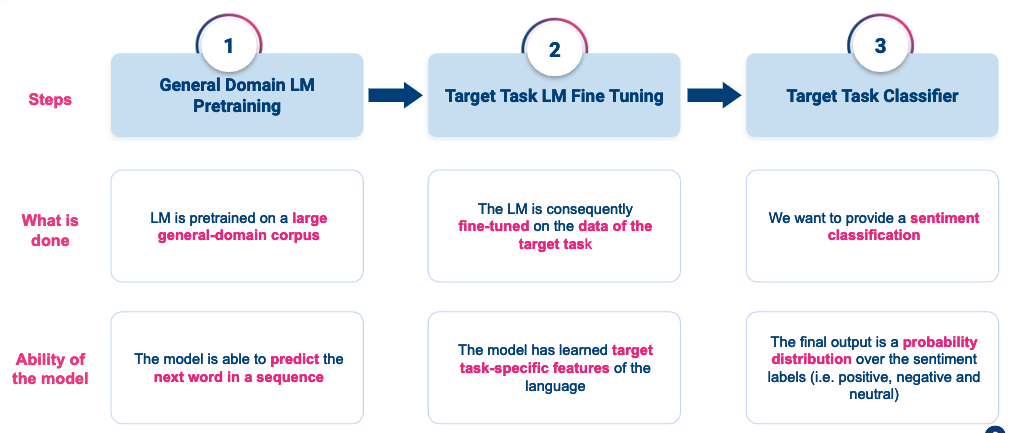
示例:如何利用微调改进文本分类器的简单方法
该图总结了我用来训练语言模型的 ULM Fit 方法,从而对其进行微调并将其转换为文本分类器。.
- 步骤 1:在大量目标语言 data 语料库上训练通用语言模型。该模型将能够理解语言结构、语法和主要词汇。.
- 第 2 步:根据分类训练 data 微调通用语言模型。这样,您的模型就能更好地学习如何表现训练语料中使用的词汇。.
- 第 3 步:使用经过微调的预训练语言模型训练文本分类器。这种方法可以让模型在上下文中理解单词。此外,使用预训练的语言模型,您可以在极少的训练示例上训练分类器(每个标签只需训练 400 个文本即可)。.
我们已经知道,文本分类在英语、法语、德语、西班牙语、中文等语言中都能很好地发挥作用,但对于那些现成语言模型很少的语言,我们该怎么办呢?
在了解更多细节之前,您可能想知道为什么像我这样的法国 data 科学家会想要一个韩语文本分类器?原因是我参与了一个项目,该项目开发了一种将社交媒体帖子分为不同类别的产品。在对英语和法语的方法论进行验证后,我们开始将其扩展到其他语言(英语、法语、日语、中文和韩语)。.
只有韩语面临更大的挑战,因为在开放源代码中找不到预训练的语言模型,所以我不得不在韩语语言资源极少的情况下自己动手。.
本文将重点介绍使用多重拟合法对韩文文本进行分类的方法,具体说明如下 纸张.
很多语言在网络中都有很强的代表性,例如:英语、中文、西班牙语、葡萄牙语、法语......韩语的记录仍然非常少,而且没有很多内容可以重复使用:韩语的记录仍然非常少,也没有很多内容可以重复使用。因此,我想贡献自己的力量,与大家分享我在探索韩语 NLP 过程中的主要心得。.
在本文中,我将向大家讲述我在不懂一个韩语单词的情况下训练韩语模型的历程,以及如何将其用于文本分类。.
免责声明 通常,当一个语言模型的准确率达到 45-50% 左右时,我们就认为这个模型很好。由于我的目标不是生成韩文文本,所以我不需要达到这样的性能:我只需要一个能 “理解 ”韩语语法和结构的模型,这样我就可以用它来训练韩语文本分类器。.
1 - 用于语言模型训练的 Data 数据集
1.1 - Data 信号源
通常,在从头开始训练语言模型时,ULM FiT 教程建议下载给定语言的所有维基百科内容。只有在该语言的母语使用者习惯于在该频道发布大量内容的情况下,这些建议才会有效。.
在韩语中,人们似乎并不习惯:不仅维基百科韩语语境的音量不够,而且也不能代表以韩语为母语的人。.
下面是英文维基百科和韩文维基百科的文章数量对比,以提供一些提示:

我的建议我将维基百科文章与 Common Crawl data 结合在一起,您可以从以下网址下载 这里.
1.2 - Data 体积
让我们记住,语言模型是一个可以预测文本中下一个单词的模型。要做到这一点,我们的模型应该看过大量的例子来学习语言,并擅长说这种语言。也就是说,超过 1 亿个词库是没有用的。这只会增加模型的复杂性和大量的训练时间。.
因此,乍一看,当我检索了所有维基百科和 Common Crawl data 后,我发现自己拥有了超过 1 亿个标记,因此我必须挑选最相关的文档来训练我的模型。我的方法的目标是保留最能代表韩语母语的文档:
- 我首先对语料库进行了弱标记化处理,通过分割语料库的空格来估算标记的数量。.
- 我从获得的代币中删除了所有数字、表情符号、标点符号和其他非韩语特有的符号。.
- 我计算了语料库中所有标记的计数器,并检索了提及次数最多的 7 万个标记。.
- 然后,我检索了提到大多数常用标记的文档,这样我的语料库就包含了 1 亿个标记,这就是我的训练语料库!
现在,我们有了培训的原始资料库,就可以开始真正的业务了!
2 - Data 标记化
我想,当我之前告诉你我用拆分函数进行了标记化处理时,你会开始觉得这篇文章真的是个笑话,但让我们向你保证,这绝不是我的最终目的!
首先要提醒大家的是,训练语言模型不需要进一步的 data 预处理。很多 NLP 任务都会对文本进行一些剥离处理,如数字、单词、小写、词干......所有这些都会将文本从上下文中剥离出来,而我们的目标是学习说韩语,因此我们必须保持所有文本的原貌。.
为了标记韩语文本,我尝试了两种标记模型:
正如 多功能文章, 因此,我选择了第二种方案,以获得子字粒度。.
3 - 培训模式
在训练语言模型和训练任何模型时,都要避免以下两点 欠妥 和 过度拟合。.
一个模型 不适合 当它试图模拟的 data 过于简单时。如果您发现模型无法在训练 data 上学习,而且训练损失完全没有收敛到 0,您就可以发现这一点。.
相反,一个模型 超过适合 当它学习得 “太好”,可以对训练 data 进行建模,但在测试 data 上的性能仍然很低时。这表明您的模型不可能很好地预测它未见过的 data。.
当我开始训练我的语言模型时,一开始我真的很难从我的 data 上学到任何东西。如下图所示,经过 10 个历元的训练后,我的训练损失寸步难行。.
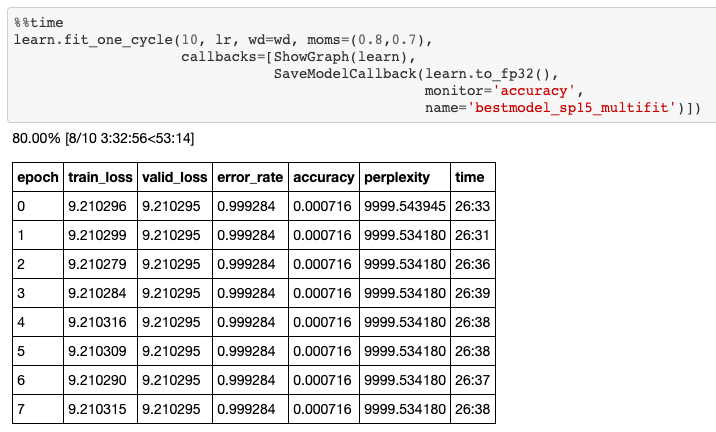
这说明我的模型过于简单,无法表现韩语的复杂性。.
我是这样解决这个问题的:
可以想象,调试任何深度学习模型都不是一件容易的事,因为其中有太多的自由度。你必须找到正确的网络结构以及正确的超参数集。.
为了在一开始就简化问题,正确的方法是尝试对单批 data 进行超拟合。这样做的目的是确保在给定某个 data 的情况下,您的模型能够解释其复杂性,并在训练集上表现良好。.
以下是我尝试过的所有方法:
- 增大嵌入尺寸
- 增加隐藏层数
- 更改优化器功能
- 改变学习速度
经过多次尝试,以下是让我的模型开始学习的结构和超参数:
神经网络架构
- QRNN 结构
- 隐藏层数: 2500
- 层数:4
- 嵌入尺寸:768
一旦模型能够在训练集上正确预测,接下来要避免的就是过度拟合。.
以下是我尝试的一些正则化方法,以确保我的模型不会过拟合。.
- 添加辍学
- 增加重量衰减
- 添加渐变剪切
以下是我在训练模型时使用的正则表达式:
- 学习率0.0002
- 重量衰减1e-8
- 渐变剪切0.25
成果
在对模型进行了 15 次历时训练后,我最终获得了 25% 的准确率和 100 的困惑度。正如我在一开始所说的,我从未打算用我的语言模型来生成文本,所以我已经很满意我的模型能够正确预测 4 个单词中的 1 个。.
然后,我将预先训练好的模型重新用于文本分类。我使用的 dataset 是一个平衡的 dataset,由来自 Instagram、Facebook、Youtube 和网站的 10k 篇社交文档组成,这些文档被标记为 “label1 ”或非 “not label1”。我的目标是预测新出版物是否与 “label1 ”有关。.
以下是我们开发的所有语言的性能:
帖子图片
不同语言文本分类器的性能
因此,即使不说韩语,不亲自训练预训练的语言模型,韩语文本分类器的性能也能很好地达到其他语言的性能。.
虽然我还有很多地方需要改进,但在完全不懂韩语的情况下,在网上找不到相关信息和建议的情况下,学习处理韩语这种复杂语言的文件,还是让我受宠若惊。.
下一步工作
我刚才介绍了如何利用从零开始建立的简单语言模型来改进韩语文本分类模型。最初的性能已经不错,但还有改进的余地。我认为短期内我想做的工作是:
- 校对标记化:由于我一句韩语都不会说,所以请一位以韩语为母语的人看一下标记化,确认是否合理。.
- 通过以下方法增强我的语言模型并比较分类性能:
- 迁移学习后向语言模型,因为它在英语或法语中似乎表现更佳。.
- 双向语言模型的迁移学习.
- 在训练过程中采用动态学习率,避免陷入局部最小值。.


